first commit
32
.gitignore
vendored
Normal file
@@ -0,0 +1,32 @@
|
|||||||
|
# .gitignore
|
||||||
|
# 首先忽略所有的文件
|
||||||
|
*
|
||||||
|
# 但是不忽略目录
|
||||||
|
!*/
|
||||||
|
# 忽略一些指定的目录名
|
||||||
|
ut/
|
||||||
|
runs/
|
||||||
|
.vscode/
|
||||||
|
build/
|
||||||
|
result/
|
||||||
|
*.pyc
|
||||||
|
pretrained_model/
|
||||||
|
# 不忽略下面指定的文件类型
|
||||||
|
!*.cpp
|
||||||
|
!*.h
|
||||||
|
!*.hpp
|
||||||
|
!*.c
|
||||||
|
!.gitignore
|
||||||
|
!*.py
|
||||||
|
!*.sh
|
||||||
|
!*.npy
|
||||||
|
!*.jpg
|
||||||
|
!*.pt
|
||||||
|
!*.npy
|
||||||
|
!*.pth
|
||||||
|
!*.png
|
||||||
|
!*.md
|
||||||
|
!*.txt
|
||||||
|
!*.yaml
|
||||||
|
!*.ttf
|
||||||
|
!*.cu
|
||||||
115
CONTRIBUTING.md
Normal file
@@ -0,0 +1,115 @@
|
|||||||
|
## Contributing to YOLOv8 🚀
|
||||||
|
|
||||||
|
We love your input! We want to make contributing to YOLOv8 as easy and transparent as possible, whether it's:
|
||||||
|
|
||||||
|
- Reporting a bug
|
||||||
|
- Discussing the current state of the code
|
||||||
|
- Submitting a fix
|
||||||
|
- Proposing a new feature
|
||||||
|
- Becoming a maintainer
|
||||||
|
|
||||||
|
YOLOv8 works so well due to our combined community effort, and for every small improvement you contribute you will be
|
||||||
|
helping push the frontiers of what's possible in AI 😃!
|
||||||
|
|
||||||
|
## Submitting a Pull Request (PR) 🛠️
|
||||||
|
|
||||||
|
Submitting a PR is easy! This example shows how to submit a PR for updating `requirements.txt` in 4 steps:
|
||||||
|
|
||||||
|
### 1. Select File to Update
|
||||||
|
|
||||||
|
Select `requirements.txt` to update by clicking on it in GitHub.
|
||||||
|
|
||||||
|
<p align="center"><img width="800" alt="PR_step1" src="https://user-images.githubusercontent.com/26833433/122260847-08be2600-ced4-11eb-828b-8287ace4136c.png"></p>
|
||||||
|
|
||||||
|
### 2. Click 'Edit this file'
|
||||||
|
|
||||||
|
Button is in top-right corner.
|
||||||
|
|
||||||
|
<p align="center"><img width="800" alt="PR_step2" src="https://user-images.githubusercontent.com/26833433/122260844-06f46280-ced4-11eb-9eec-b8a24be519ca.png"></p>
|
||||||
|
|
||||||
|
### 3. Make Changes
|
||||||
|
|
||||||
|
Change `matplotlib` version from `3.2.2` to `3.3`.
|
||||||
|
|
||||||
|
<p align="center"><img width="800" alt="PR_step3" src="https://user-images.githubusercontent.com/26833433/122260853-0a87e980-ced4-11eb-9fd2-3650fb6e0842.png"></p>
|
||||||
|
|
||||||
|
### 4. Preview Changes and Submit PR
|
||||||
|
|
||||||
|
Click on the **Preview changes** tab to verify your updates. At the bottom of the screen select 'Create a **new branch**
|
||||||
|
for this commit', assign your branch a descriptive name such as `fix/matplotlib_version` and click the green **Propose
|
||||||
|
changes** button. All done, your PR is now submitted to YOLOv8 for review and approval 😃!
|
||||||
|
|
||||||
|
<p align="center"><img width="800" alt="PR_step4" src="https://user-images.githubusercontent.com/26833433/122260856-0b208000-ced4-11eb-8e8e-77b6151cbcc3.png"></p>
|
||||||
|
|
||||||
|
### PR recommendations
|
||||||
|
|
||||||
|
To allow your work to be integrated as seamlessly as possible, we advise you to:
|
||||||
|
|
||||||
|
- ✅ Verify your PR is **up-to-date** with `ultralytics/ultralytics` `main` branch. If your PR is behind you can update
|
||||||
|
your code by clicking the 'Update branch' button or by running `git pull` and `git merge main` locally.
|
||||||
|
|
||||||
|
<p align="center"><img width="751" alt="Screenshot 2022-08-29 at 22 47 15" src="https://user-images.githubusercontent.com/26833433/187295893-50ed9f44-b2c9-4138-a614-de69bd1753d7.png"></p>
|
||||||
|
|
||||||
|
- ✅ Verify all YOLOv8 Continuous Integration (CI) **checks are passing**.
|
||||||
|
|
||||||
|
<p align="center"><img width="751" alt="Screenshot 2022-08-29 at 22 47 03" src="https://user-images.githubusercontent.com/26833433/187296922-545c5498-f64a-4d8c-8300-5fa764360da6.png"></p>
|
||||||
|
|
||||||
|
- ✅ Reduce changes to the absolute **minimum** required for your bug fix or feature addition. _"It is not daily increase
|
||||||
|
but daily decrease, hack away the unessential. The closer to the source, the less wastage there is."_ — Bruce Lee
|
||||||
|
|
||||||
|
### Docstrings
|
||||||
|
|
||||||
|
Not all functions or classes require docstrings but when they do, we
|
||||||
|
follow [google-style docstrings format](https://google.github.io/styleguide/pyguide.html#38-comments-and-docstrings).
|
||||||
|
Here is an example:
|
||||||
|
|
||||||
|
```python
|
||||||
|
"""
|
||||||
|
What the function does. Performs NMS on given detection predictions.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
arg1: The description of the 1st argument
|
||||||
|
arg2: The description of the 2nd argument
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
What the function returns. Empty if nothing is returned.
|
||||||
|
|
||||||
|
Raises:
|
||||||
|
Exception Class: When and why this exception can be raised by the function.
|
||||||
|
"""
|
||||||
|
```
|
||||||
|
|
||||||
|
## Submitting a Bug Report 🐛
|
||||||
|
|
||||||
|
If you spot a problem with YOLOv8 please submit a Bug Report!
|
||||||
|
|
||||||
|
For us to start investigating a possible problem we need to be able to reproduce it ourselves first. We've created a few
|
||||||
|
short guidelines below to help users provide what we need in order to get started.
|
||||||
|
|
||||||
|
When asking a question, people will be better able to provide help if you provide **code** that they can easily
|
||||||
|
understand and use to **reproduce** the problem. This is referred to by community members as creating
|
||||||
|
a [minimum reproducible example](https://stackoverflow.com/help/minimal-reproducible-example). Your code that reproduces
|
||||||
|
the problem should be:
|
||||||
|
|
||||||
|
- ✅ **Minimal** – Use as little code as possible that still produces the same problem
|
||||||
|
- ✅ **Complete** – Provide **all** parts someone else needs to reproduce your problem in the question itself
|
||||||
|
- ✅ **Reproducible** – Test the code you're about to provide to make sure it reproduces the problem
|
||||||
|
|
||||||
|
In addition to the above requirements, for [Ultralytics](https://ultralytics.com/) to provide assistance your code
|
||||||
|
should be:
|
||||||
|
|
||||||
|
- ✅ **Current** – Verify that your code is up-to-date with current
|
||||||
|
GitHub [main](https://github.com/ultralytics/ultralytics/tree/main) branch, and if necessary `git pull` or `git clone`
|
||||||
|
a new copy to ensure your problem has not already been resolved by previous commits.
|
||||||
|
- ✅ **Unmodified** – Your problem must be reproducible without any modifications to the codebase in this
|
||||||
|
repository. [Ultralytics](https://ultralytics.com/) does not provide support for custom code ⚠️.
|
||||||
|
|
||||||
|
If you believe your problem meets all of the above criteria, please close this issue and raise a new one using the 🐛
|
||||||
|
**Bug Report** [template](https://github.com/ultralytics/ultralytics/issues/new/choose) and providing
|
||||||
|
a [minimum reproducible example](https://stackoverflow.com/help/minimal-reproducible-example) to help us better
|
||||||
|
understand and diagnose your problem.
|
||||||
|
|
||||||
|
## License
|
||||||
|
|
||||||
|
By contributing, you agree that your contributions will be licensed under
|
||||||
|
the [GPL-3.0 license](https://choosealicense.com/licenses/gpl-3.0/)
|
||||||
49
README.md
Normal file
@@ -0,0 +1,49 @@
|
|||||||
|
## **yolov8车牌识别算法,支持12种中文车牌类型**
|
||||||
|
|
||||||
|
**环境要求: python >=3.6 pytorch >=1.7 pip install requirements.txt**
|
||||||
|
|
||||||
|
#### **图片测试demo:**
|
||||||
|
|
||||||
|
直接运行detect_plate.py 或者运行如下命令行:
|
||||||
|
|
||||||
|
```
|
||||||
|
python detect_rec_plate.py --detect_model weights/yolov8-lite-t-plate.pt --rec_model weights/plate_rec_color.pth --image_path imgs --output result
|
||||||
|
```
|
||||||
|
|
||||||
|
测试文件夹imgs,结果保存再 result 文件夹中
|
||||||
|
|
||||||
|
## **车牌检测训练**
|
||||||
|
|
||||||
|
车牌检测训练链接如下:
|
||||||
|
|
||||||
|
[车牌检测训练](https://github.com/we0091234/Chinese_license_plate_detection_recognition/tree/main/readme)
|
||||||
|
|
||||||
|
## **车牌识别训练**
|
||||||
|
|
||||||
|
车牌识别训练链接如下:
|
||||||
|
|
||||||
|
[车牌识别训练](https://github.com/we0091234/crnn_plate_recognition)
|
||||||
|
|
||||||
|
#### **支持如下:**
|
||||||
|
|
||||||
|
- [X] 1.单行蓝牌
|
||||||
|
- [X] 2.单行黄牌
|
||||||
|
- [X] 3.新能源车牌
|
||||||
|
- [X] 4.白色警用车牌
|
||||||
|
- [X] 5.教练车牌
|
||||||
|
- [X] 6.武警车牌
|
||||||
|
- [X] 7.双层黄牌
|
||||||
|
- [X] 8.双层白牌
|
||||||
|
- [X] 9.使馆车牌
|
||||||
|
- [X] 10.港澳粤Z牌
|
||||||
|
- [X] 11.双层绿牌
|
||||||
|
- [X] 12.民航车牌
|
||||||
|
|
||||||
|
## References
|
||||||
|
|
||||||
|
* [https://github.com/derronqi/yolov8-face](https://github.com/derronqi/yolov8-face)
|
||||||
|
* [https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics)
|
||||||
|
|
||||||
|
## 联系
|
||||||
|
|
||||||
|
**有问题可以提issues 或者加qq群:871797331 询问**
|
||||||
BIN
data/test.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.3 MiB |
42934
data/widerface/val/label.txt
Normal file
3226
data/widerface/val/wider_val.txt
Normal file
246
detect_rec_plate.py
Normal file
@@ -0,0 +1,246 @@
|
|||||||
|
import torch
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
import argparse
|
||||||
|
import copy
|
||||||
|
import time
|
||||||
|
import os
|
||||||
|
from ultralytics.nn.tasks import attempt_load_weights
|
||||||
|
from plate_recognition.plate_rec import get_plate_result,init_model,cv_imread
|
||||||
|
from plate_recognition.double_plate_split_merge import get_split_merge
|
||||||
|
from fonts.cv_puttext import cv2ImgAddText
|
||||||
|
|
||||||
|
def allFilePath(rootPath,allFIleList):# 读取文件夹内的文件,放到list
|
||||||
|
fileList = os.listdir(rootPath)
|
||||||
|
for temp in fileList:
|
||||||
|
if os.path.isfile(os.path.join(rootPath,temp)):
|
||||||
|
allFIleList.append(os.path.join(rootPath,temp))
|
||||||
|
else:
|
||||||
|
allFilePath(os.path.join(rootPath,temp),allFIleList)
|
||||||
|
|
||||||
|
def four_point_transform(image, pts): #透视变换得到车牌小图
|
||||||
|
# rect = order_points(pts)
|
||||||
|
rect = pts.astype('float32')
|
||||||
|
(tl, tr, br, bl) = rect
|
||||||
|
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
|
||||||
|
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
|
||||||
|
maxWidth = max(int(widthA), int(widthB))
|
||||||
|
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
|
||||||
|
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
|
||||||
|
maxHeight = max(int(heightA), int(heightB))
|
||||||
|
dst = np.array([
|
||||||
|
[0, 0],
|
||||||
|
[maxWidth - 1, 0],
|
||||||
|
[maxWidth - 1, maxHeight - 1],
|
||||||
|
[0, maxHeight - 1]], dtype = "float32")
|
||||||
|
M = cv2.getPerspectiveTransform(rect, dst)
|
||||||
|
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
|
||||||
|
return warped
|
||||||
|
|
||||||
|
|
||||||
|
def letter_box(img,size=(640,640)): #yolo 前处理 letter_box操作
|
||||||
|
h,w,_=img.shape
|
||||||
|
r=min(size[0]/h,size[1]/w)
|
||||||
|
new_h,new_w=int(h*r),int(w*r)
|
||||||
|
new_img = cv2.resize(img,(new_w,new_h))
|
||||||
|
left= int((size[1]-new_w)/2)
|
||||||
|
top=int((size[0]-new_h)/2)
|
||||||
|
right = size[1]-left-new_w
|
||||||
|
bottom=size[0]-top-new_h
|
||||||
|
img =cv2.copyMakeBorder(new_img,top,bottom,left,right,cv2.BORDER_CONSTANT,value=(114,114,114))
|
||||||
|
return img,r,left,top
|
||||||
|
|
||||||
|
def load_model(weights, device): #加载yolov8 模型
|
||||||
|
model = attempt_load_weights(weights,device=device) # load FP32 model
|
||||||
|
return model
|
||||||
|
|
||||||
|
def xywh2xyxy(det): #xywh转化为xyxy
|
||||||
|
y = det.clone()
|
||||||
|
y[:,0]=det[:,0]-det[0:,2]/2
|
||||||
|
y[:,1]=det[:,1]-det[0:,3]/2
|
||||||
|
y[:,2]=det[:,0]+det[0:,2]/2
|
||||||
|
y[:,3]=det[:,1]+det[0:,3]/2
|
||||||
|
return y
|
||||||
|
|
||||||
|
def my_nums(dets,iou_thresh): #nms操作
|
||||||
|
y = dets.clone()
|
||||||
|
y_box_score = y[:,:5]
|
||||||
|
index = torch.argsort(y_box_score[:,-1],descending=True)
|
||||||
|
keep = []
|
||||||
|
while index.size()[0]>0:
|
||||||
|
i = index[0].item()
|
||||||
|
keep.append(i)
|
||||||
|
x1=torch.maximum(y_box_score[i,0],y_box_score[index[1:],0])
|
||||||
|
y1=torch.maximum(y_box_score[i,1],y_box_score[index[1:],1])
|
||||||
|
x2=torch.minimum(y_box_score[i,2],y_box_score[index[1:],2])
|
||||||
|
y2=torch.minimum(y_box_score[i,3],y_box_score[index[1:],3])
|
||||||
|
zero_=torch.tensor(0).to(device)
|
||||||
|
w=torch.maximum(zero_,x2-x1)
|
||||||
|
h=torch.maximum(zero_,y2-y1)
|
||||||
|
inter_area = w*h
|
||||||
|
nuion_area1 =(y_box_score[i,2]-y_box_score[i,0])*(y_box_score[i,3]-y_box_score[i,1]) #计算交集
|
||||||
|
union_area2 =(y_box_score[index[1:],2]-y_box_score[index[1:],0])*(y_box_score[index[1:],3]-y_box_score[index[1:],1])#计算并集
|
||||||
|
|
||||||
|
iou = inter_area/(nuion_area1+union_area2-inter_area)#计算iou
|
||||||
|
|
||||||
|
idx = torch.where(iou<=iou_thresh)[0] #保留iou小于iou_thresh的
|
||||||
|
index=index[idx+1]
|
||||||
|
return keep
|
||||||
|
|
||||||
|
|
||||||
|
def restore_box(dets,r,left,top): #坐标还原到原图上
|
||||||
|
|
||||||
|
dets[:,[0,2,5,7,9,11]]=dets[:,[0,2,5,7,9,11]]-left
|
||||||
|
dets[:,[1,3,6,8,10,12]]= dets[:,[1,3,6,8,10,12]]-top
|
||||||
|
dets[:,:4]/=r
|
||||||
|
dets[:,5:13]/=r
|
||||||
|
|
||||||
|
return dets
|
||||||
|
# pass
|
||||||
|
|
||||||
|
def post_processing(prediction,conf,iou_thresh,r,left,top): #后处理
|
||||||
|
|
||||||
|
prediction = prediction.permute(0,2,1).squeeze(0)
|
||||||
|
xc = prediction[:, 4:6].amax(1) > conf #过滤掉小于conf的框
|
||||||
|
x = prediction[xc]
|
||||||
|
if not len(x):
|
||||||
|
return []
|
||||||
|
boxes = x[:,:4] #框
|
||||||
|
boxes = xywh2xyxy(boxes) #中心点 宽高 变为 左上 右下两个点
|
||||||
|
score,index = torch.max(x[:,4:6],dim=-1,keepdim=True) #找出得分和所属类别
|
||||||
|
x = torch.cat((boxes,score,x[:,6:14],index),dim=1) #重新组合
|
||||||
|
|
||||||
|
score = x[:,4]
|
||||||
|
keep =my_nums(x,iou_thresh)
|
||||||
|
x=x[keep]
|
||||||
|
x=restore_box(x,r,left,top)
|
||||||
|
return x
|
||||||
|
|
||||||
|
def pre_processing(img,opt,device): #前处理
|
||||||
|
img, r,left,top= letter_box(img,(opt.img_size,opt.img_size))
|
||||||
|
# print(img.shape)
|
||||||
|
img=img[:,:,::-1].transpose((2,0,1)).copy() #bgr2rgb hwc2chw
|
||||||
|
img = torch.from_numpy(img).to(device)
|
||||||
|
img = img.float()
|
||||||
|
img = img/255.0
|
||||||
|
img =img.unsqueeze(0)
|
||||||
|
return img ,r,left,top
|
||||||
|
|
||||||
|
def det_rec_plate(img,img_ori,detect_model,plate_rec_model):
|
||||||
|
result_list=[]
|
||||||
|
img,r,left,top = pre_processing(img,opt,device) #前处理
|
||||||
|
predict = detect_model(img)[0]
|
||||||
|
outputs=post_processing(predict,0.3,0.5,r,left,top) #后处理
|
||||||
|
for output in outputs:
|
||||||
|
result_dict={}
|
||||||
|
output = output.squeeze().cpu().numpy().tolist()
|
||||||
|
rect=output[:4]
|
||||||
|
rect = [int(x) for x in rect]
|
||||||
|
label = output[-1]
|
||||||
|
land_marks=np.array(output[5:13],dtype='int64').reshape(4,2)
|
||||||
|
roi_img = four_point_transform(img_ori,land_marks) #透视变换得到车牌小图
|
||||||
|
if int(label): #判断是否是双层车牌,是双牌的话进行分割后然后拼接
|
||||||
|
roi_img=get_split_merge(roi_img)
|
||||||
|
plate_number,rec_prob,plate_color,color_conf=get_plate_result(roi_img,device,plate_rec_model,is_color=True)
|
||||||
|
|
||||||
|
result_dict['plate_no']=plate_number #车牌号
|
||||||
|
result_dict['plate_color']=plate_color #车牌颜色
|
||||||
|
result_dict['rect']=rect #车牌roi区域
|
||||||
|
result_dict['detect_conf']=output[4] #检测区域得分
|
||||||
|
result_dict['landmarks']=land_marks.tolist() #车牌角点坐标
|
||||||
|
# result_dict['rec_conf']=rec_prob #每个字符的概率
|
||||||
|
result_dict['roi_height']=roi_img.shape[0] #车牌高度
|
||||||
|
# result_dict['plate_color']=plate_color
|
||||||
|
# if is_color:
|
||||||
|
result_dict['color_conf']=color_conf #颜色得分
|
||||||
|
result_dict['plate_type']=int(label) #单双层 0单层 1双层
|
||||||
|
result_list.append(result_dict)
|
||||||
|
return result_list
|
||||||
|
|
||||||
|
|
||||||
|
def draw_result(orgimg,dict_list,is_color=False): # 车牌结果画出来
|
||||||
|
result_str =""
|
||||||
|
for result in dict_list:
|
||||||
|
rect_area = result['rect']
|
||||||
|
|
||||||
|
x,y,w,h = rect_area[0],rect_area[1],rect_area[2]-rect_area[0],rect_area[3]-rect_area[1]
|
||||||
|
padding_w = 0.05*w
|
||||||
|
padding_h = 0.11*h
|
||||||
|
rect_area[0]=max(0,int(x-padding_w))
|
||||||
|
rect_area[1]=max(0,int(y-padding_h))
|
||||||
|
rect_area[2]=min(orgimg.shape[1],int(rect_area[2]+padding_w))
|
||||||
|
rect_area[3]=min(orgimg.shape[0],int(rect_area[3]+padding_h))
|
||||||
|
|
||||||
|
height_area = result['roi_height']
|
||||||
|
landmarks=result['landmarks']
|
||||||
|
result_p = result['plate_no']
|
||||||
|
if result['plate_type']==0:#单层
|
||||||
|
result_p+=" "+result['plate_color']
|
||||||
|
else: #双层
|
||||||
|
result_p+=" "+result['plate_color']+"双层"
|
||||||
|
result_str+=result_p+" "
|
||||||
|
for i in range(4): #关键点
|
||||||
|
cv2.circle(orgimg, (int(landmarks[i][0]), int(landmarks[i][1])), 5, clors[i], -1)
|
||||||
|
cv2.rectangle(orgimg,(rect_area[0],rect_area[1]),(rect_area[2],rect_area[3]),(0,0,255),2) #画框
|
||||||
|
|
||||||
|
labelSize = cv2.getTextSize(result_p,cv2.FONT_HERSHEY_SIMPLEX,0.5,1) #获得字体的大小
|
||||||
|
if rect_area[0]+labelSize[0][0]>orgimg.shape[1]: #防止显示的文字越界
|
||||||
|
rect_area[0]=int(orgimg.shape[1]-labelSize[0][0])
|
||||||
|
orgimg=cv2.rectangle(orgimg,(rect_area[0],int(rect_area[1]-round(1.6*labelSize[0][1]))),(int(rect_area[0]+round(1.2*labelSize[0][0])),rect_area[1]+labelSize[1]),(255,255,255),cv2.FILLED)#画文字框,背景白色
|
||||||
|
|
||||||
|
if len(result)>=6:
|
||||||
|
orgimg=cv2ImgAddText(orgimg,result_p,rect_area[0],int(rect_area[1]-round(1.6*labelSize[0][1])),(0,0,0),21)
|
||||||
|
# orgimg=cv2ImgAddText(orgimg,result_p,rect_area[0]-height_area,rect_area[1]-height_area-10,(0,255,0),height_area)
|
||||||
|
|
||||||
|
print(result_str)
|
||||||
|
return orgimg
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument('--detect_model', nargs='+', type=str, default=r'weights/yolov8-lite-t-plate.pt', help='model.pt path(s)') #yolov8检测模型
|
||||||
|
parser.add_argument('--rec_model', type=str, default=r'weights/plate_rec_color.pth', help='model.pt path(s)')#车牌字符识别模型
|
||||||
|
parser.add_argument('--image_path', type=str, default=r'imgs', help='source') #待识别图片路径
|
||||||
|
parser.add_argument('--img_size', type=int, default=320, help='inference size (pixels)') #yolov8 网络模型输入大小
|
||||||
|
parser.add_argument('--output', type=str, default='result', help='source') #结果保存的文件夹
|
||||||
|
device =torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||||
|
|
||||||
|
clors = [(255,0,0),(0,255,0),(0,0,255),(255,255,0),(0,255,255)]
|
||||||
|
opt = parser.parse_args()
|
||||||
|
save_path = opt.output
|
||||||
|
|
||||||
|
if not os.path.exists(save_path):
|
||||||
|
os.mkdir(save_path)
|
||||||
|
|
||||||
|
detect_model = load_model(opt.detect_model, device) #初始化yolov8识别模型
|
||||||
|
plate_rec_model=init_model(device,opt.rec_model,is_color=True) #初始化识别模型
|
||||||
|
#算参数量
|
||||||
|
total = sum(p.numel() for p in detect_model.parameters())
|
||||||
|
total_1 = sum(p.numel() for p in plate_rec_model.parameters())
|
||||||
|
print("yolov8 detect params: %.2fM,rec params: %.2fM" % (total/1e6,total_1/1e6))
|
||||||
|
|
||||||
|
detect_model.eval()
|
||||||
|
# print(detect_model)
|
||||||
|
file_list = []
|
||||||
|
allFilePath(opt.image_path,file_list)
|
||||||
|
count=0
|
||||||
|
time_all = 0
|
||||||
|
time_begin=time.time()
|
||||||
|
for pic_ in file_list:
|
||||||
|
print(count,pic_,end=" ")
|
||||||
|
time_b = time.time() #开始时间
|
||||||
|
img = cv2.imread(pic_)
|
||||||
|
img_ori = copy.deepcopy(img)
|
||||||
|
result_list=det_rec_plate(img,img_ori,detect_model,plate_rec_model)
|
||||||
|
time_e=time.time()
|
||||||
|
ori_img=draw_result(img,result_list) #将结果画在图上
|
||||||
|
img_name = os.path.basename(pic_)
|
||||||
|
save_img_path = os.path.join(save_path,img_name) #图片保存的路径
|
||||||
|
time_gap = time_e-time_b #计算单个图片识别耗时
|
||||||
|
if count:
|
||||||
|
time_all+=time_gap
|
||||||
|
count+=1
|
||||||
|
cv2.imwrite(save_img_path,ori_img) #op
|
||||||
|
# print(result_list)
|
||||||
|
print(f"sumTime time is {time.time()-time_begin} s, average pic time is {time_all/(len(file_list)-1)}")
|
||||||
|
|
||||||
85
docs/README.md
Normal file
@@ -0,0 +1,85 @@
|
|||||||
|
# Ultralytics Docs
|
||||||
|
|
||||||
|
Ultralytics Docs are deployed to [https://docs.ultralytics.com](https://docs.ultralytics.com).
|
||||||
|
|
||||||
|
### Install Ultralytics package
|
||||||
|
|
||||||
|
To install the ultralytics package in developer mode, you will need to have Git and Python 3 installed on your system.
|
||||||
|
Then, follow these steps:
|
||||||
|
|
||||||
|
1. Clone the ultralytics repository to your local machine using Git:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ultralytics/ultralytics.git
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Navigate to the root directory of the repository:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd ultralytics
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Install the package in developer mode using pip:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install -e '.[dev]'
|
||||||
|
```
|
||||||
|
|
||||||
|
This will install the ultralytics package and its dependencies in developer mode, allowing you to make changes to the
|
||||||
|
package code and have them reflected immediately in your Python environment.
|
||||||
|
|
||||||
|
Note that you may need to use the pip3 command instead of pip if you have multiple versions of Python installed on your
|
||||||
|
system.
|
||||||
|
|
||||||
|
### Building and Serving Locally
|
||||||
|
|
||||||
|
The `mkdocs serve` command is used to build and serve a local version of the MkDocs documentation site. It is typically
|
||||||
|
used during the development and testing phase of a documentation project.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
mkdocs serve
|
||||||
|
```
|
||||||
|
|
||||||
|
Here is a breakdown of what this command does:
|
||||||
|
|
||||||
|
- `mkdocs`: This is the command-line interface (CLI) for the MkDocs static site generator. It is used to build and serve
|
||||||
|
MkDocs sites.
|
||||||
|
- `serve`: This is a subcommand of the `mkdocs` CLI that tells it to build and serve the documentation site locally.
|
||||||
|
- `-a`: This flag specifies the hostname and port number to bind the server to. The default value is `localhost:8000`.
|
||||||
|
- `-t`: This flag specifies the theme to use for the documentation site. The default value is `mkdocs`.
|
||||||
|
- `-s`: This flag tells the `serve` command to serve the site in silent mode, which means it will not display any log
|
||||||
|
messages or progress updates.
|
||||||
|
When you run the `mkdocs serve` command, it will build the documentation site using the files in the `docs/` directory
|
||||||
|
and serve it at the specified hostname and port number. You can then view the site by going to the URL in your web
|
||||||
|
browser.
|
||||||
|
|
||||||
|
While the site is being served, you can make changes to the documentation files and see them reflected in the live site
|
||||||
|
immediately. This is useful for testing and debugging your documentation before deploying it to a live server.
|
||||||
|
|
||||||
|
To stop the serve command and terminate the local server, you can use the `CTRL+C` keyboard shortcut.
|
||||||
|
|
||||||
|
### Deploying Your Documentation Site
|
||||||
|
|
||||||
|
To deploy your MkDocs documentation site, you will need to choose a hosting provider and a deployment method. Some
|
||||||
|
popular options include GitHub Pages, GitLab Pages, and Amazon S3.
|
||||||
|
|
||||||
|
Before you can deploy your site, you will need to configure your `mkdocs.yml` file to specify the remote host and any
|
||||||
|
other necessary deployment settings.
|
||||||
|
|
||||||
|
Once you have configured your `mkdocs.yml` file, you can use the `mkdocs deploy` command to build and deploy your site.
|
||||||
|
This command will build the documentation site using the files in the `docs/` directory and the specified configuration
|
||||||
|
file and theme, and then deploy the site to the specified remote host.
|
||||||
|
|
||||||
|
For example, to deploy your site to GitHub Pages using the gh-deploy plugin, you can use the following command:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
mkdocs gh-deploy
|
||||||
|
```
|
||||||
|
|
||||||
|
If you are using GitHub Pages, you can set a custom domain for your documentation site by going to the "Settings" page
|
||||||
|
for your repository and updating the "Custom domain" field in the "GitHub Pages" section.
|
||||||
|
|
||||||
|
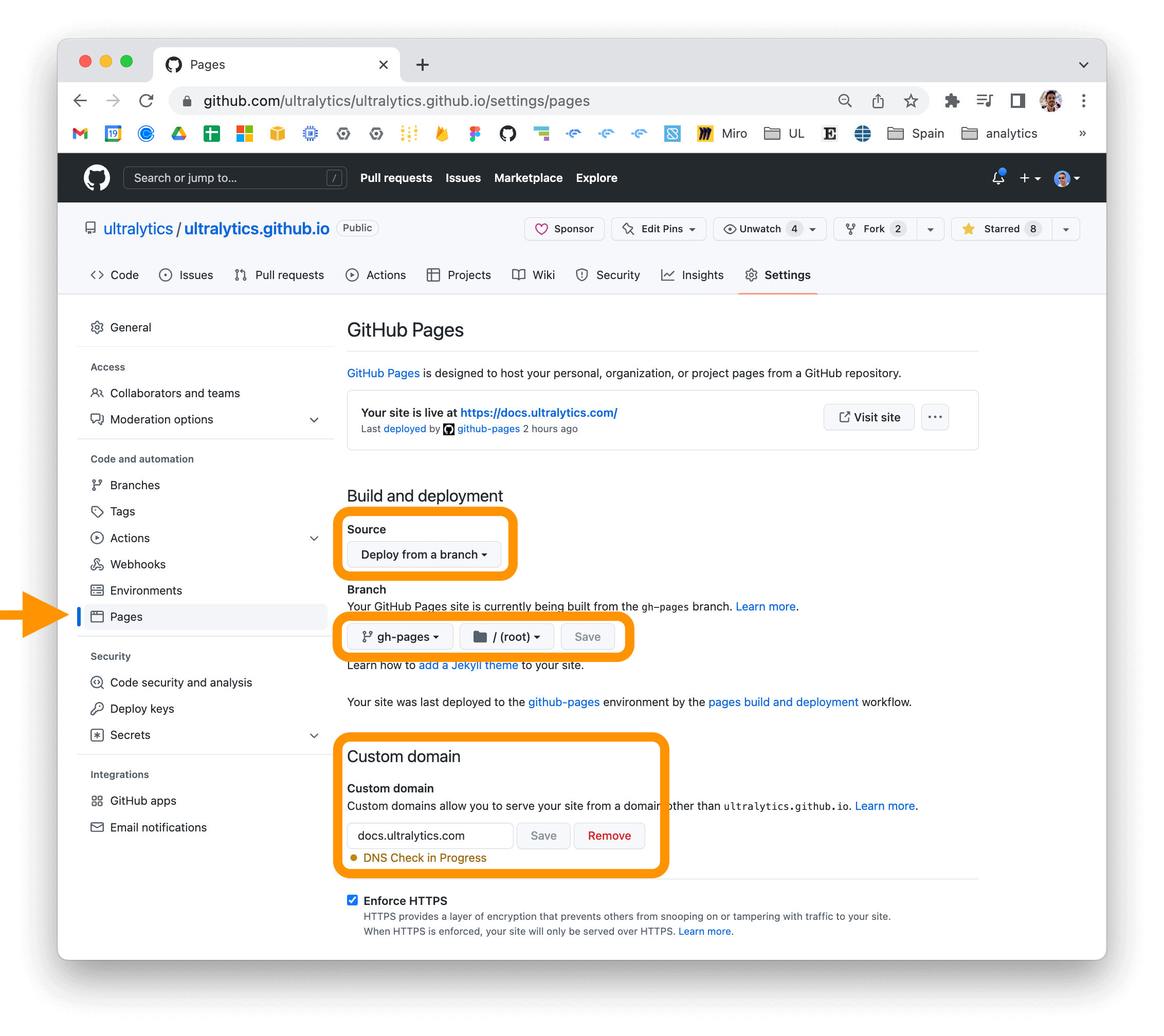
|
||||||
|
|
||||||
|
For more information on deploying your MkDocs documentation site, see
|
||||||
|
the [MkDocs documentation](https://www.mkdocs.org/user-guide/deploying-your-docs/).
|
||||||
26
docs/SECURITY.md
Normal file
@@ -0,0 +1,26 @@
|
|||||||
|
At [Ultralytics](https://ultralytics.com), the security of our users' data and systems is of utmost importance. To
|
||||||
|
ensure the safety and security of our [open-source projects](https://github.com/ultralytics), we have implemented
|
||||||
|
several measures to detect and prevent security vulnerabilities.
|
||||||
|
|
||||||
|
[](https://snyk.io/advisor/python/ultralytics)
|
||||||
|
|
||||||
|
## Snyk Scanning
|
||||||
|
|
||||||
|
We use [Snyk](https://snyk.io/advisor/python/ultralytics) to regularly scan the YOLOv8 repository for vulnerabilities
|
||||||
|
and security issues. Our goal is to identify and remediate any potential threats as soon as possible, to minimize any
|
||||||
|
risks to our users.
|
||||||
|
|
||||||
|
## GitHub CodeQL Scanning
|
||||||
|
|
||||||
|
In addition to our Snyk scans, we also use
|
||||||
|
GitHub's [CodeQL](https://docs.github.com/en/code-security/code-scanning/automatically-scanning-your-code-for-vulnerabilities-and-errors/about-code-scanning-with-codeql)
|
||||||
|
scans to proactively identify and address security vulnerabilities.
|
||||||
|
|
||||||
|
## Reporting Security Issues
|
||||||
|
|
||||||
|
If you suspect or discover a security vulnerability in the YOLOv8 repository, please let us know immediately. You can
|
||||||
|
reach out to us directly via our [contact form](https://ultralytics.com/contact) or
|
||||||
|
via [security@ultralytics.com](mailto:security@ultralytics.com). Our security team will investigate and respond as soon
|
||||||
|
as possible.
|
||||||
|
|
||||||
|
We appreciate your help in keeping the YOLOv8 repository secure and safe for everyone.
|
||||||
48
docs/app.md
Normal file
@@ -0,0 +1,48 @@
|
|||||||
|
# Ultralytics HUB App for YOLOv8
|
||||||
|
|
||||||
|
<a href="https://bit.ly/ultralytics_hub" target="_blank">
|
||||||
|
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/ultralytics-hub.png"></a>
|
||||||
|
<br>
|
||||||
|
<div align="center">
|
||||||
|
<a href="https://github.com/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="2%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||||
|
<a href="https://www.linkedin.com/company/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="2%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||||
|
<a href="https://twitter.com/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="2%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||||
|
<a href="https://youtube.com/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="2%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||||
|
<a href="https://www.tiktok.com/@ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="2%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||||
|
<a href="https://www.instagram.com/ultralytics/" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="2%" alt="" /></a>
|
||||||
|
<br>
|
||||||
|
<br>
|
||||||
|
<a href="https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app" style="text-decoration:none;">
|
||||||
|
<img src="https://raw.githubusercontent.com/ultralytics/assets/master/app/google-play.svg" width="15%" alt="" /></a>
|
||||||
|
<a href="https://apps.apple.com/xk/app/ultralytics/id1583935240" style="text-decoration:none;">
|
||||||
|
<img src="https://raw.githubusercontent.com/ultralytics/assets/master/app/app-store.svg" width="15%" alt="" /></a>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
Welcome to the Ultralytics HUB app, which is designed to demonstrate the power and capabilities of the YOLOv5 and YOLOv8
|
||||||
|
models. This app is available for download on
|
||||||
|
the [Apple App Store](https://apps.apple.com/xk/app/ultralytics/id1583935240) and
|
||||||
|
the [Google Play Store](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app).
|
||||||
|
|
||||||
|
**To install the app, simply scan the QR code provided above**. At the moment, the app features YOLOv5 models, with
|
||||||
|
YOLOv8 models set to be available soon.
|
||||||
|
|
||||||
|
With the YOLOv5 model, you can easily detect and classify objects in images and videos with high accuracy and speed. The
|
||||||
|
model has been trained on a vast dataset and can recognize a wide range of objects, including pedestrians, traffic
|
||||||
|
signs, and cars.
|
||||||
|
|
||||||
|
Using this app, you can try out YOLOv5 on your images and videos, and observe how the model works in real-time.
|
||||||
|
Additionally, you can learn more about YOLOv5's functionality and how it can be integrated into real-world applications.
|
||||||
|
|
||||||
|
We are confident that you will enjoy using YOLOv5 and be amazed at its capabilities. Thank you for choosing Ultralytics
|
||||||
|
for your AI solutions.
|
||||||
112
docs/hub.md
Normal file
@@ -0,0 +1,112 @@
|
|||||||
|
# Ultralytics HUB
|
||||||
|
|
||||||
|
<a href="https://bit.ly/ultralytics_hub" target="_blank">
|
||||||
|
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/ultralytics-hub.png"></a>
|
||||||
|
<br>
|
||||||
|
<div align="center">
|
||||||
|
<a href="https://github.com/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="2%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||||
|
<a href="https://www.linkedin.com/company/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="2%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||||
|
<a href="https://twitter.com/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="2%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||||
|
<a href="https://youtube.com/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="2%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||||
|
<a href="https://www.tiktok.com/@ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="2%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||||
|
<a href="https://www.instagram.com/ultralytics/" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="2%" alt="" /></a>
|
||||||
|
<br>
|
||||||
|
<br>
|
||||||
|
<a href="https://github.com/ultralytics/hub/actions/workflows/ci.yaml">
|
||||||
|
<img src="https://github.com/ultralytics/hub/actions/workflows/ci.yaml/badge.svg" alt="CI CPU"></a>
|
||||||
|
<a href="https://colab.research.google.com/github/ultralytics/hub/blob/master/hub.ipynb">
|
||||||
|
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
|
||||||
|
[Ultralytics HUB](https://hub.ultralytics.com) is a new no-code online tool developed
|
||||||
|
by [Ultralytics](https://ultralytics.com), the creators of the popular [YOLOv5](https://github.com/ultralytics/yolov5)
|
||||||
|
object detection and image segmentation models. With Ultralytics HUB, users can easily train and deploy YOLO models
|
||||||
|
without any coding or technical expertise.
|
||||||
|
|
||||||
|
Ultralytics HUB is designed to be user-friendly and intuitive, with a drag-and-drop interface that allows users to
|
||||||
|
easily upload their data and select their model configurations. It also offers a range of pre-trained models and
|
||||||
|
templates to choose from, making it easy for users to get started with training their own models. Once a model is
|
||||||
|
trained, it can be easily deployed and used for real-time object detection and image segmentation tasks. Overall,
|
||||||
|
Ultralytics HUB is an essential tool for anyone looking to use YOLO for their object detection and image segmentation
|
||||||
|
projects.
|
||||||
|
|
||||||
|
**[Get started now](https://hub.ultralytics.com)** and experience the power and simplicity of Ultralytics HUB for
|
||||||
|
yourself. Sign up for a free account and start building, training, and deploying YOLOv5 and YOLOv8 models today.
|
||||||
|
|
||||||
|
## 1. Upload a Dataset
|
||||||
|
|
||||||
|
Ultralytics HUB datasets are just like YOLOv5 🚀 datasets, they use the same structure and the same label formats to keep
|
||||||
|
everything simple.
|
||||||
|
|
||||||
|
When you upload a dataset to Ultralytics HUB, make sure to **place your dataset YAML inside the dataset root directory**
|
||||||
|
as in the example shown below, and then zip for upload to https://hub.ultralytics.com/. Your **dataset YAML, directory
|
||||||
|
and zip** should all share the same name. For example, if your dataset is called 'coco6' as in our
|
||||||
|
example [ultralytics/hub/coco6.zip](https://github.com/ultralytics/hub/blob/master/coco6.zip), then you should have a
|
||||||
|
coco6.yaml inside your coco6/ directory, which should zip to create coco6.zip for upload:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
zip -r coco6.zip coco6
|
||||||
|
```
|
||||||
|
|
||||||
|
The example [coco6.zip](https://github.com/ultralytics/hub/blob/master/coco6.zip) dataset in this repository can be
|
||||||
|
downloaded and unzipped to see exactly how to structure your custom dataset.
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img width="80%" src="https://user-images.githubusercontent.com/26833433/201424843-20fa081b-ad4b-4d6c-a095-e810775908d8.png" title="COCO6" />
|
||||||
|
</p>
|
||||||
|
|
||||||
|
The dataset YAML is the same standard YOLOv5 YAML format. See
|
||||||
|
the [YOLOv5 Train Custom Data tutorial](https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data) for full details.
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||||
|
path: # dataset root dir (leave empty for HUB)
|
||||||
|
train: images/train # train images (relative to 'path') 8 images
|
||||||
|
val: images/val # val images (relative to 'path') 8 images
|
||||||
|
test: # test images (optional)
|
||||||
|
|
||||||
|
# Classes
|
||||||
|
names:
|
||||||
|
0: person
|
||||||
|
1: bicycle
|
||||||
|
2: car
|
||||||
|
3: motorcycle
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
After zipping your dataset, sign in to [Ultralytics HUB](https://bit.ly/ultralytics_hub) and click the Datasets tab.
|
||||||
|
Click 'Upload Dataset' to upload, scan and visualize your new dataset before training new YOLOv5 models on it!
|
||||||
|
|
||||||
|
<img width="100%" alt="HUB Dataset Upload" src="https://user-images.githubusercontent.com/26833433/216763338-9a8812c8-a4e5-4362-8102-40dad7818396.png">
|
||||||
|
|
||||||
|
## 2. Train a Model
|
||||||
|
|
||||||
|
Connect to the Ultralytics HUB notebook and use your model API key to begin training!
|
||||||
|
|
||||||
|
<a href="https://colab.research.google.com/github/ultralytics/hub/blob/master/hub.ipynb" target="_blank">
|
||||||
|
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
||||||
|
|
||||||
|
## 3. Deploy to Real World
|
||||||
|
|
||||||
|
Export your model to 13 different formats, including TensorFlow, ONNX, OpenVINO, CoreML, Paddle and many others. Run
|
||||||
|
models directly on your [iOS](https://apps.apple.com/xk/app/ultralytics/id1583935240) or
|
||||||
|
[Android](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app) mobile device by downloading
|
||||||
|
the [Ultralytics App](https://ultralytics.com/app_install)!
|
||||||
|
|
||||||
|
## ❓ Issues
|
||||||
|
|
||||||
|
If you are a new [Ultralytics HUB](https://bit.ly/ultralytics_hub) user and have questions or comments, you are in the
|
||||||
|
right place! Please raise a [New Issue](https://github.com/ultralytics/hub/issues/new/choose) and let us know what we
|
||||||
|
can do to make your life better 😃!
|
||||||
45
docs/index.md
Normal file
@@ -0,0 +1,45 @@
|
|||||||
|
<div align="center">
|
||||||
|
<p>
|
||||||
|
<a href="https://github.com/ultralytics/ultralytics" target="_blank">
|
||||||
|
<img width="1024" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov8/banner-yolov8.png"></a>
|
||||||
|
</p>
|
||||||
|
<a href="https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml"><img src="https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml/badge.svg" alt="Ultralytics CI"></a>
|
||||||
|
<a href="https://zenodo.org/badge/latestdoi/264818686"><img src="https://zenodo.org/badge/264818686.svg" alt="YOLOv8 Citation"></a>
|
||||||
|
<a href="https://hub.docker.com/r/ultralytics/ultralytics"><img src="https://img.shields.io/docker/pulls/ultralytics/ultralytics?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
<br>
|
||||||
|
<a href="https://console.paperspace.com/github/ultralytics/ultralytics"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"/></a>
|
||||||
|
<a href="https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
||||||
|
<a href="https://www.kaggle.com/ultralytics/yolov8"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
Introducing [Ultralytics](https://ultralytics.com) [YOLOv8](https://github.com/ultralytics/ultralytics), the latest version of the acclaimed real-time object detection and image segmentation model. YOLOv8 is built on cutting-edge advancements in deep learning and computer vision, offering unparalleled performance in terms of speed and accuracy. Its streamlined design makes it suitable for various applications and easily adaptable to different hardware platforms, from edge devices to cloud APIs.
|
||||||
|
|
||||||
|
Explore the YOLOv8 Docs, a comprehensive resource designed to help you understand and utilize its features and capabilities. Whether you are a seasoned machine learning practitioner or new to the field, this hub aims to maximize YOLOv8's potential in your projects
|
||||||
|
|
||||||
|
## Where to Start
|
||||||
|
|
||||||
|
- **Install** `ultralytics` with pip and get up and running in minutes [:material-clock-fast: Get Started](quickstart.md){ .md-button }
|
||||||
|
- **Predict** new images and videos with YOLOv8 [:octicons-image-16: Predict on Images](modes/predict.md){ .md-button }
|
||||||
|
- **Train** a new YOLOv8 model on your own custom dataset [:fontawesome-solid-brain: Train a Model](modes/train.md){ .md-button }
|
||||||
|
- **Explore** YOLOv8 tasks like segment, classify, pose and track [:material-magnify-expand: Explore Tasks](tasks/index.md){ .md-button }
|
||||||
|
|
||||||
|
## YOLO: A Brief History
|
||||||
|
|
||||||
|
[YOLO](https://arxiv.org/abs/1506.02640) (You Only Look Once), a popular object detection and image segmentation model, was developed by Joseph Redmon and Ali Farhadi at the University of Washington. Launched in 2015, YOLO quickly gained popularity for its high speed and accuracy.
|
||||||
|
|
||||||
|
- [YOLOv2](https://arxiv.org/abs/1612.08242), released in 2016, improved the original model by incorporating batch normalization, anchor boxes, and dimension clusters.
|
||||||
|
- [YOLOv3](https://pjreddie.com/media/files/papers/YOLOv3.pdf), launched in 2018, further enhanced the model's performance using a more efficient backbone network, multiple anchors and spatial pyramid pooling.
|
||||||
|
- [YOLOv4](https://arxiv.org/abs/2004.10934) was released in 2020, introducing innovations like Mosaic data augmentation, a new anchor-free detection head, and a new loss function.
|
||||||
|
- [YOLOv5](https://github.com/ultralytics/yolov5) further improved the model's performance and added new features such as hyperparameter optimization, integrated experiment tracking and automatic export to popular export formats.
|
||||||
|
- [YOLOv6](https://github.com/meituan/YOLOv6) was open-sourced by Meituan in 2022 and is in use in many of the company's autonomous delivery robots.
|
||||||
|
- [YOLOv7](https://github.com/WongKinYiu/yolov7) added additional tasks such as pose estimation on the COCO keypoints dataset.
|
||||||
|
|
||||||
|
Since its launch YOLO has been employed in various applications, including autonomous vehicles, security and surveillance, and medical imaging, and has won several competitions like the COCO Object Detection Challenge and the DOTA Object Detection Challenge.
|
||||||
|
|
||||||
|
## Ultralytics YOLOv8
|
||||||
|
|
||||||
|
[Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) is the latest version of the YOLO object detection and image segmentation model. As a cutting-edge, state-of-the-art (SOTA) model, YOLOv8 builds on the success of previous versions, introducing new features and improvements for enhanced performance, flexibility, and efficiency.
|
||||||
|
|
||||||
|
YOLOv8 is designed with a strong focus on speed, size, and accuracy, making it a compelling choice for various vision AI tasks. It outperforms previous versions by incorporating innovations like a new backbone network, a new anchor-free split head, and new loss functions. These improvements enable YOLOv8 to deliver superior results, while maintaining a compact size and exceptional speed.
|
||||||
|
|
||||||
|
Additionally, YOLOv8 supports a full range of vision AI tasks, including [detection](tasks/detect.md), [segmentation](tasks/segment.md), [pose estimation](tasks/pose.md), [tracking](modes/track.md), and [classification](tasks/classify.md). This versatility allows users to leverage YOLOv8's capabilities across diverse applications and domains.
|
||||||
65
docs/modes/benchmark.md
Normal file
@@ -0,0 +1,65 @@
|
|||||||
|
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||||
|
|
||||||
|
**Benchmark mode** is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks
|
||||||
|
provide information on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose)
|
||||||
|
or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
|
||||||
|
formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
|
||||||
|
their specific use case based on their requirements for speed and accuracy.
|
||||||
|
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
* Export to ONNX or OpenVINO for up to 3x CPU speedup.
|
||||||
|
* Export to TensorRT for up to 5x GPU speedup.
|
||||||
|
|
||||||
|
## Usage Examples
|
||||||
|
|
||||||
|
Run YOLOv8n benchmarks on all supported export formats including ONNX, TensorRT etc. See Arguments section below for a
|
||||||
|
full list of export arguments.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics.yolo.utils.benchmarks import benchmark
|
||||||
|
|
||||||
|
# Benchmark
|
||||||
|
benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo benchmark model=yolov8n.pt imgsz=640 half=False device=0
|
||||||
|
```
|
||||||
|
|
||||||
|
## Arguments
|
||||||
|
|
||||||
|
Arguments such as `model`, `imgsz`, `half`, `device`, and `hard_fail` provide users with the flexibility to fine-tune
|
||||||
|
the benchmarks to their specific needs and compare the performance of different export formats with ease.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|-------------|---------|----------------------------------------------------------------------|
|
||||||
|
| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
|
||||||
|
| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
|
||||||
|
| `half` | `False` | FP16 quantization |
|
||||||
|
| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
|
||||||
|
| `hard_fail` | `False` | do not continue on error (bool), or val floor threshold (float) |
|
||||||
|
|
||||||
|
## Export Formats
|
||||||
|
|
||||||
|
Benchmarks will attempt to run automatically on all possible export formats below.
|
||||||
|
|
||||||
|
| Format | `format` Argument | Model | Metadata |
|
||||||
|
|--------------------------------------------------------------------|-------------------|---------------------------|----------|
|
||||||
|
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
|
||||||
|
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
|
||||||
|
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
|
||||||
|
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
|
||||||
|
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
|
||||||
|
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
|
||||||
|
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
|
||||||
|
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
|
||||||
|
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
|
||||||
|
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
|
||||||
|
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
|
||||||
|
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
|
||||||
81
docs/modes/export.md
Normal file
@@ -0,0 +1,81 @@
|
|||||||
|
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||||
|
|
||||||
|
**Export mode** is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the
|
||||||
|
model is converted to a format that can be used by other software applications or hardware devices. This mode is useful
|
||||||
|
when deploying the model to production environments.
|
||||||
|
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
* Export to ONNX or OpenVINO for up to 3x CPU speedup.
|
||||||
|
* Export to TensorRT for up to 5x GPU speedup.
|
||||||
|
|
||||||
|
## Usage Examples
|
||||||
|
|
||||||
|
Export a YOLOv8n model to a different format like ONNX or TensorRT. See Arguments section below for a full list of
|
||||||
|
export arguments.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom trained
|
||||||
|
|
||||||
|
# Export the model
|
||||||
|
model.export(format='onnx')
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo export model=yolov8n.pt format=onnx # export official model
|
||||||
|
yolo export model=path/to/best.pt format=onnx # export custom trained model
|
||||||
|
```
|
||||||
|
|
||||||
|
## Arguments
|
||||||
|
|
||||||
|
Export settings for YOLO models refer to the various configurations and options used to save or
|
||||||
|
export the model for use in other environments or platforms. These settings can affect the model's performance, size,
|
||||||
|
and compatibility with different systems. Some common YOLO export settings include the format of the exported model
|
||||||
|
file (e.g. ONNX, TensorFlow SavedModel), the device on which the model will be run (e.g. CPU, GPU), and the presence of
|
||||||
|
additional features such as masks or multiple labels per box. Other factors that may affect the export process include
|
||||||
|
the specific task the model is being used for and the requirements or constraints of the target environment or platform.
|
||||||
|
It is important to carefully consider and configure these settings to ensure that the exported model is optimized for
|
||||||
|
the intended use case and can be used effectively in the target environment.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|-------------|-----------------|------------------------------------------------------|
|
||||||
|
| `format` | `'torchscript'` | format to export to |
|
||||||
|
| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
|
||||||
|
| `keras` | `False` | use Keras for TF SavedModel export |
|
||||||
|
| `optimize` | `False` | TorchScript: optimize for mobile |
|
||||||
|
| `half` | `False` | FP16 quantization |
|
||||||
|
| `int8` | `False` | INT8 quantization |
|
||||||
|
| `dynamic` | `False` | ONNX/TF/TensorRT: dynamic axes |
|
||||||
|
| `simplify` | `False` | ONNX: simplify model |
|
||||||
|
| `opset` | `None` | ONNX: opset version (optional, defaults to latest) |
|
||||||
|
| `workspace` | `4` | TensorRT: workspace size (GB) |
|
||||||
|
| `nms` | `False` | CoreML: add NMS |
|
||||||
|
|
||||||
|
## Export Formats
|
||||||
|
|
||||||
|
Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
|
||||||
|
i.e. `format='onnx'` or `format='engine'`.
|
||||||
|
|
||||||
|
| Format | `format` Argument | Model | Metadata |
|
||||||
|
|--------------------------------------------------------------------|-------------------|---------------------------|----------|
|
||||||
|
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
|
||||||
|
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
|
||||||
|
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
|
||||||
|
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
|
||||||
|
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
|
||||||
|
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
|
||||||
|
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
|
||||||
|
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
|
||||||
|
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
|
||||||
|
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
|
||||||
|
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
|
||||||
|
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
|
||||||
62
docs/modes/index.md
Normal file
@@ -0,0 +1,62 @@
|
|||||||
|
# Ultralytics YOLOv8 Modes
|
||||||
|
|
||||||
|
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||||
|
|
||||||
|
Ultralytics YOLOv8 supports several **modes** that can be used to perform different tasks. These modes are:
|
||||||
|
|
||||||
|
**Train**: For training a YOLOv8 model on a custom dataset.
|
||||||
|
**Val**: For validating a YOLOv8 model after it has been trained.
|
||||||
|
**Predict**: For making predictions using a trained YOLOv8 model on new images or videos.
|
||||||
|
**Export**: For exporting a YOLOv8 model to a format that can be used for deployment.
|
||||||
|
**Track**: For tracking objects in real-time using a YOLOv8 model.
|
||||||
|
**Benchmark**: For benchmarking YOLOv8 exports (ONNX, TensorRT, etc.) speed and accuracy.
|
||||||
|
|
||||||
|
## [Train](train.md)
|
||||||
|
|
||||||
|
Train mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
|
||||||
|
specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
|
||||||
|
accurately predict the classes and locations of objects in an image.
|
||||||
|
|
||||||
|
[Train Examples](train.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Val](val.md)
|
||||||
|
|
||||||
|
Val mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
|
||||||
|
validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
|
||||||
|
of the model to improve its performance.
|
||||||
|
|
||||||
|
[Val Examples](val.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Predict](predict.md)
|
||||||
|
|
||||||
|
Predict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the
|
||||||
|
model is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model
|
||||||
|
predicts the classes and locations of objects in the input images or videos.
|
||||||
|
|
||||||
|
[Predict Examples](predict.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Export](export.md)
|
||||||
|
|
||||||
|
Export mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is
|
||||||
|
converted to a format that can be used by other software applications or hardware devices. This mode is useful when
|
||||||
|
deploying the model to production environments.
|
||||||
|
|
||||||
|
[Export Examples](export.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Track](track.md)
|
||||||
|
|
||||||
|
Track mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a
|
||||||
|
checkpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful
|
||||||
|
for applications such as surveillance systems or self-driving cars.
|
||||||
|
|
||||||
|
[Track Examples](track.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Benchmark](benchmark.md)
|
||||||
|
|
||||||
|
Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide
|
||||||
|
information on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose)
|
||||||
|
or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
|
||||||
|
formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
|
||||||
|
their specific use case based on their requirements for speed and accuracy.
|
||||||
|
|
||||||
|
[Benchmark Examples](benchmark.md){ .md-button .md-button--primary}
|
||||||
276
docs/modes/predict.md
Normal file
@@ -0,0 +1,276 @@
|
|||||||
|
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||||
|
|
||||||
|
YOLOv8 **predict mode** can generate predictions for various tasks, returning either a list of `Results` objects or a
|
||||||
|
memory-efficient generator of `Results` objects when using the streaming mode. Enable streaming mode by
|
||||||
|
passing `stream=True` in the predictor's call method.
|
||||||
|
|
||||||
|
!!! example "Predict"
|
||||||
|
|
||||||
|
=== "Return a list with `Stream=False`"
|
||||||
|
```python
|
||||||
|
inputs = [img, img] # list of numpy arrays
|
||||||
|
results = model(inputs) # list of Results objects
|
||||||
|
|
||||||
|
for result in results:
|
||||||
|
boxes = result.boxes # Boxes object for bbox outputs
|
||||||
|
masks = result.masks # Masks object for segmentation masks outputs
|
||||||
|
probs = result.probs # Class probabilities for classification outputs
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Return a generator with `Stream=True`"
|
||||||
|
```python
|
||||||
|
inputs = [img, img] # list of numpy arrays
|
||||||
|
results = model(inputs, stream=True) # generator of Results objects
|
||||||
|
|
||||||
|
for result in results:
|
||||||
|
boxes = result.boxes # Boxes object for bbox outputs
|
||||||
|
masks = result.masks # Masks object for segmentation masks outputs
|
||||||
|
probs = result.probs # Class probabilities for classification outputs
|
||||||
|
```
|
||||||
|
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
Streaming mode with `stream=True` should be used for long videos or large predict sources, otherwise results will accumuate in memory and will eventually cause out-of-memory errors.
|
||||||
|
|
||||||
|
## Sources
|
||||||
|
|
||||||
|
YOLOv8 can accept various input sources, as shown in the table below. This includes images, URLs, PIL images, OpenCV,
|
||||||
|
numpy arrays, torch tensors, CSV files, videos, directories, globs, YouTube videos, and streams. The table indicates
|
||||||
|
whether each source can be used in streaming mode with `stream=True` ✅ and an example argument for each source.
|
||||||
|
|
||||||
|
| source | model(arg) | type | notes |
|
||||||
|
|-------------|--------------------------------------------|----------------|------------------|
|
||||||
|
| image | `'im.jpg'` | `str`, `Path` | |
|
||||||
|
| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | |
|
||||||
|
| screenshot | `'screen'` | `str` | |
|
||||||
|
| PIL | `Image.open('im.jpg')` | `PIL.Image` | HWC, RGB |
|
||||||
|
| OpenCV | `cv2.imread('im.jpg')[:,:,::-1]` | `np.ndarray` | HWC, BGR to RGB |
|
||||||
|
| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | HWC |
|
||||||
|
| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW, RGB |
|
||||||
|
| CSV | `'sources.csv'` | `str`, `Path` | RTSP, RTMP, HTTP |
|
||||||
|
| video ✅ | `'vid.mp4'` | `str`, `Path` | |
|
||||||
|
| directory ✅ | `'path/'` | `str`, `Path` | |
|
||||||
|
| glob ✅ | `'path/*.jpg'` | `str` | Use `*` operator |
|
||||||
|
| YouTube ✅ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | |
|
||||||
|
| stream ✅ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, HTTP |
|
||||||
|
|
||||||
|
|
||||||
|
## Arguments
|
||||||
|
`model.predict` accepts multiple arguments that control the predction operation. These arguments can be passed directly to `model.predict`:
|
||||||
|
!!! example
|
||||||
|
```
|
||||||
|
model.predict(source, save=True, imgsz=320, conf=0.5)
|
||||||
|
```
|
||||||
|
|
||||||
|
All supported arguments:
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|------------------|------------------------|----------------------------------------------------------|
|
||||||
|
| `source` | `'ultralytics/assets'` | source directory for images or videos |
|
||||||
|
| `conf` | `0.25` | object confidence threshold for detection |
|
||||||
|
| `iou` | `0.7` | intersection over union (IoU) threshold for NMS |
|
||||||
|
| `half` | `False` | use half precision (FP16) |
|
||||||
|
| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
|
||||||
|
| `show` | `False` | show results if possible |
|
||||||
|
| `save` | `False` | save images with results |
|
||||||
|
| `save_txt` | `False` | save results as .txt file |
|
||||||
|
| `save_conf` | `False` | save results with confidence scores |
|
||||||
|
| `save_crop` | `False` | save cropped images with results |
|
||||||
|
| `hide_labels` | `False` | hide labels |
|
||||||
|
| `hide_conf` | `False` | hide confidence scores |
|
||||||
|
| `max_det` | `300` | maximum number of detections per image |
|
||||||
|
| `vid_stride` | `False` | video frame-rate stride |
|
||||||
|
| `line_thickness` | `3` | bounding box thickness (pixels) |
|
||||||
|
| `visualize` | `False` | visualize model features |
|
||||||
|
| `augment` | `False` | apply image augmentation to prediction sources |
|
||||||
|
| `agnostic_nms` | `False` | class-agnostic NMS |
|
||||||
|
| `retina_masks` | `False` | use high-resolution segmentation masks |
|
||||||
|
| `classes` | `None` | filter results by class, i.e. class=0, or class=[0,2,3] |
|
||||||
|
| `boxes` | `True` | Show boxes in segmentation predictions |
|
||||||
|
|
||||||
|
## Image and Video Formats
|
||||||
|
|
||||||
|
YOLOv8 supports various image and video formats, as specified
|
||||||
|
in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). See the
|
||||||
|
tables below for the valid suffixes and example predict commands.
|
||||||
|
|
||||||
|
### Image Suffixes
|
||||||
|
|
||||||
|
| Image Suffixes | Example Predict Command | Reference |
|
||||||
|
|----------------|----------------------------------|-------------------------------------------------------------------------------|
|
||||||
|
| .bmp | `yolo predict source=image.bmp` | [Microsoft BMP File Format](https://en.wikipedia.org/wiki/BMP_file_format) |
|
||||||
|
| .dng | `yolo predict source=image.dng` | [Adobe DNG](https://www.adobe.com/products/photoshop/extend.displayTab2.html) |
|
||||||
|
| .jpeg | `yolo predict source=image.jpeg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
|
||||||
|
| .jpg | `yolo predict source=image.jpg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
|
||||||
|
| .mpo | `yolo predict source=image.mpo` | [Multi Picture Object](https://fileinfo.com/extension/mpo) |
|
||||||
|
| .png | `yolo predict source=image.png` | [Portable Network Graphics](https://en.wikipedia.org/wiki/PNG) |
|
||||||
|
| .tif | `yolo predict source=image.tif` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
|
||||||
|
| .tiff | `yolo predict source=image.tiff` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
|
||||||
|
| .webp | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) |
|
||||||
|
| .pfm | `yolo predict source=image.pfm` | [Portable FloatMap](https://en.wikipedia.org/wiki/Netpbm#File_formats) |
|
||||||
|
|
||||||
|
### Video Suffixes
|
||||||
|
|
||||||
|
| Video Suffixes | Example Predict Command | Reference |
|
||||||
|
|----------------|----------------------------------|----------------------------------------------------------------------------------|
|
||||||
|
| .asf | `yolo predict source=video.asf` | [Advanced Systems Format](https://en.wikipedia.org/wiki/Advanced_Systems_Format) |
|
||||||
|
| .avi | `yolo predict source=video.avi` | [Audio Video Interleave](https://en.wikipedia.org/wiki/Audio_Video_Interleave) |
|
||||||
|
| .gif | `yolo predict source=video.gif` | [Graphics Interchange Format](https://en.wikipedia.org/wiki/GIF) |
|
||||||
|
| .m4v | `yolo predict source=video.m4v` | [MPEG-4 Part 14](https://en.wikipedia.org/wiki/M4V) |
|
||||||
|
| .mkv | `yolo predict source=video.mkv` | [Matroska](https://en.wikipedia.org/wiki/Matroska) |
|
||||||
|
| .mov | `yolo predict source=video.mov` | [QuickTime File Format](https://en.wikipedia.org/wiki/QuickTime_File_Format) |
|
||||||
|
| .mp4 | `yolo predict source=video.mp4` | [MPEG-4 Part 14 - Wikipedia](https://en.wikipedia.org/wiki/MPEG-4_Part_14) |
|
||||||
|
| .mpeg | `yolo predict source=video.mpeg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
|
||||||
|
| .mpg | `yolo predict source=video.mpg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
|
||||||
|
| .ts | `yolo predict source=video.ts` | [MPEG Transport Stream](https://en.wikipedia.org/wiki/MPEG_transport_stream) |
|
||||||
|
| .wmv | `yolo predict source=video.wmv` | [Windows Media Video](https://en.wikipedia.org/wiki/Windows_Media_Video) |
|
||||||
|
| .webm | `yolo predict source=video.webm` | [WebM Project](https://en.wikipedia.org/wiki/WebM) |
|
||||||
|
|
||||||
|
## Working with Results
|
||||||
|
|
||||||
|
The `Results` object contains the following components:
|
||||||
|
|
||||||
|
- `Results.boxes`: `Boxes` object with properties and methods for manipulating bounding boxes
|
||||||
|
- `Results.masks`: `Masks` object for indexing masks or getting segment coordinates
|
||||||
|
- `Results.probs`: `torch.Tensor` containing class probabilities or logits
|
||||||
|
- `Results.orig_img`: Original image loaded in memory
|
||||||
|
- `Results.path`: `Path` containing the path to the input image
|
||||||
|
|
||||||
|
Each result is composed of a `torch.Tensor` by default, which allows for easy manipulation:
|
||||||
|
|
||||||
|
!!! example "Results"
|
||||||
|
|
||||||
|
```python
|
||||||
|
results = results.cuda()
|
||||||
|
results = results.cpu()
|
||||||
|
results = results.to('cpu')
|
||||||
|
results = results.numpy()
|
||||||
|
```
|
||||||
|
|
||||||
|
### Boxes
|
||||||
|
|
||||||
|
`Boxes` object can be used to index, manipulate, and convert bounding boxes to different formats. Box format conversion
|
||||||
|
operations are cached, meaning they're only calculated once per object, and those values are reused for future calls.
|
||||||
|
|
||||||
|
- Indexing a `Boxes` object returns a `Boxes` object:
|
||||||
|
|
||||||
|
!!! example "Boxes"
|
||||||
|
|
||||||
|
```python
|
||||||
|
results = model(img)
|
||||||
|
boxes = results[0].boxes
|
||||||
|
box = boxes[0] # returns one box
|
||||||
|
box.xyxy
|
||||||
|
```
|
||||||
|
|
||||||
|
- Properties and conversions
|
||||||
|
|
||||||
|
!!! example "Boxes Properties"
|
||||||
|
|
||||||
|
```python
|
||||||
|
boxes.xyxy # box with xyxy format, (N, 4)
|
||||||
|
boxes.xywh # box with xywh format, (N, 4)
|
||||||
|
boxes.xyxyn # box with xyxy format but normalized, (N, 4)
|
||||||
|
boxes.xywhn # box with xywh format but normalized, (N, 4)
|
||||||
|
boxes.conf # confidence score, (N, 1)
|
||||||
|
boxes.cls # cls, (N, 1)
|
||||||
|
boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes
|
||||||
|
```
|
||||||
|
|
||||||
|
### Masks
|
||||||
|
|
||||||
|
`Masks` object can be used index, manipulate and convert masks to segments. The segment conversion operation is cached.
|
||||||
|
|
||||||
|
!!! example "Masks"
|
||||||
|
|
||||||
|
```python
|
||||||
|
results = model(inputs)
|
||||||
|
masks = results[0].masks # Masks object
|
||||||
|
masks.xy # x, y segments (pixels), List[segment] * N
|
||||||
|
masks.xyn # x, y segments (normalized), List[segment] * N
|
||||||
|
masks.data # raw masks tensor, (N, H, W) or masks.masks
|
||||||
|
```
|
||||||
|
|
||||||
|
### probs
|
||||||
|
|
||||||
|
`probs` attribute of `Results` class is a `Tensor` containing class probabilities of a classification operation.
|
||||||
|
|
||||||
|
!!! example "Probs"
|
||||||
|
|
||||||
|
```python
|
||||||
|
results = model(inputs)
|
||||||
|
results[0].probs # cls prob, (num_class, )
|
||||||
|
```
|
||||||
|
|
||||||
|
Class reference documentation for `Results` module and its components can be found [here](../reference/results.md)
|
||||||
|
|
||||||
|
## Plotting results
|
||||||
|
|
||||||
|
You can use `plot()` function of `Result` object to plot results on in image object. It plots all components(boxes,
|
||||||
|
masks, classification logits, etc.) found in the results object
|
||||||
|
|
||||||
|
!!! example "Plotting"
|
||||||
|
|
||||||
|
```python
|
||||||
|
res = model(img)
|
||||||
|
res_plotted = res[0].plot()
|
||||||
|
cv2.imshow("result", res_plotted)
|
||||||
|
```
|
||||||
|
| Argument | Description |
|
||||||
|
| ----------- | ------------- |
|
||||||
|
| `conf (bool)` | Whether to plot the detection confidence score. |
|
||||||
|
| `line_width (float, optional)` | The line width of the bounding boxes. If None, it is scaled to the image size. |
|
||||||
|
| `font_size (float, optional)` | The font size of the text. If None, it is scaled to the image size. |
|
||||||
|
| `font (str)` | The font to use for the text. |
|
||||||
|
| `pil (bool)` | Whether to return the image as a PIL Image. |
|
||||||
|
| `example (str)` | An example string to display. Useful for indicating the expected format of the output. |
|
||||||
|
| `img (numpy.ndarray)` | Plot to another image. if not, plot to original image. |
|
||||||
|
| `labels (bool)` | Whether to plot the label of bounding boxes. |
|
||||||
|
| `boxes (bool)` | Whether to plot the bounding boxes. |
|
||||||
|
| `masks (bool)` | Whether to plot the masks. |
|
||||||
|
| `probs (bool)` | Whether to plot classification probability. |
|
||||||
|
|
||||||
|
|
||||||
|
## Streaming Source `for`-loop
|
||||||
|
|
||||||
|
Here's a Python script using OpenCV (cv2) and YOLOv8 to run inference on video frames. This script assumes you have already installed the necessary packages (opencv-python and ultralytics).
|
||||||
|
|
||||||
|
!!! example "Streaming for-loop"
|
||||||
|
|
||||||
|
```python
|
||||||
|
import cv2
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load the YOLOv8 model
|
||||||
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
|
# Open the video file
|
||||||
|
video_path = "path/to/your/video/file.mp4"
|
||||||
|
cap = cv2.VideoCapture(video_path)
|
||||||
|
|
||||||
|
# Loop through the video frames
|
||||||
|
while cap.isOpened():
|
||||||
|
# Read a frame from the video
|
||||||
|
success, frame = cap.read()
|
||||||
|
|
||||||
|
if success:
|
||||||
|
# Run YOLOv8 inference on the frame
|
||||||
|
results = model(frame)
|
||||||
|
|
||||||
|
# Visualize the results on the frame
|
||||||
|
annotated_frame = results[0].plot()
|
||||||
|
|
||||||
|
# Display the annotated frame
|
||||||
|
cv2.imshow("YOLOv8 Inference", annotated_frame)
|
||||||
|
|
||||||
|
# Break the loop if 'q' is pressed
|
||||||
|
if cv2.waitKey(1) & 0xFF == ord("q"):
|
||||||
|
break
|
||||||
|
else:
|
||||||
|
# Break the loop if the end of the video is reached
|
||||||
|
break
|
||||||
|
|
||||||
|
# Release the video capture object and close the display window
|
||||||
|
cap.release()
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
```
|
||||||
96
docs/modes/track.md
Normal file
@@ -0,0 +1,96 @@
|
|||||||
|
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||||
|
|
||||||
|
Object tracking is a task that involves identifying the location and class of objects, then assigning a unique ID to
|
||||||
|
that detection in video streams.
|
||||||
|
|
||||||
|
The output of tracker is the same as detection with an added object ID.
|
||||||
|
|
||||||
|
## Available Trackers
|
||||||
|
|
||||||
|
The following tracking algorithms have been implemented and can be enabled by passing `tracker=tracker_type.yaml`
|
||||||
|
|
||||||
|
* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - `botsort.yaml`
|
||||||
|
* [ByteTrack](https://github.com/ifzhang/ByteTrack) - `bytetrack.yaml`
|
||||||
|
|
||||||
|
The default tracker is BoT-SORT.
|
||||||
|
|
||||||
|
## Tracking
|
||||||
|
|
||||||
|
Use a trained YOLOv8n/YOLOv8n-seg model to run tracker on video streams.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n.pt') # load an official detection model
|
||||||
|
model = YOLO('yolov8n-seg.pt') # load an official segmentation model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Track with the model
|
||||||
|
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
|
||||||
|
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" # official detection model
|
||||||
|
yolo track model=yolov8n-seg.pt source=... # official segmentation model
|
||||||
|
yolo track model=path/to/best.pt source=... # custom model
|
||||||
|
yolo track model=path/to/best.pt tracker="bytetrack.yaml" # bytetrack tracker
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
As in the above usage, we support both the detection and segmentation models for tracking and the only thing you need to
|
||||||
|
do is loading the corresponding (detection or segmentation) model.
|
||||||
|
|
||||||
|
## Configuration
|
||||||
|
|
||||||
|
### Tracking
|
||||||
|
|
||||||
|
Tracking shares the configuration with predict, i.e `conf`, `iou`, `show`. More configurations please refer
|
||||||
|
to [predict page](https://docs.ultralytics.com/modes/predict/).
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
model = YOLO('yolov8n.pt')
|
||||||
|
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
### Tracker
|
||||||
|
|
||||||
|
We also support using a modified tracker config file, just copy a config file i.e `custom_tracker.yaml`
|
||||||
|
from [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg) and modify
|
||||||
|
any configurations(expect the `tracker_type`) you need to.
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
model = YOLO('yolov8n.pt')
|
||||||
|
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", tracker='custom_tracker.yaml')
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" tracker='custom_tracker.yaml'
|
||||||
|
```
|
||||||
|
|
||||||
|
Please refer to [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg)
|
||||||
|
page
|
||||||
|
|
||||||
99
docs/modes/train.md
Normal file
@@ -0,0 +1,99 @@
|
|||||||
|
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||||
|
|
||||||
|
**Train mode** is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
|
||||||
|
specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
|
||||||
|
accurately predict the classes and locations of objects in an image.
|
||||||
|
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
* YOLOv8 datasets like COCO, VOC, ImageNet and many others automatically download on first use, i.e. `yolo train data=coco.yaml`
|
||||||
|
|
||||||
|
## Usage Examples
|
||||||
|
|
||||||
|
Train YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. See Arguments section below for a full list of
|
||||||
|
training arguments.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n.yaml') # build a new model from YAML
|
||||||
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
|
||||||
|
|
||||||
|
# Train the model
|
||||||
|
model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Build a new model from YAML and start training from scratch
|
||||||
|
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
|
||||||
|
|
||||||
|
# Start training from a pretrained *.pt model
|
||||||
|
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||||
|
|
||||||
|
# Build a new model from YAML, transfer pretrained weights to it and start training
|
||||||
|
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
|
||||||
|
```
|
||||||
|
|
||||||
|
## Arguments
|
||||||
|
|
||||||
|
Training settings for YOLO models refer to the various hyperparameters and configurations used to train the model on a
|
||||||
|
dataset. These settings can affect the model's performance, speed, and accuracy. Some common YOLO training settings
|
||||||
|
include the batch size, learning rate, momentum, and weight decay. Other factors that may affect the training process
|
||||||
|
include the choice of optimizer, the choice of loss function, and the size and composition of the training dataset. It
|
||||||
|
is important to carefully tune and experiment with these settings to achieve the best possible performance for a given
|
||||||
|
task.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|-------------------|----------|-----------------------------------------------------------------------------|
|
||||||
|
| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
|
||||||
|
| `data` | `None` | path to data file, i.e. coco128.yaml |
|
||||||
|
| `epochs` | `100` | number of epochs to train for |
|
||||||
|
| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |
|
||||||
|
| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
|
||||||
|
| `imgsz` | `640` | size of input images as integer or w,h |
|
||||||
|
| `save` | `True` | save train checkpoints and predict results |
|
||||||
|
| `save_period` | `-1` | Save checkpoint every x epochs (disabled if < 1) |
|
||||||
|
| `cache` | `False` | True/ram, disk or False. Use cache for data loading |
|
||||||
|
| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
|
||||||
|
| `workers` | `8` | number of worker threads for data loading (per RANK if DDP) |
|
||||||
|
| `project` | `None` | project name |
|
||||||
|
| `name` | `None` | experiment name |
|
||||||
|
| `exist_ok` | `False` | whether to overwrite existing experiment |
|
||||||
|
| `pretrained` | `False` | whether to use a pretrained model |
|
||||||
|
| `optimizer` | `'SGD'` | optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp'] |
|
||||||
|
| `verbose` | `False` | whether to print verbose output |
|
||||||
|
| `seed` | `0` | random seed for reproducibility |
|
||||||
|
| `deterministic` | `True` | whether to enable deterministic mode |
|
||||||
|
| `single_cls` | `False` | train multi-class data as single-class |
|
||||||
|
| `image_weights` | `False` | use weighted image selection for training |
|
||||||
|
| `rect` | `False` | rectangular training with each batch collated for minimum padding |
|
||||||
|
| `cos_lr` | `False` | use cosine learning rate scheduler |
|
||||||
|
| `close_mosaic` | `10` | disable mosaic augmentation for final 10 epochs |
|
||||||
|
| `resume` | `False` | resume training from last checkpoint |
|
||||||
|
| `amp` | `True` | Automatic Mixed Precision (AMP) training, choices=[True, False] |
|
||||||
|
| `lr0` | `0.01` | initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |
|
||||||
|
| `lrf` | `0.01` | final learning rate (lr0 * lrf) |
|
||||||
|
| `momentum` | `0.937` | SGD momentum/Adam beta1 |
|
||||||
|
| `weight_decay` | `0.0005` | optimizer weight decay 5e-4 |
|
||||||
|
| `warmup_epochs` | `3.0` | warmup epochs (fractions ok) |
|
||||||
|
| `warmup_momentum` | `0.8` | warmup initial momentum |
|
||||||
|
| `warmup_bias_lr` | `0.1` | warmup initial bias lr |
|
||||||
|
| `box` | `7.5` | box loss gain |
|
||||||
|
| `cls` | `0.5` | cls loss gain (scale with pixels) |
|
||||||
|
| `dfl` | `1.5` | dfl loss gain |
|
||||||
|
| `pose` | `12.0` | pose loss gain (pose-only) |
|
||||||
|
| `kobj` | `2.0` | keypoint obj loss gain (pose-only) |
|
||||||
|
| `fl_gamma` | `0.0` | focal loss gamma (efficientDet default gamma=1.5) |
|
||||||
|
| `label_smoothing` | `0.0` | label smoothing (fraction) |
|
||||||
|
| `nbs` | `64` | nominal batch size |
|
||||||
|
| `overlap_mask` | `True` | masks should overlap during training (segment train only) |
|
||||||
|
| `mask_ratio` | `4` | mask downsample ratio (segment train only) |
|
||||||
|
| `dropout` | `0.0` | use dropout regularization (classify train only) |
|
||||||
|
| `val` | `True` | validate/test during training |
|
||||||
86
docs/modes/val.md
Normal file
@@ -0,0 +1,86 @@
|
|||||||
|
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||||
|
|
||||||
|
**Val mode** is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
|
||||||
|
validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
|
||||||
|
of the model to improve its performance.
|
||||||
|
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
* YOLOv8 models automatically remember their training settings, so you can validate a model at the same image size and on the original dataset easily with just `yolo val model=yolov8n.pt` or `model('yolov8n.pt').val()`
|
||||||
|
|
||||||
|
## Usage Examples
|
||||||
|
|
||||||
|
Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's
|
||||||
|
training `data` and arguments as model attributes. See Arguments section below for a full list of export arguments.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Validate the model
|
||||||
|
metrics = model.val() # no arguments needed, dataset and settings remembered
|
||||||
|
metrics.box.map # map50-95
|
||||||
|
metrics.box.map50 # map50
|
||||||
|
metrics.box.map75 # map75
|
||||||
|
metrics.box.maps # a list contains map50-95 of each category
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo detect val model=yolov8n.pt # val official model
|
||||||
|
yolo detect val model=path/to/best.pt # val custom model
|
||||||
|
```
|
||||||
|
|
||||||
|
## Arguments
|
||||||
|
|
||||||
|
Validation settings for YOLO models refer to the various hyperparameters and configurations used to
|
||||||
|
evaluate the model's performance on a validation dataset. These settings can affect the model's performance, speed, and
|
||||||
|
accuracy. Some common YOLO validation settings include the batch size, the frequency with which validation is performed
|
||||||
|
during training, and the metrics used to evaluate the model's performance. Other factors that may affect the validation
|
||||||
|
process include the size and composition of the validation dataset and the specific task the model is being used for. It
|
||||||
|
is important to carefully tune and experiment with these settings to ensure that the model is performing well on the
|
||||||
|
validation dataset and to detect and prevent overfitting.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|---------------|---------|--------------------------------------------------------------------|
|
||||||
|
| `data` | `None` | path to data file, i.e. coco128.yaml |
|
||||||
|
| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
|
||||||
|
| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
|
||||||
|
| `save_json` | `False` | save results to JSON file |
|
||||||
|
| `save_hybrid` | `False` | save hybrid version of labels (labels + additional predictions) |
|
||||||
|
| `conf` | `0.001` | object confidence threshold for detection |
|
||||||
|
| `iou` | `0.6` | intersection over union (IoU) threshold for NMS |
|
||||||
|
| `max_det` | `300` | maximum number of detections per image |
|
||||||
|
| `half` | `True` | use half precision (FP16) |
|
||||||
|
| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
|
||||||
|
| `dnn` | `False` | use OpenCV DNN for ONNX inference |
|
||||||
|
| `plots` | `False` | show plots during training |
|
||||||
|
| `rect` | `False` | rectangular val with each batch collated for minimum padding |
|
||||||
|
| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |
|
||||||
|
|
||||||
|
## Export Formats
|
||||||
|
|
||||||
|
Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
|
||||||
|
i.e. `format='onnx'` or `format='engine'`.
|
||||||
|
|
||||||
|
| Format | `format` Argument | Model | Metadata |
|
||||||
|
|--------------------------------------------------------------------|-------------------|---------------------------|----------|
|
||||||
|
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
|
||||||
|
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
|
||||||
|
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
|
||||||
|
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
|
||||||
|
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
|
||||||
|
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
|
||||||
|
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
|
||||||
|
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
|
||||||
|
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
|
||||||
|
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
|
||||||
|
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
|
||||||
|
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
|
||||||
133
docs/quickstart.md
Normal file
@@ -0,0 +1,133 @@
|
|||||||
|
## Install
|
||||||
|
|
||||||
|
Install YOLOv8 via the `ultralytics` pip package for the latest stable release or by cloning
|
||||||
|
the [https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics) repository for the most
|
||||||
|
up-to-date version.
|
||||||
|
|
||||||
|
!!! example "Install"
|
||||||
|
|
||||||
|
=== "pip install (recommended)"
|
||||||
|
```bash
|
||||||
|
pip install ultralytics
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "git clone (for development)"
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ultralytics/ultralytics
|
||||||
|
cd ultralytics
|
||||||
|
pip install -e .
|
||||||
|
```
|
||||||
|
|
||||||
|
See the `ultralytics` [requirements.txt](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) file for a list of dependencies. Note that `pip` automatically installs all required dependencies.
|
||||||
|
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
PyTorch requirements vary by operating system and CUDA requirements, so it's recommended to install PyTorch first following instructions at [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally).
|
||||||
|
|
||||||
|
<a href="https://pytorch.org/get-started/locally/">
|
||||||
|
<img width="100%" alt="PyTorch Installation Instructions" src="https://user-images.githubusercontent.com/26833433/228650108-ab0ec98a-b328-4f40-a40d-95355e8a84e3.png">
|
||||||
|
</a>
|
||||||
|
|
||||||
|
|
||||||
|
## Use with CLI
|
||||||
|
|
||||||
|
The YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment.
|
||||||
|
CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command. Check out the [CLI Guide](usage/cli.md) to learn more about using YOLOv8 from the command line.
|
||||||
|
|
||||||
|
|
||||||
|
!!! example
|
||||||
|
|
||||||
|
=== "Syntax"
|
||||||
|
|
||||||
|
Ultralytics `yolo` commands use the following syntax:
|
||||||
|
```bash
|
||||||
|
yolo TASK MODE ARGS
|
||||||
|
|
||||||
|
Where TASK (optional) is one of [detect, segment, classify]
|
||||||
|
MODE (required) is one of [train, val, predict, export, track]
|
||||||
|
ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
|
||||||
|
```
|
||||||
|
See all ARGS in the full [Configuration Guide](usage/cfg.md) or with `yolo cfg`
|
||||||
|
|
||||||
|
=== "Train"
|
||||||
|
|
||||||
|
Train a detection model for 10 epochs with an initial learning_rate of 0.01
|
||||||
|
```bash
|
||||||
|
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Predict"
|
||||||
|
|
||||||
|
Predict a YouTube video using a pretrained segmentation model at image size 320:
|
||||||
|
```bash
|
||||||
|
yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Val"
|
||||||
|
|
||||||
|
Val a pretrained detection model at batch-size 1 and image size 640:
|
||||||
|
```bash
|
||||||
|
yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Export"
|
||||||
|
|
||||||
|
Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
|
||||||
|
```bash
|
||||||
|
yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Special"
|
||||||
|
|
||||||
|
Run special commands to see version, view settings, run checks and more:
|
||||||
|
```bash
|
||||||
|
yolo help
|
||||||
|
yolo checks
|
||||||
|
yolo version
|
||||||
|
yolo settings
|
||||||
|
yolo copy-cfg
|
||||||
|
yolo cfg
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
!!! warning "Warning"
|
||||||
|
|
||||||
|
Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` beteen arguments.
|
||||||
|
|
||||||
|
- `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
|
||||||
|
- `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌
|
||||||
|
- `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌
|
||||||
|
|
||||||
|
[CLI Guide](usage/cli.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## Use with Python
|
||||||
|
|
||||||
|
YOLOv8's Python interface allows for seamless integration into your Python projects, making it easy to load, run, and process the model's output. Designed with simplicity and ease of use in mind, the Python interface enables users to quickly implement object detection, segmentation, and classification in their projects. This makes YOLOv8's Python interface an invaluable tool for anyone looking to incorporate these functionalities into their Python projects.
|
||||||
|
|
||||||
|
For example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX format with just a few lines of code. Check out the [Python Guide](usage/python.md) to learn more about using YOLOv8 within your Python projects.
|
||||||
|
|
||||||
|
!!! example
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Create a new YOLO model from scratch
|
||||||
|
model = YOLO('yolov8n.yaml')
|
||||||
|
|
||||||
|
# Load a pretrained YOLO model (recommended for training)
|
||||||
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
|
# Train the model using the 'coco128.yaml' dataset for 3 epochs
|
||||||
|
results = model.train(data='coco128.yaml', epochs=3)
|
||||||
|
|
||||||
|
# Evaluate the model's performance on the validation set
|
||||||
|
results = model.val()
|
||||||
|
|
||||||
|
# Perform object detection on an image using the model
|
||||||
|
results = model('https://ultralytics.com/images/bus.jpg')
|
||||||
|
|
||||||
|
# Export the model to ONNX format
|
||||||
|
success = model.export(format='onnx')
|
||||||
|
```
|
||||||
|
|
||||||
|
[Python Guide](usage/python.md){.md-button .md-button--primary}
|
||||||
8
docs/reference/base_pred.md
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
All task Predictors are inherited from `BasePredictors` class that contains the model validation routine boilerplate.
|
||||||
|
You can override any function of these Trainers to suit your needs.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### BasePredictor API Reference
|
||||||
|
|
||||||
|
:::ultralytics.yolo.engine.predictor.BasePredictor
|
||||||
8
docs/reference/base_trainer.md
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
All task Trainers are inherited from `BaseTrainer` class that contains the model training and optimization routine
|
||||||
|
boilerplate. You can override any function of these Trainers to suit your needs.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### BaseTrainer API Reference
|
||||||
|
|
||||||
|
:::ultralytics.yolo.engine.trainer.BaseTrainer
|
||||||
8
docs/reference/base_val.md
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
All task Validators are inherited from `BaseValidator` class that contains the model validation routine boilerplate. You
|
||||||
|
can override any function of these Trainers to suit your needs.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### BaseValidator API Reference
|
||||||
|
|
||||||
|
:::ultralytics.yolo.engine.validator.BaseValidator
|
||||||
3
docs/reference/exporter.md
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
### Exporter API Reference
|
||||||
|
|
||||||
|
:::ultralytics.yolo.engine.exporter.Exporter
|
||||||
1
docs/reference/model.md
Normal file
@@ -0,0 +1 @@
|
|||||||
|
::: ultralytics.yolo.engine.model
|
||||||
19
docs/reference/nn.md
Normal file
@@ -0,0 +1,19 @@
|
|||||||
|
# nn Module
|
||||||
|
|
||||||
|
Ultralytics nn module contains 3 main components:
|
||||||
|
|
||||||
|
1. **AutoBackend**: A module that can run inference on all popular model formats
|
||||||
|
2. **BaseModel**: `BaseModel` class defines the operations supported by tasks like Detection and Segmentation
|
||||||
|
3. **modules**: Optimized and reusable neural network blocks built on PyTorch.
|
||||||
|
|
||||||
|
## AutoBackend
|
||||||
|
|
||||||
|
:::ultralytics.nn.autobackend.AutoBackend
|
||||||
|
|
||||||
|
## BaseModel
|
||||||
|
|
||||||
|
:::ultralytics.nn.tasks.BaseModel
|
||||||
|
|
||||||
|
## Modules
|
||||||
|
|
||||||
|
TODO
|
||||||
208
docs/reference/ops.md
Normal file
@@ -0,0 +1,208 @@
|
|||||||
|
This module contains optimized deep learning related operations used in the Ultralytics YOLO framework
|
||||||
|
|
||||||
|
## Non-max suppression
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.non_max_suppression
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## Scale boxes
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.scale_boxes
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## Scale image
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.scale_image
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## clip boxes
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.clip_boxes
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
# Box Format Conversion
|
||||||
|
|
||||||
|
## xyxy2xywh
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.xyxy2xywh
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## xywh2xyxy
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.xywh2xyxy
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## xywhn2xyxy
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.xywhn2xyxy
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## xyxy2xywhn
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.xyxy2xywhn
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## xyn2xy
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.xyn2xy
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## xywh2ltwh
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.xywh2ltwh
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## xyxy2ltwh
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.xyxy2ltwh
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## ltwh2xywh
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.ltwh2xywh
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## ltwh2xyxy
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.ltwh2xyxy
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## segment2box
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.segment2box
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
# Mask Operations
|
||||||
|
|
||||||
|
## resample_segments
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.resample_segments
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## crop_mask
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.crop_mask
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## process_mask_upsample
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.process_mask_upsample
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## process_mask
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.process_mask
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## process_mask_native
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.process_mask_native
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## scale_coords
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.scale_coords
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## masks2segments
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.masks2segments
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
## clip_coords
|
||||||
|
|
||||||
|
:::ultralytics.yolo.utils.ops.clip_coords
|
||||||
|
handler: python
|
||||||
|
options:
|
||||||
|
show_source: false
|
||||||
|
show_root_toc_entry: false
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
11
docs/reference/results.md
Normal file
@@ -0,0 +1,11 @@
|
|||||||
|
### Results API Reference
|
||||||
|
|
||||||
|
:::ultralytics.yolo.engine.results.Results
|
||||||
|
|
||||||
|
### Boxes API Reference
|
||||||
|
|
||||||
|
:::ultralytics.yolo.engine.results.Boxes
|
||||||
|
|
||||||
|
### Masks API Reference
|
||||||
|
|
||||||
|
:::ultralytics.yolo.engine.results.Masks
|
||||||
170
docs/tasks/classify.md
Normal file
@@ -0,0 +1,170 @@
|
|||||||
|
Image classification is the simplest of the three tasks and involves classifying an entire image into one of a set of
|
||||||
|
predefined classes.
|
||||||
|
|
||||||
|
<img width="1024" src="https://user-images.githubusercontent.com/26833433/212094133-6bb8c21c-3d47-41df-a512-81c5931054ae.png">
|
||||||
|
|
||||||
|
The output of an image classifier is a single class label and a confidence score. Image
|
||||||
|
classification is useful when you need to know only what class an image belongs to and don't need to know where objects
|
||||||
|
of that class are located or what their exact shape is.
|
||||||
|
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
YOLOv8 Classify models use the `-cls` suffix, i.e. `yolov8n-cls.pt` and are pretrained on [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml).
|
||||||
|
|
||||||
|
## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
|
||||||
|
|
||||||
|
YOLOv8 pretrained Classify models are shown here. Detect, Segment and Pose models are pretrained on
|
||||||
|
the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
|
||||||
|
models are pretrained on
|
||||||
|
the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
|
||||||
|
|
||||||
|
[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
|
||||||
|
Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
|
||||||
|
|
||||||
|
| Model | size<br><sup>(pixels) | acc<br><sup>top1 | acc<br><sup>top5 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) at 640 |
|
||||||
|
|----------------------------------------------------------------------------------------------|-----------------------|------------------|------------------|--------------------------------|-------------------------------------|--------------------|--------------------------|
|
||||||
|
| [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-cls.pt) | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
|
||||||
|
| [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-cls.pt) | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
|
||||||
|
| [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-cls.pt) | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
|
||||||
|
| [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-cls.pt) | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
|
||||||
|
| [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-cls.pt) | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
|
||||||
|
|
||||||
|
- **acc** values are model accuracies on the [ImageNet](https://www.image-net.org/) dataset validation set.
|
||||||
|
<br>Reproduce by `yolo val classify data=path/to/ImageNet device=0`
|
||||||
|
- **Speed** averaged over ImageNet val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
|
||||||
|
instance.
|
||||||
|
<br>Reproduce by `yolo val classify data=path/to/ImageNet batch=1 device=0|cpu`
|
||||||
|
|
||||||
|
## Train
|
||||||
|
|
||||||
|
Train YOLOv8n-cls on the MNIST160 dataset for 100 epochs at image size 64. For a full list of available arguments
|
||||||
|
see the [Configuration](../usage/cfg.md) page.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n-cls.yaml') # build a new model from YAML
|
||||||
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
model = YOLO('yolov8n-cls.yaml').load('yolov8n-cls.pt') # build from YAML and transfer weights
|
||||||
|
|
||||||
|
# Train the model
|
||||||
|
model.train(data='mnist160', epochs=100, imgsz=64)
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Build a new model from YAML and start training from scratch
|
||||||
|
yolo classify train data=mnist160 model=yolov8n-cls.yaml epochs=100 imgsz=64
|
||||||
|
|
||||||
|
# Start training from a pretrained *.pt model
|
||||||
|
yolo classify train data=mnist160 model=yolov8n-cls.pt epochs=100 imgsz=64
|
||||||
|
|
||||||
|
# Build a new model from YAML, transfer pretrained weights to it and start training
|
||||||
|
yolo classify train data=mnist160 model=yolov8n-cls.yaml pretrained=yolov8n-cls.pt epochs=100 imgsz=64
|
||||||
|
```
|
||||||
|
|
||||||
|
## Val
|
||||||
|
|
||||||
|
Validate trained YOLOv8n-cls model accuracy on the MNIST160 dataset. No argument need to passed as the `model` retains
|
||||||
|
it's training `data` and arguments as model attributes.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n-cls.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Validate the model
|
||||||
|
metrics = model.val() # no arguments needed, dataset and settings remembered
|
||||||
|
metrics.top1 # top1 accuracy
|
||||||
|
metrics.top5 # top5 accuracy
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo classify val model=yolov8n-cls.pt # val official model
|
||||||
|
yolo classify val model=path/to/best.pt # val custom model
|
||||||
|
```
|
||||||
|
|
||||||
|
## Predict
|
||||||
|
|
||||||
|
Use a trained YOLOv8n-cls model to run predictions on images.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n-cls.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Predict with the model
|
||||||
|
results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo classify predict model=yolov8n-cls.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
|
||||||
|
yolo classify predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
|
||||||
|
```
|
||||||
|
|
||||||
|
See full `predict` mode details in the [Predict](https://docs.ultralytics.com/modes/predict/) page.
|
||||||
|
|
||||||
|
## Export
|
||||||
|
|
||||||
|
Export a YOLOv8n-cls model to a different format like ONNX, CoreML, etc.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n-cls.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom trained
|
||||||
|
|
||||||
|
# Export the model
|
||||||
|
model.export(format='onnx')
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo export model=yolov8n-cls.pt format=onnx # export official model
|
||||||
|
yolo export model=path/to/best.pt format=onnx # export custom trained model
|
||||||
|
```
|
||||||
|
|
||||||
|
Available YOLOv8-cls export formats are in the table below. You can predict or validate directly on exported models,
|
||||||
|
i.e. `yolo predict model=yolov8n-cls.onnx`. Usage examples are shown for your model after export completes.
|
||||||
|
|
||||||
|
| Format | `format` Argument | Model | Metadata |
|
||||||
|
|--------------------------------------------------------------------|-------------------|-------------------------------|----------|
|
||||||
|
| [PyTorch](https://pytorch.org/) | - | `yolov8n-cls.pt` | ✅ |
|
||||||
|
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-cls.torchscript` | ✅ |
|
||||||
|
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-cls.onnx` | ✅ |
|
||||||
|
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-cls_openvino_model/` | ✅ |
|
||||||
|
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-cls.engine` | ✅ |
|
||||||
|
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-cls.mlmodel` | ✅ |
|
||||||
|
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-cls_saved_model/` | ✅ |
|
||||||
|
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-cls.pb` | ❌ |
|
||||||
|
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-cls.tflite` | ✅ |
|
||||||
|
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-cls_edgetpu.tflite` | ✅ |
|
||||||
|
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-cls_web_model/` | ✅ |
|
||||||
|
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-cls_paddle_model/` | ✅ |
|
||||||
|
|
||||||
|
See full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page.
|
||||||
171
docs/tasks/detect.md
Normal file
@@ -0,0 +1,171 @@
|
|||||||
|
Object detection is a task that involves identifying the location and class of objects in an image or video stream.
|
||||||
|
|
||||||
|
<img width="1024" src="https://user-images.githubusercontent.com/26833433/212094133-6bb8c21c-3d47-41df-a512-81c5931054ae.png">
|
||||||
|
|
||||||
|
The output of an object detector is a set of bounding boxes that enclose the objects in the image, along with class
|
||||||
|
labels
|
||||||
|
and confidence scores for each box. Object detection is a good choice when you need to identify objects of interest in a
|
||||||
|
scene, but don't need to know exactly where the object is or its exact shape.
|
||||||
|
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
YOLOv8 Detect models are the default YOLOv8 models, i.e. `yolov8n.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).
|
||||||
|
|
||||||
|
## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
|
||||||
|
|
||||||
|
YOLOv8 pretrained Detect models are shown here. Detect, Segment and Pose models are pretrained on
|
||||||
|
the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
|
||||||
|
models are pretrained on
|
||||||
|
the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
|
||||||
|
|
||||||
|
[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
|
||||||
|
Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
|
||||||
|
|
||||||
|
| Model | size<br><sup>(pixels) | mAP<sup>val<br>50-95 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||||
|
|--------------------------------------------------------------------------------------|-----------------------|----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
|
||||||
|
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
|
||||||
|
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
|
||||||
|
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
|
||||||
|
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
|
||||||
|
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
|
||||||
|
|
||||||
|
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset.
|
||||||
|
<br>Reproduce by `yolo val detect data=coco.yaml device=0`
|
||||||
|
- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
|
||||||
|
instance.
|
||||||
|
<br>Reproduce by `yolo val detect data=coco128.yaml batch=1 device=0|cpu`
|
||||||
|
|
||||||
|
## Train
|
||||||
|
|
||||||
|
Train YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. For a full list of available arguments see
|
||||||
|
the [Configuration](../usage/cfg.md) page.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n.yaml') # build a new model from YAML
|
||||||
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
|
||||||
|
|
||||||
|
# Train the model
|
||||||
|
model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Build a new model from YAML and start training from scratch
|
||||||
|
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
|
||||||
|
|
||||||
|
# Start training from a pretrained *.pt model
|
||||||
|
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||||
|
|
||||||
|
# Build a new model from YAML, transfer pretrained weights to it and start training
|
||||||
|
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
|
||||||
|
```
|
||||||
|
|
||||||
|
## Val
|
||||||
|
|
||||||
|
Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's
|
||||||
|
training `data` and arguments as model attributes.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Validate the model
|
||||||
|
metrics = model.val() # no arguments needed, dataset and settings remembered
|
||||||
|
metrics.box.map # map50-95
|
||||||
|
metrics.box.map50 # map50
|
||||||
|
metrics.box.map75 # map75
|
||||||
|
metrics.box.maps # a list contains map50-95 of each category
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo detect val model=yolov8n.pt # val official model
|
||||||
|
yolo detect val model=path/to/best.pt # val custom model
|
||||||
|
```
|
||||||
|
|
||||||
|
## Predict
|
||||||
|
|
||||||
|
Use a trained YOLOv8n model to run predictions on images.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Predict with the model
|
||||||
|
results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
|
||||||
|
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
|
||||||
|
```
|
||||||
|
|
||||||
|
See full `predict` mode details in the [Predict](https://docs.ultralytics.com/modes/predict/) page.
|
||||||
|
|
||||||
|
## Export
|
||||||
|
|
||||||
|
Export a YOLOv8n model to a different format like ONNX, CoreML, etc.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom trained
|
||||||
|
|
||||||
|
# Export the model
|
||||||
|
model.export(format='onnx')
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo export model=yolov8n.pt format=onnx # export official model
|
||||||
|
yolo export model=path/to/best.pt format=onnx # export custom trained model
|
||||||
|
```
|
||||||
|
|
||||||
|
Available YOLOv8 export formats are in the table below. You can predict or validate directly on exported models,
|
||||||
|
i.e. `yolo predict model=yolov8n.onnx`. Usage examples are shown for your model after export completes.
|
||||||
|
|
||||||
|
| Format | `format` Argument | Model | Metadata |
|
||||||
|
|--------------------------------------------------------------------|-------------------|---------------------------|----------|
|
||||||
|
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
|
||||||
|
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
|
||||||
|
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
|
||||||
|
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
|
||||||
|
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
|
||||||
|
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
|
||||||
|
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
|
||||||
|
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
|
||||||
|
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
|
||||||
|
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
|
||||||
|
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
|
||||||
|
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
|
||||||
|
|
||||||
|
See full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page.
|
||||||
44
docs/tasks/index.md
Normal file
@@ -0,0 +1,44 @@
|
|||||||
|
# Ultralytics YOLOv8 Tasks
|
||||||
|
|
||||||
|
YOLOv8 is an AI framework that supports multiple computer vision **tasks**. The framework can be used to
|
||||||
|
perform [detection](detect.md), [segmentation](segment.md), [classification](classify.md),
|
||||||
|
and [pose](pose.md) estimation. Each of these tasks has a different objective and use case.
|
||||||
|
|
||||||
|
<img width="1024" src="https://user-images.githubusercontent.com/26833433/212094133-6bb8c21c-3d47-41df-a512-81c5931054ae.png">
|
||||||
|
|
||||||
|
## [Detection](detect.md)
|
||||||
|
|
||||||
|
Detection is the primary task supported by YOLOv8. It involves detecting objects in an image or video frame and drawing
|
||||||
|
bounding boxes around them. The detected objects are classified into different categories based on their features.
|
||||||
|
YOLOv8 can detect multiple objects in a single image or video frame with high accuracy and speed.
|
||||||
|
|
||||||
|
[Detection Examples](detect.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Segmentation](segment.md)
|
||||||
|
|
||||||
|
Segmentation is a task that involves segmenting an image into different regions based on the content of the image. Each
|
||||||
|
region is assigned a label based on its content. This task is useful in applications such as image segmentation and
|
||||||
|
medical imaging. YOLOv8 uses a variant of the U-Net architecture to perform segmentation.
|
||||||
|
|
||||||
|
[Segmentation Examples](segment.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Classification](classify.md)
|
||||||
|
|
||||||
|
Classification is a task that involves classifying an image into different categories. YOLOv8 can be used to classify
|
||||||
|
images based on their content. It uses a variant of the EfficientNet architecture to perform classification.
|
||||||
|
|
||||||
|
[Classification Examples](classify.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Pose](pose.md)
|
||||||
|
|
||||||
|
Pose/keypoint detection is a task that involves detecting specific points in an image or video frame. These points are
|
||||||
|
referred to as keypoints and are used to track movement or pose estimation. YOLOv8 can detect keypoints in an image or
|
||||||
|
video frame with high accuracy and speed.
|
||||||
|
|
||||||
|
[Pose Examples](pose.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
YOLOv8 supports multiple tasks, including detection, segmentation, classification, and keypoints detection. Each of
|
||||||
|
these tasks has different objectives and use cases. By understanding the differences between these tasks, you can choose
|
||||||
|
the appropriate task for your computer vision application.
|
||||||
175
docs/tasks/pose.md
Normal file
@@ -0,0 +1,175 @@
|
|||||||
|
Pose estimation is a task that involves identifying the location of specific points in an image, usually referred
|
||||||
|
to as keypoints. The keypoints can represent various parts of the object such as joints, landmarks, or other distinctive
|
||||||
|
features. The locations of the keypoints are usually represented as a set of 2D `[x, y]` or 3D `[x, y, visible]`
|
||||||
|
coordinates.
|
||||||
|
|
||||||
|
<img width="1024" src="https://user-images.githubusercontent.com/26833433/212094133-6bb8c21c-3d47-41df-a512-81c5931054ae.png">
|
||||||
|
|
||||||
|
The output of a pose estimation model is a set of points that represent the keypoints on an object in the image, usually
|
||||||
|
along with the confidence scores for each point. Pose estimation is a good choice when you need to identify specific
|
||||||
|
parts of an object in a scene, and their location in relation to each other.
|
||||||
|
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
YOLOv8 _pose_ models use the `-pose` suffix, i.e. `yolov8n-pose.pt`. These models are trained on the [COCO keypoints](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco-pose.yaml) dataset and are suitable for a variety of pose estimation tasks.
|
||||||
|
|
||||||
|
## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
|
||||||
|
|
||||||
|
YOLOv8 pretrained Pose models are shown here. Detect, Segment and Pose models are pretrained on
|
||||||
|
the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
|
||||||
|
models are pretrained on
|
||||||
|
the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
|
||||||
|
|
||||||
|
[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
|
||||||
|
Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
|
||||||
|
|
||||||
|
| Model | size<br><sup>(pixels) | mAP<sup>box<br>50-95 | mAP<sup>pose<br>50-95 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||||
|
|------------------------------------------------------------------------------------------------------|-----------------------|----------------------|-----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
|
||||||
|
| [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-pose.pt) | 640 | - | 49.7 | - | - | 3.3 | 9.2 |
|
||||||
|
| [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-pose.pt) | 640 | - | 59.2 | - | - | 11.6 | 30.2 |
|
||||||
|
| [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-pose.pt) | 640 | - | 63.6 | - | - | 26.4 | 81.0 |
|
||||||
|
| [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-pose.pt) | 640 | - | 67.0 | - | - | 44.4 | 168.6 |
|
||||||
|
| [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose.pt) | 640 | - | 68.9 | - | - | 69.4 | 263.2 |
|
||||||
|
| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose-p6.pt) | 1280 | - | 71.5 | - | - | 99.1 | 1066.4 |
|
||||||
|
|
||||||
|
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO Keypoints val2017](http://cocodataset.org)
|
||||||
|
dataset.
|
||||||
|
<br>Reproduce by `yolo val pose data=coco-pose.yaml device=0`
|
||||||
|
- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
|
||||||
|
instance.
|
||||||
|
<br>Reproduce by `yolo val pose data=coco8-pose.yaml batch=1 device=0|cpu`
|
||||||
|
|
||||||
|
## Train
|
||||||
|
|
||||||
|
Train a YOLOv8-pose model on the COCO128-pose dataset.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n-pose.yaml') # build a new model from YAML
|
||||||
|
model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
|
||||||
|
model = YOLO('yolov8n-pose.yaml').load('yolov8n-pose.pt') # build from YAML and transfer weights
|
||||||
|
|
||||||
|
# Train the model
|
||||||
|
model.train(data='coco128-pose.yaml', epochs=100, imgsz=640)
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Build a new model from YAML and start training from scratch
|
||||||
|
yolo detect train data=coco128-pose.yaml model=yolov8n-pose.yaml epochs=100 imgsz=640
|
||||||
|
|
||||||
|
# Start training from a pretrained *.pt model
|
||||||
|
yolo detect train data=coco128-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
|
||||||
|
|
||||||
|
# Build a new model from YAML, transfer pretrained weights to it and start training
|
||||||
|
yolo detect train data=coco128-pose.yaml model=yolov8n-pose.yaml pretrained=yolov8n-pose.pt epochs=100 imgsz=640
|
||||||
|
```
|
||||||
|
|
||||||
|
## Val
|
||||||
|
|
||||||
|
Validate trained YOLOv8n-pose model accuracy on the COCO128-pose dataset. No argument need to passed as the `model`
|
||||||
|
retains it's
|
||||||
|
training `data` and arguments as model attributes.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n-pose.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Validate the model
|
||||||
|
metrics = model.val() # no arguments needed, dataset and settings remembered
|
||||||
|
metrics.box.map # map50-95
|
||||||
|
metrics.box.map50 # map50
|
||||||
|
metrics.box.map75 # map75
|
||||||
|
metrics.box.maps # a list contains map50-95 of each category
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo pose val model=yolov8n-pose.pt # val official model
|
||||||
|
yolo pose val model=path/to/best.pt # val custom model
|
||||||
|
```
|
||||||
|
|
||||||
|
## Predict
|
||||||
|
|
||||||
|
Use a trained YOLOv8n-pose model to run predictions on images.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n-pose.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Predict with the model
|
||||||
|
results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo pose predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
|
||||||
|
yolo pose predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
|
||||||
|
```
|
||||||
|
|
||||||
|
See full `predict` mode details in the [Predict](https://docs.ultralytics.com/modes/predict/) page.
|
||||||
|
|
||||||
|
## Export
|
||||||
|
|
||||||
|
Export a YOLOv8n model to a different format like ONNX, CoreML, etc.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom trained
|
||||||
|
|
||||||
|
# Export the model
|
||||||
|
model.export(format='onnx')
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo export model=yolov8n.pt format=onnx # export official model
|
||||||
|
yolo export model=path/to/best.pt format=onnx # export custom trained model
|
||||||
|
```
|
||||||
|
|
||||||
|
Available YOLOv8-pose export formats are in the table below. You can predict or validate directly on exported models,
|
||||||
|
i.e. `yolo predict model=yolov8n-pose.onnx`. Usage examples are shown for your model after export completes.
|
||||||
|
|
||||||
|
| Format | `format` Argument | Model | Metadata |
|
||||||
|
|--------------------------------------------------------------------|-------------------|--------------------------------|----------|
|
||||||
|
| [PyTorch](https://pytorch.org/) | - | `yolov8n-pose.pt` | ✅ |
|
||||||
|
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-pose.torchscript` | ✅ |
|
||||||
|
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-pose.onnx` | ✅ |
|
||||||
|
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-pose_openvino_model/` | ✅ |
|
||||||
|
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-pose.engine` | ✅ |
|
||||||
|
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-pose.mlmodel` | ✅ |
|
||||||
|
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-pose_saved_model/` | ✅ |
|
||||||
|
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-pose.pb` | ❌ |
|
||||||
|
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-pose.tflite` | ✅ |
|
||||||
|
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-pose_edgetpu.tflite` | ✅ |
|
||||||
|
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-pose_web_model/` | ✅ |
|
||||||
|
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-pose_paddle_model/` | ✅ |
|
||||||
|
|
||||||
|
See full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page.
|
||||||
175
docs/tasks/segment.md
Normal file
@@ -0,0 +1,175 @@
|
|||||||
|
Instance segmentation goes a step further than object detection and involves identifying individual objects in an image
|
||||||
|
and segmenting them from the rest of the image.
|
||||||
|
|
||||||
|
<img width="1024" src="https://user-images.githubusercontent.com/26833433/212094133-6bb8c21c-3d47-41df-a512-81c5931054ae.png">
|
||||||
|
|
||||||
|
The output of an instance segmentation model is a set of masks or
|
||||||
|
contours that outline each object in the image, along with class labels and confidence scores for each object. Instance
|
||||||
|
segmentation is useful when you need to know not only where objects are in an image, but also what their exact shape is.
|
||||||
|
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
YOLOv8 Segment models use the `-seg` suffix, i.e. `yolov8n-seg.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).
|
||||||
|
|
||||||
|
## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
|
||||||
|
|
||||||
|
YOLOv8 pretrained Segment models are shown here. Detect, Segment and Pose models are pretrained on
|
||||||
|
the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
|
||||||
|
models are pretrained on
|
||||||
|
the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
|
||||||
|
|
||||||
|
[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
|
||||||
|
Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
|
||||||
|
|
||||||
|
| Model | size<br><sup>(pixels) | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||||
|
|----------------------------------------------------------------------------------------------|-----------------------|----------------------|-----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
|
||||||
|
| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
|
||||||
|
| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
|
||||||
|
| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
|
||||||
|
| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
|
||||||
|
| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
|
||||||
|
|
||||||
|
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset.
|
||||||
|
<br>Reproduce by `yolo val segment data=coco.yaml device=0`
|
||||||
|
- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
|
||||||
|
instance.
|
||||||
|
<br>Reproduce by `yolo val segment data=coco128-seg.yaml batch=1 device=0|cpu`
|
||||||
|
|
||||||
|
## Train
|
||||||
|
|
||||||
|
Train YOLOv8n-seg on the COCO128-seg dataset for 100 epochs at image size 640. For a full list of available
|
||||||
|
arguments see the [Configuration](../usage/cfg.md) page.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n-seg.yaml') # build a new model from YAML
|
||||||
|
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
|
||||||
|
model = YOLO('yolov8n-seg.yaml').load('yolov8n.pt') # build from YAML and transfer weights
|
||||||
|
|
||||||
|
# Train the model
|
||||||
|
model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Build a new model from YAML and start training from scratch
|
||||||
|
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.yaml epochs=100 imgsz=640
|
||||||
|
|
||||||
|
# Start training from a pretrained *.pt model
|
||||||
|
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
|
||||||
|
|
||||||
|
# Build a new model from YAML, transfer pretrained weights to it and start training
|
||||||
|
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.yaml pretrained=yolov8n-seg.pt epochs=100 imgsz=640
|
||||||
|
```
|
||||||
|
|
||||||
|
## Val
|
||||||
|
|
||||||
|
Validate trained YOLOv8n-seg model accuracy on the COCO128-seg dataset. No argument need to passed as the `model`
|
||||||
|
retains it's training `data` and arguments as model attributes.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n-seg.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Validate the model
|
||||||
|
metrics = model.val() # no arguments needed, dataset and settings remembered
|
||||||
|
metrics.box.map # map50-95(B)
|
||||||
|
metrics.box.map50 # map50(B)
|
||||||
|
metrics.box.map75 # map75(B)
|
||||||
|
metrics.box.maps # a list contains map50-95(B) of each category
|
||||||
|
metrics.seg.map # map50-95(M)
|
||||||
|
metrics.seg.map50 # map50(M)
|
||||||
|
metrics.seg.map75 # map75(M)
|
||||||
|
metrics.seg.maps # a list contains map50-95(M) of each category
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo segment val model=yolov8n-seg.pt # val official model
|
||||||
|
yolo segment val model=path/to/best.pt # val custom model
|
||||||
|
```
|
||||||
|
|
||||||
|
## Predict
|
||||||
|
|
||||||
|
Use a trained YOLOv8n-seg model to run predictions on images.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n-seg.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Predict with the model
|
||||||
|
results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
|
||||||
|
yolo segment predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
|
||||||
|
```
|
||||||
|
|
||||||
|
See full `predict` mode details in the [Predict](https://docs.ultralytics.com/modes/predict/) page.
|
||||||
|
|
||||||
|
## Export
|
||||||
|
|
||||||
|
Export a YOLOv8n-seg model to a different format like ONNX, CoreML, etc.
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n-seg.pt') # load an official model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom trained
|
||||||
|
|
||||||
|
# Export the model
|
||||||
|
model.export(format='onnx')
|
||||||
|
```
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo export model=yolov8n-seg.pt format=onnx # export official model
|
||||||
|
yolo export model=path/to/best.pt format=onnx # export custom trained model
|
||||||
|
```
|
||||||
|
|
||||||
|
Available YOLOv8-seg export formats are in the table below. You can predict or validate directly on exported models,
|
||||||
|
i.e. `yolo predict model=yolov8n-seg.onnx`. Usage examples are shown for your model after export completes.
|
||||||
|
|
||||||
|
| Format | `format` Argument | Model | Metadata |
|
||||||
|
|--------------------------------------------------------------------|-------------------|-------------------------------|----------|
|
||||||
|
| [PyTorch](https://pytorch.org/) | - | `yolov8n-seg.pt` | ✅ |
|
||||||
|
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-seg.torchscript` | ✅ |
|
||||||
|
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-seg.onnx` | ✅ |
|
||||||
|
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-seg_openvino_model/` | ✅ |
|
||||||
|
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-seg.engine` | ✅ |
|
||||||
|
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-seg.mlmodel` | ✅ |
|
||||||
|
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-seg_saved_model/` | ✅ |
|
||||||
|
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-seg.pb` | ❌ |
|
||||||
|
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-seg.tflite` | ✅ |
|
||||||
|
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-seg_edgetpu.tflite` | ✅ |
|
||||||
|
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-seg_web_model/` | ✅ |
|
||||||
|
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-seg_paddle_model/` | ✅ |
|
||||||
|
|
||||||
|
See full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page.
|
||||||
85
docs/usage/callbacks.md
Normal file
@@ -0,0 +1,85 @@
|
|||||||
|
## Callbacks
|
||||||
|
|
||||||
|
Ultralytics framework supports callbacks as entry points in strategic stages of train, val, export, and predict modes.
|
||||||
|
Each callback accepts a `Trainer`, `Validator`, or `Predictor` object depending on the operation type. All properties of
|
||||||
|
these objects can be found in Reference section of the docs.
|
||||||
|
|
||||||
|
## Examples
|
||||||
|
|
||||||
|
### Returning additional information with Prediction
|
||||||
|
|
||||||
|
In this example, we want to return the original frame with each result object. Here's how we can do that
|
||||||
|
|
||||||
|
```python
|
||||||
|
def on_predict_batch_end(predictor):
|
||||||
|
# Retrieve the batch data
|
||||||
|
_, _, im0s, _, _ = predictor.batch
|
||||||
|
|
||||||
|
# Ensure that im0s is a list
|
||||||
|
im0s = im0s if isinstance(im0s, list) else [im0s]
|
||||||
|
|
||||||
|
# Combine the prediction results with the corresponding frames
|
||||||
|
predictor.results = zip(predictor.results, im0s)
|
||||||
|
|
||||||
|
# Create a YOLO model instance
|
||||||
|
model = YOLO(f'yolov8n.pt')
|
||||||
|
|
||||||
|
# Add the custom callback to the model
|
||||||
|
model.add_callback("on_predict_batch_end", on_predict_batch_end)
|
||||||
|
|
||||||
|
# Iterate through the results and frames
|
||||||
|
for (result, frame) in model.track/predict():
|
||||||
|
pass
|
||||||
|
```
|
||||||
|
|
||||||
|
## All callbacks
|
||||||
|
|
||||||
|
Here are all supported callbacks. See callbacks [source code](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/utils/callbacks/base.py) for additional details.
|
||||||
|
|
||||||
|
|
||||||
|
### Trainer Callbacks
|
||||||
|
|
||||||
|
| Callback | Description |
|
||||||
|
|-----------------------------|---------------------------------------------------------|
|
||||||
|
| `on_pretrain_routine_start` | Triggered at the beginning of pre-training routine |
|
||||||
|
| `on_pretrain_routine_end` | Triggered at the end of pre-training routine |
|
||||||
|
| `on_train_start` | Triggered when the training starts |
|
||||||
|
| `on_train_epoch_start` | Triggered at the start of each training epoch |
|
||||||
|
| `on_train_batch_start` | Triggered at the start of each training batch |
|
||||||
|
| `optimizer_step` | Triggered during the optimizer step |
|
||||||
|
| `on_before_zero_grad` | Triggered before gradients are zeroed |
|
||||||
|
| `on_train_batch_end` | Triggered at the end of each training batch |
|
||||||
|
| `on_train_epoch_end` | Triggered at the end of each training epoch |
|
||||||
|
| `on_fit_epoch_end` | Triggered at the end of each fit epoch |
|
||||||
|
| `on_model_save` | Triggered when the model is saved |
|
||||||
|
| `on_train_end` | Triggered when the training process ends |
|
||||||
|
| `on_params_update` | Triggered when model parameters are updated |
|
||||||
|
| `teardown` | Triggered when the training process is being cleaned up |
|
||||||
|
|
||||||
|
|
||||||
|
### Validator Callbacks
|
||||||
|
|
||||||
|
| Callback | Description |
|
||||||
|
|----------------------|-------------------------------------------------|
|
||||||
|
| `on_val_start` | Triggered when the validation starts |
|
||||||
|
| `on_val_batch_start` | Triggered at the start of each validation batch |
|
||||||
|
| `on_val_batch_end` | Triggered at the end of each validation batch |
|
||||||
|
| `on_val_end` | Triggered when the validation ends |
|
||||||
|
|
||||||
|
|
||||||
|
### Predictor Callbacks
|
||||||
|
|
||||||
|
| Callback | Description |
|
||||||
|
|------------------------------|---------------------------------------------------|
|
||||||
|
| `on_predict_start` | Triggered when the prediction process starts |
|
||||||
|
| `on_predict_batch_start` | Triggered at the start of each prediction batch |
|
||||||
|
| `on_predict_postprocess_end` | Triggered at the end of prediction postprocessing |
|
||||||
|
| `on_predict_batch_end` | Triggered at the end of each prediction batch |
|
||||||
|
| `on_predict_end` | Triggered when the prediction process ends |
|
||||||
|
|
||||||
|
### Exporter Callbacks
|
||||||
|
|
||||||
|
| Callback | Description |
|
||||||
|
|-------------------|------------------------------------------|
|
||||||
|
| `on_export_start` | Triggered when the export process starts |
|
||||||
|
| `on_export_end` | Triggered when the export process ends |
|
||||||
248
docs/usage/cfg.md
Normal file
@@ -0,0 +1,248 @@
|
|||||||
|
YOLO settings and hyperparameters play a critical role in the model's performance, speed, and accuracy. These settings
|
||||||
|
and hyperparameters can affect the model's behavior at various stages of the model development process, including
|
||||||
|
training, validation, and prediction.
|
||||||
|
|
||||||
|
YOLOv8 'yolo' CLI commands use the following syntax:
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
yolo TASK MODE ARGS
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a YOLOv8 model from a pre-trained weights file
|
||||||
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
|
# Run MODE mode using the custom arguments ARGS (guess TASK)
|
||||||
|
model.MODE(ARGS)
|
||||||
|
```
|
||||||
|
|
||||||
|
Where:
|
||||||
|
|
||||||
|
- `TASK` (optional) is one of `[detect, segment, classify, pose]`. If it is not passed explicitly YOLOv8 will try to
|
||||||
|
guess
|
||||||
|
the `TASK` from the model type.
|
||||||
|
- `MODE` (required) is one of `[train, val, predict, export, track, benchmark]`
|
||||||
|
- `ARGS` (optional) are any number of custom `arg=value` pairs like `imgsz=320` that override defaults.
|
||||||
|
For a full list of available `ARGS` see the [Configuration](cfg.md) page and `defaults.yaml`
|
||||||
|
GitHub [source](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/cfg/default.yaml).
|
||||||
|
|
||||||
|
#### Tasks
|
||||||
|
|
||||||
|
YOLO models can be used for a variety of tasks, including detection, segmentation, classification and pose. These tasks
|
||||||
|
differ in the type of output they produce and the specific problem they are designed to solve.
|
||||||
|
|
||||||
|
**Detect**: For identifying and localizing objects or regions of interest in an image or video.
|
||||||
|
**Segment**: For dividing an image or video into regions or pixels that correspond to different objects or classes.
|
||||||
|
**Classify**: For predicting the class label of an input image.
|
||||||
|
**Pose**: For identifying objects and estimating their keypoints in an image or video.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|--------|------------|-------------------------------------------------|
|
||||||
|
| `task` | `'detect'` | YOLO task, i.e. detect, segment, classify, pose |
|
||||||
|
|
||||||
|
[Tasks Guide](../tasks/index.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
#### Modes
|
||||||
|
|
||||||
|
YOLO models can be used in different modes depending on the specific problem you are trying to solve. These modes
|
||||||
|
include:
|
||||||
|
|
||||||
|
**Train**: For training a YOLOv8 model on a custom dataset.
|
||||||
|
**Val**: For validating a YOLOv8 model after it has been trained.
|
||||||
|
**Predict**: For making predictions using a trained YOLOv8 model on new images or videos.
|
||||||
|
**Export**: For exporting a YOLOv8 model to a format that can be used for deployment.
|
||||||
|
**Track**: For tracking objects in real-time using a YOLOv8 model.
|
||||||
|
**Benchmark**: For benchmarking YOLOv8 exports (ONNX, TensorRT, etc.) speed and accuracy.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|--------|-----------|---------------------------------------------------------------|
|
||||||
|
| `mode` | `'train'` | YOLO mode, i.e. train, val, predict, export, track, benchmark |
|
||||||
|
|
||||||
|
[Modes Guide](../modes/index.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## Train
|
||||||
|
|
||||||
|
The training settings for YOLO models encompass various hyperparameters and configurations used during the training process. These settings influence the model's performance, speed, and accuracy. Key training settings include batch size, learning rate, momentum, and weight decay. Additionally, the choice of optimizer, loss function, and training dataset composition can impact the training process. Careful tuning and experimentation with these settings are crucial for optimizing performance.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|-------------------|----------|-----------------------------------------------------------------------------|
|
||||||
|
| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
|
||||||
|
| `data` | `None` | path to data file, i.e. coco128.yaml |
|
||||||
|
| `epochs` | `100` | number of epochs to train for |
|
||||||
|
| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |
|
||||||
|
| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
|
||||||
|
| `imgsz` | `640` | size of input images as integer or w,h |
|
||||||
|
| `save` | `True` | save train checkpoints and predict results |
|
||||||
|
| `save_period` | `-1` | Save checkpoint every x epochs (disabled if < 1) |
|
||||||
|
| `cache` | `False` | True/ram, disk or False. Use cache for data loading |
|
||||||
|
| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
|
||||||
|
| `workers` | `8` | number of worker threads for data loading (per RANK if DDP) |
|
||||||
|
| `project` | `None` | project name |
|
||||||
|
| `name` | `None` | experiment name |
|
||||||
|
| `exist_ok` | `False` | whether to overwrite existing experiment |
|
||||||
|
| `pretrained` | `False` | whether to use a pretrained model |
|
||||||
|
| `optimizer` | `'SGD'` | optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp'] |
|
||||||
|
| `verbose` | `False` | whether to print verbose output |
|
||||||
|
| `seed` | `0` | random seed for reproducibility |
|
||||||
|
| `deterministic` | `True` | whether to enable deterministic mode |
|
||||||
|
| `single_cls` | `False` | train multi-class data as single-class |
|
||||||
|
| `image_weights` | `False` | use weighted image selection for training |
|
||||||
|
| `rect` | `False` | rectangular training with each batch collated for minimum padding |
|
||||||
|
| `cos_lr` | `False` | use cosine learning rate scheduler |
|
||||||
|
| `close_mosaic` | `10` | disable mosaic augmentation for final 10 epochs |
|
||||||
|
| `resume` | `False` | resume training from last checkpoint |
|
||||||
|
| `amp` | `True` | Automatic Mixed Precision (AMP) training, choices=[True, False] |
|
||||||
|
| `lr0` | `0.01` | initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |
|
||||||
|
| `lrf` | `0.01` | final learning rate (lr0 * lrf) |
|
||||||
|
| `momentum` | `0.937` | SGD momentum/Adam beta1 |
|
||||||
|
| `weight_decay` | `0.0005` | optimizer weight decay 5e-4 |
|
||||||
|
| `warmup_epochs` | `3.0` | warmup epochs (fractions ok) |
|
||||||
|
| `warmup_momentum` | `0.8` | warmup initial momentum |
|
||||||
|
| `warmup_bias_lr` | `0.1` | warmup initial bias lr |
|
||||||
|
| `box` | `7.5` | box loss gain |
|
||||||
|
| `cls` | `0.5` | cls loss gain (scale with pixels) |
|
||||||
|
| `dfl` | `1.5` | dfl loss gain |
|
||||||
|
| `pose` | `12.0` | pose loss gain (pose-only) |
|
||||||
|
| `kobj` | `2.0` | keypoint obj loss gain (pose-only) |
|
||||||
|
| `fl_gamma` | `0.0` | focal loss gamma (efficientDet default gamma=1.5) |
|
||||||
|
| `label_smoothing` | `0.0` | label smoothing (fraction) |
|
||||||
|
| `nbs` | `64` | nominal batch size |
|
||||||
|
| `overlap_mask` | `True` | masks should overlap during training (segment train only) |
|
||||||
|
| `mask_ratio` | `4` | mask downsample ratio (segment train only) |
|
||||||
|
| `dropout` | `0.0` | use dropout regularization (classify train only) |
|
||||||
|
| `val` | `True` | validate/test during training |
|
||||||
|
|
||||||
|
[Train Guide](../modes/train.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## Predict
|
||||||
|
|
||||||
|
The prediction settings for YOLO models encompass a range of hyperparameters and configurations that influence the model's performance, speed, and accuracy during inference on new data. Careful tuning and experimentation with these settings are essential to achieve optimal performance for a specific task. Key settings include the confidence threshold, Non-Maximum Suppression (NMS) threshold, and the number of classes considered. Additional factors affecting the prediction process are input data size and format, the presence of supplementary features such as masks or multiple labels per box, and the particular task the model is employed for.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|------------------|------------------------|----------------------------------------------------------|
|
||||||
|
| `source` | `'ultralytics/assets'` | source directory for images or videos |
|
||||||
|
| `conf` | `0.25` | object confidence threshold for detection |
|
||||||
|
| `iou` | `0.7` | intersection over union (IoU) threshold for NMS |
|
||||||
|
| `half` | `False` | use half precision (FP16) |
|
||||||
|
| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
|
||||||
|
| `show` | `False` | show results if possible |
|
||||||
|
| `save` | `False` | save images with results |
|
||||||
|
| `save_txt` | `False` | save results as .txt file |
|
||||||
|
| `save_conf` | `False` | save results with confidence scores |
|
||||||
|
| `save_crop` | `False` | save cropped images with results |
|
||||||
|
| `show_labels` | `True` | show object labels in plots |
|
||||||
|
| `show_conf` | `True` | show object confidence scores in plots |
|
||||||
|
| `max_det` | `300` | maximum number of detections per image |
|
||||||
|
| `vid_stride` | `False` | video frame-rate stride |
|
||||||
|
| `line_thickness` | `3` | bounding box thickness (pixels) |
|
||||||
|
| `visualize` | `False` | visualize model features |
|
||||||
|
| `augment` | `False` | apply image augmentation to prediction sources |
|
||||||
|
| `agnostic_nms` | `False` | class-agnostic NMS |
|
||||||
|
| `retina_masks` | `False` | use high-resolution segmentation masks |
|
||||||
|
| `classes` | `None` | filter results by class, i.e. class=0, or class=[0,2,3] |
|
||||||
|
| `boxes` | `True` | Show boxes in segmentation predictions |
|
||||||
|
|
||||||
|
[Predict Guide](../modes/predict.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## Val
|
||||||
|
|
||||||
|
The val (validation) settings for YOLO models involve various hyperparameters and configurations used to evaluate the model's performance on a validation dataset. These settings influence the model's performance, speed, and accuracy. Common YOLO validation settings include batch size, validation frequency during training, and performance evaluation metrics. Other factors affecting the validation process include the validation dataset's size and composition, as well as the specific task the model is employed for. Careful tuning and experimentation with these settings are crucial to ensure optimal performance on the validation dataset and detect and prevent overfitting.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|---------------|---------|--------------------------------------------------------------------|
|
||||||
|
| `save_json` | `False` | save results to JSON file |
|
||||||
|
| `save_hybrid` | `False` | save hybrid version of labels (labels + additional predictions) |
|
||||||
|
| `conf` | `0.001` | object confidence threshold for detection |
|
||||||
|
| `iou` | `0.6` | intersection over union (IoU) threshold for NMS |
|
||||||
|
| `max_det` | `300` | maximum number of detections per image |
|
||||||
|
| `half` | `True` | use half precision (FP16) |
|
||||||
|
| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
|
||||||
|
| `dnn` | `False` | use OpenCV DNN for ONNX inference |
|
||||||
|
| `plots` | `False` | show plots during training |
|
||||||
|
| `rect` | `False` | rectangular val with each batch collated for minimum padding |
|
||||||
|
| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |
|
||||||
|
|
||||||
|
[Val Guide](../modes/val.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## Export
|
||||||
|
|
||||||
|
Export settings for YOLO models encompass configurations and options related to saving or exporting the model for use in different environments or platforms. These settings can impact the model's performance, size, and compatibility with various systems. Key export settings include the exported model file format (e.g., ONNX, TensorFlow SavedModel), the target device (e.g., CPU, GPU), and additional features such as masks or multiple labels per box. The export process may also be affected by the model's specific task and the requirements or constraints of the destination environment or platform. It is crucial to thoughtfully configure these settings to ensure the exported model is optimized for the intended use case and functions effectively in the target environment.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|-------------|-----------------|------------------------------------------------------|
|
||||||
|
| `format` | `'torchscript'` | format to export to |
|
||||||
|
| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
|
||||||
|
| `keras` | `False` | use Keras for TF SavedModel export |
|
||||||
|
| `optimize` | `False` | TorchScript: optimize for mobile |
|
||||||
|
| `half` | `False` | FP16 quantization |
|
||||||
|
| `int8` | `False` | INT8 quantization |
|
||||||
|
| `dynamic` | `False` | ONNX/TF/TensorRT: dynamic axes |
|
||||||
|
| `simplify` | `False` | ONNX: simplify model |
|
||||||
|
| `opset` | `None` | ONNX: opset version (optional, defaults to latest) |
|
||||||
|
| `workspace` | `4` | TensorRT: workspace size (GB) |
|
||||||
|
| `nms` | `False` | CoreML: add NMS |
|
||||||
|
|
||||||
|
[Export Guide](../modes/export.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## Augmentation
|
||||||
|
|
||||||
|
Augmentation settings for YOLO models refer to the various transformations and modifications
|
||||||
|
applied to the training data to increase the diversity and size of the dataset. These settings can affect the model's
|
||||||
|
performance, speed, and accuracy. Some common YOLO augmentation settings include the type and intensity of the
|
||||||
|
transformations applied (e.g. random flips, rotations, cropping, color changes), the probability with which each
|
||||||
|
transformation is applied, and the presence of additional features such as masks or multiple labels per box. Other
|
||||||
|
factors that may affect the augmentation process include the size and composition of the original dataset and the
|
||||||
|
specific task the model is being used for. It is important to carefully tune and experiment with these settings to
|
||||||
|
ensure that the augmented dataset is diverse and representative enough to train a high-performing model.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|---------------|-------|-------------------------------------------------|
|
||||||
|
| `hsv_h` | 0.015 | image HSV-Hue augmentation (fraction) |
|
||||||
|
| `hsv_s` | 0.7 | image HSV-Saturation augmentation (fraction) |
|
||||||
|
| `hsv_v` | 0.4 | image HSV-Value augmentation (fraction) |
|
||||||
|
| `degrees` | 0.0 | image rotation (+/- deg) |
|
||||||
|
| `translate` | 0.1 | image translation (+/- fraction) |
|
||||||
|
| `scale` | 0.5 | image scale (+/- gain) |
|
||||||
|
| `shear` | 0.0 | image shear (+/- deg) |
|
||||||
|
| `perspective` | 0.0 | image perspective (+/- fraction), range 0-0.001 |
|
||||||
|
| `flipud` | 0.0 | image flip up-down (probability) |
|
||||||
|
| `fliplr` | 0.5 | image flip left-right (probability) |
|
||||||
|
| `mosaic` | 1.0 | image mosaic (probability) |
|
||||||
|
| `mixup` | 0.0 | image mixup (probability) |
|
||||||
|
| `copy_paste` | 0.0 | segment copy-paste (probability) |
|
||||||
|
|
||||||
|
## Logging, checkpoints, plotting and file management
|
||||||
|
|
||||||
|
Logging, checkpoints, plotting, and file management are important considerations when training a YOLO model.
|
||||||
|
|
||||||
|
- Logging: It is often helpful to log various metrics and statistics during training to track the model's progress and
|
||||||
|
diagnose any issues that may arise. This can be done using a logging library such as TensorBoard or by writing log
|
||||||
|
messages to a file.
|
||||||
|
- Checkpoints: It is a good practice to save checkpoints of the model at regular intervals during training. This allows
|
||||||
|
you to resume training from a previous point if the training process is interrupted or if you want to experiment with
|
||||||
|
different training configurations.
|
||||||
|
- Plotting: Visualizing the model's performance and training progress can be helpful for understanding how the model is
|
||||||
|
behaving and identifying potential issues. This can be done using a plotting library such as matplotlib or by
|
||||||
|
generating plots using a logging library such as TensorBoard.
|
||||||
|
- File management: Managing the various files generated during the training process, such as model checkpoints, log
|
||||||
|
files, and plots, can be challenging. It is important to have a clear and organized file structure to keep track of
|
||||||
|
these files and make it easy to access and analyze them as needed.
|
||||||
|
|
||||||
|
Effective logging, checkpointing, plotting, and file management can help you keep track of the model's progress and make
|
||||||
|
it easier to debug and optimize the training process.
|
||||||
|
|
||||||
|
| Key | Value | Description |
|
||||||
|
|------------|----------|------------------------------------------------------------------------------------------------|
|
||||||
|
| `project` | `'runs'` | project name |
|
||||||
|
| `name` | `'exp'` | experiment name. `exp` gets automatically incremented if not specified, i.e, `exp`, `exp2` ... |
|
||||||
|
| `exist_ok` | `False` | whether to overwrite existing experiment |
|
||||||
|
| `plots` | `False` | save plots during train/val |
|
||||||
|
| `save` | `False` | save train checkpoints and predict results |
|
||||||
221
docs/usage/cli.md
Normal file
@@ -0,0 +1,221 @@
|
|||||||
|
# Command Line Interface Usage
|
||||||
|
|
||||||
|
The YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment.
|
||||||
|
CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command.
|
||||||
|
|
||||||
|
!!! example
|
||||||
|
|
||||||
|
=== "Syntax"
|
||||||
|
|
||||||
|
Ultralytics `yolo` commands use the following syntax:
|
||||||
|
```bash
|
||||||
|
yolo TASK MODE ARGS
|
||||||
|
|
||||||
|
Where TASK (optional) is one of [detect, segment, classify]
|
||||||
|
MODE (required) is one of [train, val, predict, export, track]
|
||||||
|
ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
|
||||||
|
```
|
||||||
|
See all ARGS in the full [Configuration Guide](./cfg.md) or with `yolo cfg`
|
||||||
|
|
||||||
|
=== "Train"
|
||||||
|
|
||||||
|
Train a detection model for 10 epochs with an initial learning_rate of 0.01
|
||||||
|
```bash
|
||||||
|
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Predict"
|
||||||
|
|
||||||
|
Predict a YouTube video using a pretrained segmentation model at image size 320:
|
||||||
|
```bash
|
||||||
|
yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Val"
|
||||||
|
|
||||||
|
Val a pretrained detection model at batch-size 1 and image size 640:
|
||||||
|
```bash
|
||||||
|
yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Export"
|
||||||
|
|
||||||
|
Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
|
||||||
|
```bash
|
||||||
|
yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Special"
|
||||||
|
|
||||||
|
Run special commands to see version, view settings, run checks and more:
|
||||||
|
```bash
|
||||||
|
yolo help
|
||||||
|
yolo checks
|
||||||
|
yolo version
|
||||||
|
yolo settings
|
||||||
|
yolo copy-cfg
|
||||||
|
yolo cfg
|
||||||
|
```
|
||||||
|
|
||||||
|
Where:
|
||||||
|
|
||||||
|
- `TASK` (optional) is one of `[detect, segment, classify]`. If it is not passed explicitly YOLOv8 will try to guess
|
||||||
|
the `TASK` from the model type.
|
||||||
|
- `MODE` (required) is one of `[train, val, predict, export, track]`
|
||||||
|
- `ARGS` (optional) are any number of custom `arg=value` pairs like `imgsz=320` that override defaults.
|
||||||
|
For a full list of available `ARGS` see the [Configuration](cfg.md) page and `defaults.yaml`
|
||||||
|
GitHub [source](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/cfg/default.yaml).
|
||||||
|
|
||||||
|
!!! warning "Warning"
|
||||||
|
|
||||||
|
Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` beteen arguments.
|
||||||
|
|
||||||
|
- `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
|
||||||
|
- `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌
|
||||||
|
- `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌
|
||||||
|
|
||||||
|
## Train
|
||||||
|
|
||||||
|
Train YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. For a full list of available arguments see
|
||||||
|
the [Configuration](cfg.md) page.
|
||||||
|
|
||||||
|
!!! example "Example"
|
||||||
|
|
||||||
|
=== "Train"
|
||||||
|
|
||||||
|
Start training YOLOv8n on COCO128 for 100 epochs at image-size 640.
|
||||||
|
```bash
|
||||||
|
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Resume"
|
||||||
|
|
||||||
|
Resume an interrupted training.
|
||||||
|
```bash
|
||||||
|
yolo detect train resume model=last.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
## Val
|
||||||
|
|
||||||
|
Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's
|
||||||
|
training `data` and arguments as model attributes.
|
||||||
|
|
||||||
|
!!! example "Example"
|
||||||
|
|
||||||
|
=== "Official"
|
||||||
|
|
||||||
|
Validate an official YOLOv8n model.
|
||||||
|
```bash
|
||||||
|
yolo detect val model=yolov8n.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Custom"
|
||||||
|
|
||||||
|
Validate a custom-trained model.
|
||||||
|
```bash
|
||||||
|
yolo detect val model=path/to/best.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
## Predict
|
||||||
|
|
||||||
|
Use a trained YOLOv8n model to run predictions on images.
|
||||||
|
|
||||||
|
!!! example "Example"
|
||||||
|
|
||||||
|
=== "Official"
|
||||||
|
|
||||||
|
Predict with an official YOLOv8n model.
|
||||||
|
```bash
|
||||||
|
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Custom"
|
||||||
|
|
||||||
|
Predict with a custom model.
|
||||||
|
```bash
|
||||||
|
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg'
|
||||||
|
```
|
||||||
|
|
||||||
|
## Export
|
||||||
|
|
||||||
|
Export a YOLOv8n model to a different format like ONNX, CoreML, etc.
|
||||||
|
|
||||||
|
!!! example "Example"
|
||||||
|
|
||||||
|
=== "Official"
|
||||||
|
|
||||||
|
Export an official YOLOv8n model to ONNX format.
|
||||||
|
```bash
|
||||||
|
yolo export model=yolov8n.pt format=onnx
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Custom"
|
||||||
|
|
||||||
|
Export a custom-trained model to ONNX format.
|
||||||
|
```bash
|
||||||
|
yolo export model=path/to/best.pt format=onnx
|
||||||
|
```
|
||||||
|
|
||||||
|
Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
|
||||||
|
i.e. `format='onnx'` or `format='engine'`.
|
||||||
|
|
||||||
|
| Format | `format` Argument | Model | Metadata |
|
||||||
|
|--------------------------------------------------------------------|-------------------|---------------------------|----------|
|
||||||
|
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
|
||||||
|
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
|
||||||
|
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
|
||||||
|
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
|
||||||
|
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
|
||||||
|
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
|
||||||
|
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
|
||||||
|
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
|
||||||
|
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
|
||||||
|
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
|
||||||
|
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
|
||||||
|
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Overriding default arguments
|
||||||
|
|
||||||
|
Default arguments can be overridden by simply passing them as arguments in the CLI in `arg=value` pairs.
|
||||||
|
|
||||||
|
!!! tip ""
|
||||||
|
|
||||||
|
=== "Train"
|
||||||
|
Train a detection model for `10 epochs` with `learning_rate` of `0.01`
|
||||||
|
```bash
|
||||||
|
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Predict"
|
||||||
|
Predict a YouTube video using a pretrained segmentation model at image size 320:
|
||||||
|
```bash
|
||||||
|
yolo segment predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Val"
|
||||||
|
Validate a pretrained detection model at batch-size 1 and image size 640:
|
||||||
|
```bash
|
||||||
|
yolo detect val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Overriding default config file
|
||||||
|
|
||||||
|
You can override the `default.yaml` config file entirely by passing a new file with the `cfg` arguments,
|
||||||
|
i.e. `cfg=custom.yaml`.
|
||||||
|
|
||||||
|
To do this first create a copy of `default.yaml` in your current working dir with the `yolo copy-cfg` command.
|
||||||
|
|
||||||
|
This will create `default_copy.yaml`, which you can then pass as `cfg=default_copy.yaml` along with any additional args,
|
||||||
|
like `imgsz=320` in this example:
|
||||||
|
|
||||||
|
!!! example ""
|
||||||
|
|
||||||
|
=== "CLI"
|
||||||
|
```bash
|
||||||
|
yolo copy-cfg
|
||||||
|
yolo cfg=default_copy.yaml imgsz=320
|
||||||
|
```
|
||||||
83
docs/usage/engine.md
Normal file
@@ -0,0 +1,83 @@
|
|||||||
|
Both the Ultralytics YOLO command-line and python interfaces are simply a high-level abstraction on the base engine
|
||||||
|
executors. Let's take a look at the Trainer engine.
|
||||||
|
|
||||||
|
## BaseTrainer
|
||||||
|
|
||||||
|
BaseTrainer contains the generic boilerplate training routine. It can be customized for any task based over overriding
|
||||||
|
the required functions or operations as long the as correct formats are followed. For example, you can support your own
|
||||||
|
custom model and dataloader by just overriding these functions:
|
||||||
|
|
||||||
|
* `get_model(cfg, weights)` - The function that builds the model to be trained
|
||||||
|
* `get_dataloder()` - The function that builds the dataloader
|
||||||
|
More details and source code can be found in [`BaseTrainer` Reference](../reference/base_trainer.md)
|
||||||
|
|
||||||
|
## DetectionTrainer
|
||||||
|
|
||||||
|
Here's how you can use the YOLOv8 `DetectionTrainer` and customize it.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics.yolo.v8.detect import DetectionTrainer
|
||||||
|
|
||||||
|
trainer = DetectionTrainer(overrides={...})
|
||||||
|
trainer.train()
|
||||||
|
trained_model = trainer.best # get best model
|
||||||
|
```
|
||||||
|
|
||||||
|
### Customizing the DetectionTrainer
|
||||||
|
|
||||||
|
Let's customize the trainer **to train a custom detection model** that is not supported directly. You can do this by
|
||||||
|
simply overloading the existing the `get_model` functionality:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics.yolo.v8.detect import DetectionTrainer
|
||||||
|
|
||||||
|
|
||||||
|
class CustomTrainer(DetectionTrainer):
|
||||||
|
def get_model(self, cfg, weights):
|
||||||
|
...
|
||||||
|
|
||||||
|
|
||||||
|
trainer = CustomTrainer(overrides={...})
|
||||||
|
trainer.train()
|
||||||
|
```
|
||||||
|
|
||||||
|
You now realize that you need to customize the trainer further to:
|
||||||
|
|
||||||
|
* Customize the `loss function`.
|
||||||
|
* Add `callback` that uploads model to your Google Drive after every 10 `epochs`
|
||||||
|
Here's how you can do it:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics.yolo.v8.detect import DetectionTrainer
|
||||||
|
|
||||||
|
|
||||||
|
class CustomTrainer(DetectionTrainer):
|
||||||
|
def get_model(self, cfg, weights):
|
||||||
|
...
|
||||||
|
|
||||||
|
def criterion(self, preds, batch):
|
||||||
|
# get ground truth
|
||||||
|
imgs = batch["imgs"]
|
||||||
|
bboxes = batch["bboxes"]
|
||||||
|
...
|
||||||
|
return loss, loss_items # see Reference-> Trainer for details on the expected format
|
||||||
|
|
||||||
|
|
||||||
|
# callback to upload model weights
|
||||||
|
def log_model(trainer):
|
||||||
|
last_weight_path = trainer.last
|
||||||
|
...
|
||||||
|
|
||||||
|
|
||||||
|
trainer = CustomTrainer(overrides={...})
|
||||||
|
trainer.add_callback("on_train_epoch_end", log_model) # Adds to existing callback
|
||||||
|
trainer.train()
|
||||||
|
```
|
||||||
|
|
||||||
|
To know more about Callback triggering events and entry point, checkout our [Callbacks Guide](callbacks.md)
|
||||||
|
|
||||||
|
## Other engine components
|
||||||
|
|
||||||
|
There are other components that can be customized similarly like `Validators` and `Predictors`
|
||||||
|
See Reference section for more information on these.
|
||||||
|
|
||||||
277
docs/usage/python.md
Normal file
@@ -0,0 +1,277 @@
|
|||||||
|
# Python Usage
|
||||||
|
|
||||||
|
Welcome to the YOLOv8 Python Usage documentation! This guide is designed to help you seamlessly integrate YOLOv8 into
|
||||||
|
your Python projects for object detection, segmentation, and classification. Here, you'll learn how to load and use
|
||||||
|
pretrained models, train new models, and perform predictions on images. The easy-to-use Python interface is a valuable
|
||||||
|
resource for anyone looking to incorporate YOLOv8 into their Python projects, allowing you to quickly implement advanced
|
||||||
|
object detection capabilities. Let's get started!
|
||||||
|
|
||||||
|
For example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX
|
||||||
|
format with just a few lines of code.
|
||||||
|
|
||||||
|
!!! example "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Create a new YOLO model from scratch
|
||||||
|
model = YOLO('yolov8n.yaml')
|
||||||
|
|
||||||
|
# Load a pretrained YOLO model (recommended for training)
|
||||||
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
|
# Train the model using the 'coco128.yaml' dataset for 3 epochs
|
||||||
|
results = model.train(data='coco128.yaml', epochs=3)
|
||||||
|
|
||||||
|
# Evaluate the model's performance on the validation set
|
||||||
|
results = model.val()
|
||||||
|
|
||||||
|
# Perform object detection on an image using the model
|
||||||
|
results = model('https://ultralytics.com/images/bus.jpg')
|
||||||
|
|
||||||
|
# Export the model to ONNX format
|
||||||
|
success = model.export(format='onnx')
|
||||||
|
```
|
||||||
|
|
||||||
|
## [Train](../modes/train.md)
|
||||||
|
|
||||||
|
Train mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
|
||||||
|
specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
|
||||||
|
accurately predict the classes and locations of objects in an image.
|
||||||
|
|
||||||
|
!!! example "Train"
|
||||||
|
|
||||||
|
=== "From pretrained(recommended)"
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
model = YOLO('yolov8n.pt') # pass any model type
|
||||||
|
model.train(epochs=5)
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "From scratch"
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
model = YOLO('yolov8n.yaml')
|
||||||
|
model.train(data='coco128.yaml', epochs=5)
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Resume"
|
||||||
|
```python
|
||||||
|
model = YOLO("last.pt")
|
||||||
|
model.train(resume=True)
|
||||||
|
```
|
||||||
|
|
||||||
|
[Train Examples](../modes/train.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Val](../modes/val.md)
|
||||||
|
|
||||||
|
Val mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
|
||||||
|
validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
|
||||||
|
of the model to improve its performance.
|
||||||
|
|
||||||
|
!!! example "Val"
|
||||||
|
|
||||||
|
=== "Val after training"
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
model = YOLO('yolov8n.yaml')
|
||||||
|
model.train(data='coco128.yaml', epochs=5)
|
||||||
|
model.val() # It'll automatically evaluate the data you trained.
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Val independently"
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
model = YOLO("model.pt")
|
||||||
|
# It'll use the data yaml file in model.pt if you don't set data.
|
||||||
|
model.val()
|
||||||
|
# or you can set the data you want to val
|
||||||
|
model.val(data='coco128.yaml')
|
||||||
|
```
|
||||||
|
|
||||||
|
[Val Examples](../modes/val.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Predict](../modes/predict.md)
|
||||||
|
|
||||||
|
Predict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the
|
||||||
|
model is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model
|
||||||
|
predicts the classes and locations of objects in the input images or videos.
|
||||||
|
|
||||||
|
!!! example "Predict"
|
||||||
|
|
||||||
|
=== "From source"
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
from PIL import Image
|
||||||
|
import cv2
|
||||||
|
|
||||||
|
model = YOLO("model.pt")
|
||||||
|
# accepts all formats - image/dir/Path/URL/video/PIL/ndarray. 0 for webcam
|
||||||
|
results = model.predict(source="0")
|
||||||
|
results = model.predict(source="folder", show=True) # Display preds. Accepts all YOLO predict arguments
|
||||||
|
|
||||||
|
# from PIL
|
||||||
|
im1 = Image.open("bus.jpg")
|
||||||
|
results = model.predict(source=im1, save=True) # save plotted images
|
||||||
|
|
||||||
|
# from ndarray
|
||||||
|
im2 = cv2.imread("bus.jpg")
|
||||||
|
results = model.predict(source=im2, save=True, save_txt=True) # save predictions as labels
|
||||||
|
|
||||||
|
# from list of PIL/ndarray
|
||||||
|
results = model.predict(source=[im1, im2])
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Results usage"
|
||||||
|
```python
|
||||||
|
# results would be a list of Results object including all the predictions by default
|
||||||
|
# but be careful as it could occupy a lot memory when there're many images,
|
||||||
|
# especially the task is segmentation.
|
||||||
|
# 1. return as a list
|
||||||
|
results = model.predict(source="folder")
|
||||||
|
|
||||||
|
# results would be a generator which is more friendly to memory by setting stream=True
|
||||||
|
# 2. return as a generator
|
||||||
|
results = model.predict(source=0, stream=True)
|
||||||
|
|
||||||
|
for result in results:
|
||||||
|
# detection
|
||||||
|
result.boxes.xyxy # box with xyxy format, (N, 4)
|
||||||
|
result.boxes.xywh # box with xywh format, (N, 4)
|
||||||
|
result.boxes.xyxyn # box with xyxy format but normalized, (N, 4)
|
||||||
|
result.boxes.xywhn # box with xywh format but normalized, (N, 4)
|
||||||
|
result.boxes.conf # confidence score, (N, 1)
|
||||||
|
result.boxes.cls # cls, (N, 1)
|
||||||
|
|
||||||
|
# segmentation
|
||||||
|
result.masks.masks # masks, (N, H, W)
|
||||||
|
result.masks.xy # x,y segments (pixels), List[segment] * N
|
||||||
|
result.masks.xyn # x,y segments (normalized), List[segment] * N
|
||||||
|
|
||||||
|
# classification
|
||||||
|
result.probs # cls prob, (num_class, )
|
||||||
|
|
||||||
|
# Each result is composed of torch.Tensor by default,
|
||||||
|
# in which you can easily use following functionality:
|
||||||
|
result = result.cuda()
|
||||||
|
result = result.cpu()
|
||||||
|
result = result.to("cpu")
|
||||||
|
result = result.numpy()
|
||||||
|
```
|
||||||
|
|
||||||
|
[Predict Examples](../modes/predict.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Export](../modes/export.md)
|
||||||
|
|
||||||
|
Export mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is
|
||||||
|
converted to a format that can be used by other software applications or hardware devices. This mode is useful when
|
||||||
|
deploying the model to production environments.
|
||||||
|
|
||||||
|
!!! example "Export"
|
||||||
|
|
||||||
|
=== "Export to ONNX"
|
||||||
|
|
||||||
|
Export an official YOLOv8n model to ONNX with dynamic batch-size and image-size.
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
model = YOLO('yolov8n.pt')
|
||||||
|
model.export(format='onnx', dynamic=True)
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Export to TensorRT"
|
||||||
|
|
||||||
|
Export an official YOLOv8n model to TensorRT on `device=0` for acceleration on CUDA devices.
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
model = YOLO('yolov8n.pt')
|
||||||
|
model.export(format='onnx', device=0)
|
||||||
|
```
|
||||||
|
|
||||||
|
[Export Examples](../modes/export.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Track](../modes/track.md)
|
||||||
|
|
||||||
|
Track mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a
|
||||||
|
checkpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful
|
||||||
|
for applications such as surveillance systems or self-driving cars.
|
||||||
|
|
||||||
|
!!! example "Track"
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('yolov8n.pt') # load an official detection model
|
||||||
|
model = YOLO('yolov8n-seg.pt') # load an official segmentation model
|
||||||
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Track with the model
|
||||||
|
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
|
||||||
|
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
|
||||||
|
```
|
||||||
|
|
||||||
|
[Track Examples](../modes/track.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## [Benchmark](../modes/benchmark.md)
|
||||||
|
|
||||||
|
Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide
|
||||||
|
information on the size of the exported format, its `mAP50-95` metrics (for object detection and segmentation)
|
||||||
|
or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
|
||||||
|
formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
|
||||||
|
their specific use case based on their requirements for speed and accuracy.
|
||||||
|
|
||||||
|
!!! example "Benchmark"
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
Benchmark an official YOLOv8n model across all export formats.
|
||||||
|
```python
|
||||||
|
from ultralytics.yolo.utils.benchmarks import benchmark
|
||||||
|
|
||||||
|
# Benchmark
|
||||||
|
benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)
|
||||||
|
```
|
||||||
|
|
||||||
|
[Benchmark Examples](../modes/benchmark.md){ .md-button .md-button--primary}
|
||||||
|
|
||||||
|
## Using Trainers
|
||||||
|
|
||||||
|
`YOLO` model class is a high-level wrapper on the Trainer classes. Each YOLO task has its own trainer that inherits
|
||||||
|
from `BaseTrainer`.
|
||||||
|
|
||||||
|
!!! tip "Detection Trainer Example"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics.yolo import v8 import DetectionTrainer, DetectionValidator, DetectionPredictor
|
||||||
|
|
||||||
|
# trainer
|
||||||
|
trainer = DetectionTrainer(overrides={})
|
||||||
|
trainer.train()
|
||||||
|
trained_model = trainer.best
|
||||||
|
|
||||||
|
# Validator
|
||||||
|
val = DetectionValidator(args=...)
|
||||||
|
val(model=trained_model)
|
||||||
|
|
||||||
|
# predictor
|
||||||
|
pred = DetectionPredictor(overrides={})
|
||||||
|
pred(source=SOURCE, model=trained_model)
|
||||||
|
|
||||||
|
# resume from last weight
|
||||||
|
overrides["resume"] = trainer.last
|
||||||
|
trainer = detect.DetectionTrainer(overrides=overrides)
|
||||||
|
```
|
||||||
|
|
||||||
|
You can easily customize Trainers to support custom tasks or explore R&D ideas.
|
||||||
|
Learn more about Customizing `Trainers`, `Validators` and `Predictors` to suit your project needs in the Customization
|
||||||
|
Section.
|
||||||
|
|
||||||
|
[Customization tutorials](engine.md){ .md-button .md-button--primary}
|
||||||
209
docs/yolov5/architecture.md
Normal file
@@ -0,0 +1,209 @@
|
|||||||
|
## 1. Model Structure
|
||||||
|
|
||||||
|
YOLOv5 (v6.0/6.1) consists of:
|
||||||
|
- **Backbone**: `New CSP-Darknet53`
|
||||||
|
- **Neck**: `SPPF`, `New CSP-PAN`
|
||||||
|
- **Head**: `YOLOv3 Head`
|
||||||
|
|
||||||
|
Model structure (`yolov5l.yaml`):
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Some minor changes compared to previous versions:
|
||||||
|
|
||||||
|
1. Replace the `Focus` structure with `6x6 Conv2d`(more efficient, refer #4825)
|
||||||
|
2. Replace the `SPP` structure with `SPPF`(more than double the speed)
|
||||||
|
|
||||||
|
<details markdown>
|
||||||
|
<summary>test code</summary>
|
||||||
|
|
||||||
|
```python
|
||||||
|
import time
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
|
||||||
|
|
||||||
|
class SPP(nn.Module):
|
||||||
|
def __init__(self):
|
||||||
|
super().__init__()
|
||||||
|
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
|
||||||
|
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
|
||||||
|
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
o1 = self.maxpool1(x)
|
||||||
|
o2 = self.maxpool2(x)
|
||||||
|
o3 = self.maxpool3(x)
|
||||||
|
return torch.cat([x, o1, o2, o3], dim=1)
|
||||||
|
|
||||||
|
|
||||||
|
class SPPF(nn.Module):
|
||||||
|
def __init__(self):
|
||||||
|
super().__init__()
|
||||||
|
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
o1 = self.maxpool(x)
|
||||||
|
o2 = self.maxpool(o1)
|
||||||
|
o3 = self.maxpool(o2)
|
||||||
|
return torch.cat([x, o1, o2, o3], dim=1)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
input_tensor = torch.rand(8, 32, 16, 16)
|
||||||
|
spp = SPP()
|
||||||
|
sppf = SPPF()
|
||||||
|
output1 = spp(input_tensor)
|
||||||
|
output2 = sppf(input_tensor)
|
||||||
|
|
||||||
|
print(torch.equal(output1, output2))
|
||||||
|
|
||||||
|
t_start = time.time()
|
||||||
|
for _ in range(100):
|
||||||
|
spp(input_tensor)
|
||||||
|
print(f"spp time: {time.time() - t_start}")
|
||||||
|
|
||||||
|
t_start = time.time()
|
||||||
|
for _ in range(100):
|
||||||
|
sppf(input_tensor)
|
||||||
|
print(f"sppf time: {time.time() - t_start}")
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
```
|
||||||
|
|
||||||
|
result:
|
||||||
|
```
|
||||||
|
True
|
||||||
|
spp time: 0.5373051166534424
|
||||||
|
sppf time: 0.20780706405639648
|
||||||
|
```
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 2. Data Augmentation
|
||||||
|
|
||||||
|
- Mosaic
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/159109235-c7aad8f2-1d4f-41f9-8d5f-b2fde6f2885e.png#pic_center" width=80%>
|
||||||
|
|
||||||
|
- Copy paste
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/159116277-91b45033-6bec-4f82-afc4-41138866628e.png#pic_center" width=80%>
|
||||||
|
|
||||||
|
- Random affine(Rotation, Scale, Translation and Shear)
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/159109326-45cd5acb-14fa-43e7-9235-0f21b0021c7d.png#pic_center" width=80%>
|
||||||
|
|
||||||
|
- MixUp
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/159109361-3b24333b-f481-478b-ae00-df7838f0b5cd.png#pic_center" width=80%>
|
||||||
|
|
||||||
|
- Albumentations
|
||||||
|
- Augment HSV(Hue, Saturation, Value)
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/159109407-83d100ba-1aba-4f4b-aa03-4f048f815981.png#pic_center" width=80%>
|
||||||
|
|
||||||
|
- Random horizontal flip
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/159109429-0d44619a-a76a-49eb-bfc0-6709860c043e.png#pic_center" width=80%>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 3. Training Strategies
|
||||||
|
|
||||||
|
- Multi-scale training(0.5~1.5x)
|
||||||
|
- AutoAnchor(For training custom data)
|
||||||
|
- Warmup and Cosine LR scheduler
|
||||||
|
- EMA(Exponential Moving Average)
|
||||||
|
- Mixed precision
|
||||||
|
- Evolve hyper-parameters
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 4. Others
|
||||||
|
|
||||||
|
### 4.1 Compute Losses
|
||||||
|
|
||||||
|
The YOLOv5 loss consists of three parts:
|
||||||
|
|
||||||
|
- Classes loss(BCE loss)
|
||||||
|
- Objectness loss(BCE loss)
|
||||||
|
- Location loss(CIoU loss)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 4.2 Balance Losses
|
||||||
|
The objectness losses of the three prediction layers(`P3`, `P4`, `P5`) are weighted differently. The balance weights are `[4.0, 1.0, 0.4]` respectively.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 4.3 Eliminate Grid Sensitivity
|
||||||
|
In YOLOv2 and YOLOv3, the formula for calculating the predicted target information is:
|
||||||
|
|
||||||
|
+c_x)
|
||||||
|
+c_y)
|
||||||
|

|
||||||
|

|
||||||
|
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/158508027-8bf63c28-8290-467b-8a3e-4ad09235001a.png#pic_center" width=40%>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
In YOLOv5, the formula is:
|
||||||
|
|
||||||
|
-0.5)+c_x)
|
||||||
|
-0.5)+c_y)
|
||||||
|
)^2)
|
||||||
|
)^2)
|
||||||
|
|
||||||
|
Compare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5).
|
||||||
|
Therefore, offset can easily get 0 or 1.
|
||||||
|
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/158508052-c24bc5e8-05c1-4154-ac97-2e1ec71f582e.png#pic_center" width=40%>
|
||||||
|
|
||||||
|
Compare the height and width scaling ratio(relative to anchor) before and after adjustment. The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training. [refer this issue](https://github.com/ultralytics/yolov5/issues/471#issuecomment-662009779)
|
||||||
|
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/158508089-5ac0c7a3-6358-44b7-863e-a6e45babb842.png#pic_center" width=40%>
|
||||||
|
|
||||||
|
|
||||||
|
### 4.4 Build Targets
|
||||||
|
Match positive samples:
|
||||||
|
|
||||||
|
- Calculate the aspect ratio of GT and Anchor Templates
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
)
|
||||||
|
|
||||||
|
)
|
||||||
|
|
||||||
|
)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/158508119-fbb2e483-7b8c-4975-8e1f-f510d367f8ff.png#pic_center" width=70%>
|
||||||
|
|
||||||
|
- Assign the successfully matched Anchor Templates to the corresponding cells
|
||||||
|
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/158508771-b6e7cab4-8de6-47f9-9abf-cdf14c275dfe.png#pic_center" width=70%>
|
||||||
|
|
||||||
|
- Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.
|
||||||
|
|
||||||
|
<img src="https://user-images.githubusercontent.com/31005897/158508139-9db4e8c2-cf96-47e0-bc80-35d11512f296.png#pic_center" width=70%>
|
||||||
|
|
||||||
|
## Environments
|
||||||
|
|
||||||
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||||
|
|
||||||
|
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||||
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||||
|
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
|
||||||
|
## Status
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
|
||||||
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||||
237
docs/yolov5/clearml.md
Normal file
@@ -0,0 +1,237 @@
|
|||||||
|
# ClearML Integration
|
||||||
|
|
||||||
|
<img align="center" src="https://github.com/thepycoder/clearml_screenshots/raw/main/logos_dark.png#gh-light-mode-only" alt="Clear|ML"><img align="center" src="https://github.com/thepycoder/clearml_screenshots/raw/main/logos_light.png#gh-dark-mode-only" alt="Clear|ML">
|
||||||
|
|
||||||
|
## About ClearML
|
||||||
|
|
||||||
|
[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
|
||||||
|
|
||||||
|
🔨 Track every YOLOv5 training run in the <b>experiment manager</b>
|
||||||
|
|
||||||
|
🔧 Version and easily access your custom training data with the integrated ClearML <b>Data Versioning Tool</b>
|
||||||
|
|
||||||
|
🔦 <b>Remotely train and monitor</b> your YOLOv5 training runs using ClearML Agent
|
||||||
|
|
||||||
|
🔬 Get the very best mAP using ClearML <b>Hyperparameter Optimization</b>
|
||||||
|
|
||||||
|
🔭 Turn your newly trained <b>YOLOv5 model into an API</b> with just a few commands using ClearML Serving
|
||||||
|
|
||||||
|
<br />
|
||||||
|
And so much more. It's up to you how many of these tools you want to use, you can stick to the experiment manager, or chain them all together into an impressive pipeline!
|
||||||
|
<br />
|
||||||
|
<br />
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
<br />
|
||||||
|
<br />
|
||||||
|
|
||||||
|
## 🦾 Setting Things Up
|
||||||
|
|
||||||
|
To keep track of your experiments and/or data, ClearML needs to communicate to a server. You have 2 options to get one:
|
||||||
|
|
||||||
|
Either sign up for free to the [ClearML Hosted Service](https://cutt.ly/yolov5-tutorial-clearml) or you can set up your own server, see [here](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server). Even the server is open-source, so even if you're dealing with sensitive data, you should be good to go!
|
||||||
|
|
||||||
|
1. Install the `clearml` python package:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install clearml
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Connect the ClearML SDK to the server by [creating credentials](https://app.clear.ml/settings/workspace-configuration) (go right top to Settings -> Workspace -> Create new credentials), then execute the command below and follow the instructions:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
clearml-init
|
||||||
|
```
|
||||||
|
|
||||||
|
That's it! You're done 😎
|
||||||
|
|
||||||
|
<br />
|
||||||
|
|
||||||
|
## 🚀 Training YOLOv5 With ClearML
|
||||||
|
|
||||||
|
To enable ClearML experiment tracking, simply install the ClearML pip package.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install clearml>=1.2.0
|
||||||
|
```
|
||||||
|
|
||||||
|
This will enable integration with the YOLOv5 training script. Every training run from now on, will be captured and stored by the ClearML experiment manager.
|
||||||
|
|
||||||
|
If you want to change the `project_name` or `task_name`, use the `--project` and `--name` arguments of the `train.py` script, by default the project will be called `YOLOv5` and the task `Training`.
|
||||||
|
PLEASE NOTE: ClearML uses `/` as a delimiter for subprojects, so be careful when using `/` in your project name!
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
|
||||||
|
```
|
||||||
|
|
||||||
|
or with custom project and task name:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python train.py --project my_project --name my_training --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
|
||||||
|
```
|
||||||
|
|
||||||
|
This will capture:
|
||||||
|
|
||||||
|
- Source code + uncommitted changes
|
||||||
|
- Installed packages
|
||||||
|
- (Hyper)parameters
|
||||||
|
- Model files (use `--save-period n` to save a checkpoint every n epochs)
|
||||||
|
- Console output
|
||||||
|
- Scalars (mAP_0.5, mAP_0.5:0.95, precision, recall, losses, learning rates, ...)
|
||||||
|
- General info such as machine details, runtime, creation date etc.
|
||||||
|
- All produced plots such as label correlogram and confusion matrix
|
||||||
|
- Images with bounding boxes per epoch
|
||||||
|
- Mosaic per epoch
|
||||||
|
- Validation images per epoch
|
||||||
|
- ...
|
||||||
|
|
||||||
|
That's a lot right? 🤯
|
||||||
|
Now, we can visualize all of this information in the ClearML UI to get an overview of our training progress. Add custom columns to the table view (such as e.g. mAP_0.5) so you can easily sort on the best performing model. Or select multiple experiments and directly compare them!
|
||||||
|
|
||||||
|
There even more we can do with all of this information, like hyperparameter optimization and remote execution, so keep reading if you want to see how that works!
|
||||||
|
|
||||||
|
<br />
|
||||||
|
|
||||||
|
## 🔗 Dataset Version Management
|
||||||
|
|
||||||
|
Versioning your data separately from your code is generally a good idea and makes it easy to acquire the latest version too. This repository supports supplying a dataset version ID, and it will make sure to get the data if it's not there yet. Next to that, this workflow also saves the used dataset ID as part of the task parameters, so you will always know for sure which data was used in which experiment!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Prepare Your Dataset
|
||||||
|
|
||||||
|
The YOLOv5 repository supports a number of different datasets by using yaml files containing their information. By default datasets are downloaded to the `../datasets` folder in relation to the repository root folder. So if you downloaded the `coco128` dataset using the link in the yaml or with the scripts provided by yolov5, you get this folder structure:
|
||||||
|
|
||||||
|
```
|
||||||
|
..
|
||||||
|
|_ yolov5
|
||||||
|
|_ datasets
|
||||||
|
|_ coco128
|
||||||
|
|_ images
|
||||||
|
|_ labels
|
||||||
|
|_ LICENSE
|
||||||
|
|_ README.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
But this can be any dataset you wish. Feel free to use your own, as long as you keep to this folder structure.
|
||||||
|
|
||||||
|
Next, ⚠️**copy the corresponding yaml file to the root of the dataset folder**⚠️. This yaml files contains the information ClearML will need to properly use the dataset. You can make this yourself too, of course, just follow the structure of the example yamls.
|
||||||
|
|
||||||
|
Basically we need the following keys: `path`, `train`, `test`, `val`, `nc`, `names`.
|
||||||
|
|
||||||
|
```
|
||||||
|
..
|
||||||
|
|_ yolov5
|
||||||
|
|_ datasets
|
||||||
|
|_ coco128
|
||||||
|
|_ images
|
||||||
|
|_ labels
|
||||||
|
|_ coco128.yaml # <---- HERE!
|
||||||
|
|_ LICENSE
|
||||||
|
|_ README.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
### Upload Your Dataset
|
||||||
|
|
||||||
|
To get this dataset into ClearML as a versioned dataset, go to the dataset root folder and run the following command:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd coco128
|
||||||
|
clearml-data sync --project YOLOv5 --name coco128 --folder .
|
||||||
|
```
|
||||||
|
|
||||||
|
The command `clearml-data sync` is actually a shorthand command. You could also run these commands one after the other:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Optionally add --parent <parent_dataset_id> if you want to base
|
||||||
|
# this version on another dataset version, so no duplicate files are uploaded!
|
||||||
|
clearml-data create --name coco128 --project YOLOv5
|
||||||
|
clearml-data add --files .
|
||||||
|
clearml-data close
|
||||||
|
```
|
||||||
|
|
||||||
|
### Run Training Using A ClearML Dataset
|
||||||
|
|
||||||
|
Now that you have a ClearML dataset, you can very simply use it to train custom YOLOv5 🚀 models!
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python train.py --img 640 --batch 16 --epochs 3 --data clearml://<your_dataset_id> --weights yolov5s.pt --cache
|
||||||
|
```
|
||||||
|
|
||||||
|
<br />
|
||||||
|
|
||||||
|
## 👀 Hyperparameter Optimization
|
||||||
|
|
||||||
|
Now that we have our experiments and data versioned, it's time to take a look at what we can build on top!
|
||||||
|
|
||||||
|
Using the code information, installed packages and environment details, the experiment itself is now **completely reproducible**. In fact, ClearML allows you to clone an experiment and even change its parameters. We can then just rerun it with these new parameters automatically, this is basically what HPO does!
|
||||||
|
|
||||||
|
To **run hyperparameter optimization locally**, we've included a pre-made script for you. Just make sure a training task has been run at least once, so it is in the ClearML experiment manager, we will essentially clone it and change its hyperparameters.
|
||||||
|
|
||||||
|
You'll need to fill in the ID of this `template task` in the script found at `utils/loggers/clearml/hpo.py` and then just run it :) You can change `task.execute_locally()` to `task.execute()` to put it in a ClearML queue and have a remote agent work on it instead.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# To use optuna, install it first, otherwise you can change the optimizer to just be RandomSearch
|
||||||
|
pip install optuna
|
||||||
|
python utils/loggers/clearml/hpo.py
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 🤯 Remote Execution (advanced)
|
||||||
|
|
||||||
|
Running HPO locally is really handy, but what if we want to run our experiments on a remote machine instead? Maybe you have access to a very powerful GPU machine on-site, or you have some budget to use cloud GPUs.
|
||||||
|
This is where the ClearML Agent comes into play. Check out what the agent can do here:
|
||||||
|
|
||||||
|
- [YouTube video](https://youtu.be/MX3BrXnaULs)
|
||||||
|
- [Documentation](https://clear.ml/docs/latest/docs/clearml_agent)
|
||||||
|
|
||||||
|
In short: every experiment tracked by the experiment manager contains enough information to reproduce it on a different machine (installed packages, uncommitted changes etc.). So a ClearML agent does just that: it listens to a queue for incoming tasks and when it finds one, it recreates the environment and runs it while still reporting scalars, plots etc. to the experiment manager.
|
||||||
|
|
||||||
|
You can turn any machine (a cloud VM, a local GPU machine, your own laptop ... ) into a ClearML agent by simply running:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
clearml-agent daemon --queue <queues_to_listen_to> [--docker]
|
||||||
|
```
|
||||||
|
|
||||||
|
### Cloning, Editing And Enqueuing
|
||||||
|
|
||||||
|
With our agent running, we can give it some work. Remember from the HPO section that we can clone a task and edit the hyperparameters? We can do that from the interface too!
|
||||||
|
|
||||||
|
🪄 Clone the experiment by right-clicking it
|
||||||
|
|
||||||
|
🎯 Edit the hyperparameters to what you wish them to be
|
||||||
|
|
||||||
|
⏳ Enqueue the task to any of the queues by right-clicking it
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Executing A Task Remotely
|
||||||
|
|
||||||
|
Now you can clone a task like we explained above, or simply mark your current script by adding `task.execute_remotely()` and on execution it will be put into a queue, for the agent to start working on!
|
||||||
|
|
||||||
|
To run the YOLOv5 training script remotely, all you have to do is add this line to the training.py script after the clearml logger has been instantiated:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# ...
|
||||||
|
# Loggers
|
||||||
|
data_dict = None
|
||||||
|
if RANK in {-1, 0}:
|
||||||
|
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
|
||||||
|
if loggers.clearml:
|
||||||
|
loggers.clearml.task.execute_remotely(queue="my_queue") # <------ ADD THIS LINE
|
||||||
|
# Data_dict is either None is user did not choose for ClearML dataset or is filled in by ClearML
|
||||||
|
data_dict = loggers.clearml.data_dict
|
||||||
|
# ...
|
||||||
|
```
|
||||||
|
|
||||||
|
When running the training script after this change, python will run the script up until that line, after which it will package the code and send it to the queue instead!
|
||||||
|
|
||||||
|
### Autoscaling workers
|
||||||
|
|
||||||
|
ClearML comes with autoscalers too! This tool will automatically spin up new remote machines in the cloud of your choice (AWS, GCP, Azure) and turn them into ClearML agents for you whenever there are experiments detected in the queue. Once the tasks are processed, the autoscaler will automatically shut down the remote machines, and you stop paying!
|
||||||
|
|
||||||
|
Check out the autoscalers getting started video below.
|
||||||
|
|
||||||
|
[](https://youtu.be/j4XVMAaUt3E)
|
||||||
258
docs/yolov5/comet.md
Normal file
@@ -0,0 +1,258 @@
|
|||||||
|
<img src="https://cdn.comet.ml/img/notebook_logo.png">
|
||||||
|
|
||||||
|
# YOLOv5 with Comet
|
||||||
|
|
||||||
|
This guide will cover how to use YOLOv5 with [Comet](https://bit.ly/yolov5-readme-comet2)
|
||||||
|
|
||||||
|
# About Comet
|
||||||
|
|
||||||
|
Comet builds tools that help data scientists, engineers, and team leaders accelerate and optimize machine learning and deep learning models.
|
||||||
|
|
||||||
|
Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://www.comet.com/docs/v2/guides/comet-dashboard/code-panels/about-panels/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)!
|
||||||
|
Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
|
||||||
|
|
||||||
|
# Getting Started
|
||||||
|
|
||||||
|
## Install Comet
|
||||||
|
|
||||||
|
```shell
|
||||||
|
pip install comet_ml
|
||||||
|
```
|
||||||
|
|
||||||
|
## Configure Comet Credentials
|
||||||
|
|
||||||
|
There are two ways to configure Comet with YOLOv5.
|
||||||
|
|
||||||
|
You can either set your credentials through environment variables
|
||||||
|
|
||||||
|
**Environment Variables**
|
||||||
|
|
||||||
|
```shell
|
||||||
|
export COMET_API_KEY=<Your Comet API Key>
|
||||||
|
export COMET_PROJECT_NAME=<Your Comet Project Name> # This will default to 'yolov5'
|
||||||
|
```
|
||||||
|
|
||||||
|
Or create a `.comet.config` file in your working directory and set your credentials there.
|
||||||
|
|
||||||
|
**Comet Configuration File**
|
||||||
|
|
||||||
|
```
|
||||||
|
[comet]
|
||||||
|
api_key=<Your Comet API Key>
|
||||||
|
project_name=<Your Comet Project Name> # This will default to 'yolov5'
|
||||||
|
```
|
||||||
|
|
||||||
|
## Run the Training Script
|
||||||
|
|
||||||
|
```shell
|
||||||
|
# Train YOLOv5s on COCO128 for 5 epochs
|
||||||
|
python train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov5s.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
That's it! Comet will automatically log your hyperparameters, command line arguments, training and validation metrics. You can visualize and analyze your runs in the Comet UI
|
||||||
|
|
||||||
|
<img width="1920" alt="yolo-ui" src="https://user-images.githubusercontent.com/26833433/202851203-164e94e1-2238-46dd-91f8-de020e9d6b41.png">
|
||||||
|
|
||||||
|
# Try out an Example!
|
||||||
|
|
||||||
|
Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
|
||||||
|
|
||||||
|
Or better yet, try it out yourself in this Colab Notebook
|
||||||
|
|
||||||
|
[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
|
||||||
|
|
||||||
|
# Log automatically
|
||||||
|
|
||||||
|
By default, Comet will log the following items
|
||||||
|
|
||||||
|
## Metrics
|
||||||
|
|
||||||
|
- Box Loss, Object Loss, Classification Loss for the training and validation data
|
||||||
|
- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
|
||||||
|
- Precision and Recall for the validation data
|
||||||
|
|
||||||
|
## Parameters
|
||||||
|
|
||||||
|
- Model Hyperparameters
|
||||||
|
- All parameters passed through the command line options
|
||||||
|
|
||||||
|
## Visualizations
|
||||||
|
|
||||||
|
- Confusion Matrix of the model predictions on the validation data
|
||||||
|
- Plots for the PR and F1 curves across all classes
|
||||||
|
- Correlogram of the Class Labels
|
||||||
|
|
||||||
|
# Configure Comet Logging
|
||||||
|
|
||||||
|
Comet can be configured to log additional data either through command line flags passed to the training script
|
||||||
|
or through environment variables.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
|
||||||
|
export COMET_MODEL_NAME=<your model name> #Set the name for the saved model. Defaults to yolov5
|
||||||
|
export COMET_LOG_CONFUSION_MATRIX=false # Set to disable logging a Comet Confusion Matrix. Defaults to true
|
||||||
|
export COMET_MAX_IMAGE_UPLOADS=<number of allowed images to upload to Comet> # Controls how many total image predictions to log to Comet. Defaults to 100.
|
||||||
|
export COMET_LOG_PER_CLASS_METRICS=true # Set to log evaluation metrics for each detected class at the end of training. Defaults to false
|
||||||
|
export COMET_DEFAULT_CHECKPOINT_FILENAME=<your checkpoint filename> # Set this if you would like to resume training from a different checkpoint. Defaults to 'last.pt'
|
||||||
|
export COMET_LOG_BATCH_LEVEL_METRICS=true # Set this if you would like to log training metrics at the batch level. Defaults to false.
|
||||||
|
export COMET_LOG_PREDICTIONS=true # Set this to false to disable logging model predictions
|
||||||
|
```
|
||||||
|
|
||||||
|
## Logging Checkpoints with Comet
|
||||||
|
|
||||||
|
Logging Models to Comet is disabled by default. To enable it, pass the `save-period` argument to the training script. This will save the
|
||||||
|
logged checkpoints to Comet based on the interval value provided by `save-period`
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python train.py \
|
||||||
|
--img 640 \
|
||||||
|
--batch 16 \
|
||||||
|
--epochs 5 \
|
||||||
|
--data coco128.yaml \
|
||||||
|
--weights yolov5s.pt \
|
||||||
|
--save-period 1
|
||||||
|
```
|
||||||
|
|
||||||
|
## Logging Model Predictions
|
||||||
|
|
||||||
|
By default, model predictions (images, ground truth labels and bounding boxes) will be logged to Comet.
|
||||||
|
|
||||||
|
You can control the frequency of logged predictions and the associated images by passing the `bbox_interval` command line argument. Predictions can be visualized using Comet's Object Detection Custom Panel. This frequency corresponds to every Nth batch of data per epoch. In the example below, we are logging every 2nd batch of data for each epoch.
|
||||||
|
|
||||||
|
**Note:** The YOLOv5 validation dataloader will default to a batch size of 32, so you will have to set the logging frequency accordingly.
|
||||||
|
|
||||||
|
Here is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python train.py \
|
||||||
|
--img 640 \
|
||||||
|
--batch 16 \
|
||||||
|
--epochs 5 \
|
||||||
|
--data coco128.yaml \
|
||||||
|
--weights yolov5s.pt \
|
||||||
|
--bbox_interval 2
|
||||||
|
```
|
||||||
|
|
||||||
|
### Controlling the number of Prediction Images logged to Comet
|
||||||
|
|
||||||
|
When logging predictions from YOLOv5, Comet will log the images associated with each set of predictions. By default a maximum of 100 validation images are logged. You can increase or decrease this number using the `COMET_MAX_IMAGE_UPLOADS` environment variable.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
env COMET_MAX_IMAGE_UPLOADS=200 python train.py \
|
||||||
|
--img 640 \
|
||||||
|
--batch 16 \
|
||||||
|
--epochs 5 \
|
||||||
|
--data coco128.yaml \
|
||||||
|
--weights yolov5s.pt \
|
||||||
|
--bbox_interval 1
|
||||||
|
```
|
||||||
|
|
||||||
|
### Logging Class Level Metrics
|
||||||
|
|
||||||
|
Use the `COMET_LOG_PER_CLASS_METRICS` environment variable to log mAP, precision, recall, f1 for each class.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
env COMET_LOG_PER_CLASS_METRICS=true python train.py \
|
||||||
|
--img 640 \
|
||||||
|
--batch 16 \
|
||||||
|
--epochs 5 \
|
||||||
|
--data coco128.yaml \
|
||||||
|
--weights yolov5s.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
## Uploading a Dataset to Comet Artifacts
|
||||||
|
|
||||||
|
If you would like to store your data using [Comet Artifacts](https://www.comet.com/docs/v2/guides/data-management/using-artifacts/#learn-more?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github), you can do so using the `upload_dataset` flag.
|
||||||
|
|
||||||
|
The dataset be organized in the way described in the [YOLOv5 documentation](train_custom_data.md). The dataset config `yaml` file must follow the same format as that of the `coco128.yaml` file.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python train.py \
|
||||||
|
--img 640 \
|
||||||
|
--batch 16 \
|
||||||
|
--epochs 5 \
|
||||||
|
--data coco128.yaml \
|
||||||
|
--weights yolov5s.pt \
|
||||||
|
--upload_dataset
|
||||||
|
```
|
||||||
|
|
||||||
|
You can find the uploaded dataset in the Artifacts tab in your Comet Workspace
|
||||||
|
<img width="1073" alt="artifact-1" src="https://user-images.githubusercontent.com/7529846/186929193-162718bf-ec7b-4eb9-8c3b-86b3763ef8ea.png">
|
||||||
|
|
||||||
|
You can preview the data directly in the Comet UI.
|
||||||
|
<img width="1082" alt="artifact-2" src="https://user-images.githubusercontent.com/7529846/186929215-432c36a9-c109-4eb0-944b-84c2786590d6.png">
|
||||||
|
|
||||||
|
Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
|
||||||
|
<img width="963" alt="artifact-3" src="https://user-images.githubusercontent.com/7529846/186929256-9d44d6eb-1a19-42de-889a-bcbca3018f2e.png">
|
||||||
|
|
||||||
|
### Using a saved Artifact
|
||||||
|
|
||||||
|
If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
|
||||||
|
|
||||||
|
```
|
||||||
|
# contents of artifact.yaml file
|
||||||
|
path: "comet://<workspace name>/<artifact name>:<artifact version or alias>"
|
||||||
|
```
|
||||||
|
|
||||||
|
Then pass this file to your training script in the following way
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python train.py \
|
||||||
|
--img 640 \
|
||||||
|
--batch 16 \
|
||||||
|
--epochs 5 \
|
||||||
|
--data artifact.yaml \
|
||||||
|
--weights yolov5s.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
Artifacts also allow you to track the lineage of data as it flows through your Experimentation workflow. Here you can see a graph that shows you all the experiments that have used your uploaded dataset.
|
||||||
|
<img width="1391" alt="artifact-4" src="https://user-images.githubusercontent.com/7529846/186929264-4c4014fa-fe51-4f3c-a5c5-f6d24649b1b4.png">
|
||||||
|
|
||||||
|
## Resuming a Training Run
|
||||||
|
|
||||||
|
If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
|
||||||
|
|
||||||
|
The Run Path has the following format `comet://<your workspace name>/<your project name>/<experiment id>`.
|
||||||
|
|
||||||
|
This will restore the run to its state before the interruption, which includes restoring the model from a checkpoint, restoring all hyperparameters and training arguments and downloading Comet dataset Artifacts if they were used in the original run. The resumed run will continue logging to the existing Experiment in the Comet UI
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python train.py \
|
||||||
|
--resume "comet://<your run path>"
|
||||||
|
```
|
||||||
|
|
||||||
|
## Hyperparameter Search with the Comet Optimizer
|
||||||
|
|
||||||
|
YOLOv5 is also integrated with Comet's Optimizer, making is simple to visualize hyperparameter sweeps in the Comet UI.
|
||||||
|
|
||||||
|
### Configuring an Optimizer Sweep
|
||||||
|
|
||||||
|
To configure the Comet Optimizer, you will have to create a JSON file with the information about the sweep. An example file has been provided in `utils/loggers/comet/optimizer_config.json`
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python utils/loggers/comet/hpo.py \
|
||||||
|
--comet_optimizer_config "utils/loggers/comet/optimizer_config.json"
|
||||||
|
```
|
||||||
|
|
||||||
|
The `hpo.py` script accepts the same arguments as `train.py`. If you wish to pass additional arguments to your sweep simply add them after
|
||||||
|
the script.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python utils/loggers/comet/hpo.py \
|
||||||
|
--comet_optimizer_config "utils/loggers/comet/optimizer_config.json" \
|
||||||
|
--save-period 1 \
|
||||||
|
--bbox_interval 1
|
||||||
|
```
|
||||||
|
|
||||||
|
### Running a Sweep in Parallel
|
||||||
|
|
||||||
|
```shell
|
||||||
|
comet optimizer -j <set number of workers> utils/loggers/comet/hpo.py \
|
||||||
|
utils/loggers/comet/optimizer_config.json"
|
||||||
|
```
|
||||||
|
|
||||||
|
### Visualizing Results
|
||||||
|
|
||||||
|
Comet provides a number of ways to visualize the results of your sweep. Take a look at a [project with a completed sweep here](https://www.comet.com/examples/comet-example-yolov5/view/PrlArHGuuhDTKC1UuBmTtOSXD/panels?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
|
||||||
|
|
||||||
|
<img width="1626" alt="hyperparameter-yolo" src="https://user-images.githubusercontent.com/7529846/186914869-7dc1de14-583f-4323-967b-c9a66a29e495.png">
|
||||||
137
docs/yolov5/ensemble.md
Normal file
@@ -0,0 +1,137 @@
|
|||||||
|
📚 This guide explains how to use YOLOv5 🚀 **model ensembling** during testing and inference for improved mAP and Recall.
|
||||||
|
UPDATED 25 September 2022.
|
||||||
|
|
||||||
|
From [https://en.wikipedia.org/wiki/Ensemble_learning](https://en.wikipedia.org/wiki/Ensemble_learning):
|
||||||
|
> Ensemble modeling is a process where multiple diverse models are created to predict an outcome, either by using many different modeling algorithms or using different training data sets. The ensemble model then aggregates the prediction of each base model and results in once final prediction for the unseen data. The motivation for using ensemble models is to reduce the generalization error of the prediction. As long as the base models are diverse and independent, the prediction error of the model decreases when the ensemble approach is used. The approach seeks the wisdom of crowds in making a prediction. Even though the ensemble model has multiple base models within the model, it acts and performs as a single model.
|
||||||
|
|
||||||
|
|
||||||
|
## Before You Start
|
||||||
|
|
||||||
|
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ultralytics/yolov5 # clone
|
||||||
|
cd yolov5
|
||||||
|
pip install -r requirements.txt # install
|
||||||
|
```
|
||||||
|
|
||||||
|
## Test Normally
|
||||||
|
|
||||||
|
Before ensembling we want to establish the baseline performance of a single model. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
|
||||||
|
```bash
|
||||||
|
python val.py --weights yolov5x.pt --data coco.yaml --img 640 --half
|
||||||
|
```
|
||||||
|
|
||||||
|
Output:
|
||||||
|
```shell
|
||||||
|
val: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
|
||||||
|
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||||
|
|
||||||
|
Fusing layers...
|
||||||
|
Model Summary: 476 layers, 87730285 parameters, 0 gradients
|
||||||
|
|
||||||
|
val: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2846.03it/s]
|
||||||
|
val: New cache created: ../datasets/coco/val2017.cache
|
||||||
|
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [02:30<00:00, 1.05it/s]
|
||||||
|
all 5000 36335 0.746 0.626 0.68 0.49
|
||||||
|
Speed: 0.1ms pre-process, 22.4ms inference, 1.4ms NMS per image at shape (32, 3, 640, 640) # <--- baseline speed
|
||||||
|
|
||||||
|
Evaluating pycocotools mAP... saving runs/val/exp/yolov5x_predictions.json...
|
||||||
|
...
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.504 # <--- baseline mAP
|
||||||
|
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.688
|
||||||
|
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.546
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.351
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.551
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.644
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.382
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.628
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.681 # <--- baseline mAR
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.524
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.735
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.826
|
||||||
|
```
|
||||||
|
|
||||||
|
## Ensemble Test
|
||||||
|
|
||||||
|
Multiple pretrained models may be ensembled together at test and inference time by simply appending extra models to the `--weights` argument in any existing val.py or detect.py command. This example tests an ensemble of 2 models together:
|
||||||
|
- YOLOv5x
|
||||||
|
- YOLOv5l6
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python val.py --weights yolov5x.pt yolov5l6.pt --data coco.yaml --img 640 --half
|
||||||
|
```
|
||||||
|
|
||||||
|
Output:
|
||||||
|
```shell
|
||||||
|
val: data=./data/coco.yaml, weights=['yolov5x.pt', 'yolov5l6.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
|
||||||
|
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||||
|
|
||||||
|
Fusing layers...
|
||||||
|
Model Summary: 476 layers, 87730285 parameters, 0 gradients # Model 1
|
||||||
|
Fusing layers...
|
||||||
|
Model Summary: 501 layers, 77218620 parameters, 0 gradients # Model 2
|
||||||
|
Ensemble created with ['yolov5x.pt', 'yolov5l6.pt'] # Ensemble notice
|
||||||
|
|
||||||
|
val: Scanning '../datasets/coco/val2017.cache' images and labels... 4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:00<00:00, 49695545.02it/s]
|
||||||
|
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [03:58<00:00, 1.52s/it]
|
||||||
|
all 5000 36335 0.747 0.637 0.692 0.502
|
||||||
|
Speed: 0.1ms pre-process, 39.5ms inference, 2.0ms NMS per image at shape (32, 3, 640, 640) # <--- ensemble speed
|
||||||
|
|
||||||
|
Evaluating pycocotools mAP... saving runs/val/exp3/yolov5x_predictions.json...
|
||||||
|
...
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.515 # <--- ensemble mAP
|
||||||
|
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.699
|
||||||
|
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.557
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.356
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.563
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.668
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.387
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.638
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.689 # <--- ensemble mAR
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.526
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.743
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.844
|
||||||
|
```
|
||||||
|
|
||||||
|
## Ensemble Inference
|
||||||
|
|
||||||
|
Append extra models to the `--weights` argument to run ensemble inference:
|
||||||
|
```bash
|
||||||
|
python detect.py --weights yolov5x.pt yolov5l6.pt --img 640 --source data/images
|
||||||
|
```
|
||||||
|
|
||||||
|
Output:
|
||||||
|
```bash
|
||||||
|
detect: weights=['yolov5x.pt', 'yolov5l6.pt'], source=data/images, imgsz=640, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False
|
||||||
|
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||||
|
|
||||||
|
Fusing layers...
|
||||||
|
Model Summary: 476 layers, 87730285 parameters, 0 gradients
|
||||||
|
Fusing layers...
|
||||||
|
Model Summary: 501 layers, 77218620 parameters, 0 gradients
|
||||||
|
Ensemble created with ['yolov5x.pt', 'yolov5l6.pt']
|
||||||
|
|
||||||
|
image 1/2 /content/yolov5/data/images/bus.jpg: 640x512 4 persons, 1 bus, 1 tie, Done. (0.063s)
|
||||||
|
image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 3 persons, 2 ties, Done. (0.056s)
|
||||||
|
Results saved to runs/detect/exp2
|
||||||
|
Done. (0.223s)
|
||||||
|
```
|
||||||
|
<img src="https://user-images.githubusercontent.com/26833433/124489091-ea4f9a00-ddb0-11eb-8ef1-d6f335c97f6f.jpg" width="500">
|
||||||
|
|
||||||
|
|
||||||
|
## Environments
|
||||||
|
|
||||||
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||||
|
|
||||||
|
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||||
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||||
|
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
|
||||||
|
## Status
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
|
||||||
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||||
236
docs/yolov5/export.md
Normal file
@@ -0,0 +1,236 @@
|
|||||||
|
# TFLite, ONNX, CoreML, TensorRT Export
|
||||||
|
|
||||||
|
📚 This guide explains how to export a trained YOLOv5 🚀 model from PyTorch to ONNX and TorchScript formats.
|
||||||
|
UPDATED 8 December 2022.
|
||||||
|
|
||||||
|
## Before You Start
|
||||||
|
|
||||||
|
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ultralytics/yolov5 # clone
|
||||||
|
cd yolov5
|
||||||
|
pip install -r requirements.txt # install
|
||||||
|
```
|
||||||
|
|
||||||
|
For [TensorRT](https://developer.nvidia.com/tensorrt) export example (requires GPU) see our Colab [notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb#scrollTo=VTRwsvA9u7ln&line=2&uniqifier=1) appendix section. <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
||||||
|
|
||||||
|
## Formats
|
||||||
|
|
||||||
|
YOLOv5 inference is officially supported in 11 formats:
|
||||||
|
|
||||||
|
💡 ProTip: Export to ONNX or OpenVINO for up to 3x CPU speedup. See [CPU Benchmarks](https://github.com/ultralytics/yolov5/pull/6613).
|
||||||
|
💡 ProTip: Export to TensorRT for up to 5x GPU speedup. See [GPU Benchmarks](https://github.com/ultralytics/yolov5/pull/6963).
|
||||||
|
|
||||||
|
| Format | `export.py --include` | Model |
|
||||||
|
|:---------------------------------------------------------------------------|:----------------------|:--------------------------|
|
||||||
|
| [PyTorch](https://pytorch.org/) | - | `yolov5s.pt` |
|
||||||
|
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov5s.torchscript` |
|
||||||
|
| [ONNX](https://onnx.ai/) | `onnx` | `yolov5s.onnx` |
|
||||||
|
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov5s_openvino_model/` |
|
||||||
|
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov5s.engine` |
|
||||||
|
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov5s.mlmodel` |
|
||||||
|
| [TensorFlow SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov5s_saved_model/` |
|
||||||
|
| [TensorFlow GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov5s.pb` |
|
||||||
|
| [TensorFlow Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov5s.tflite` |
|
||||||
|
| [TensorFlow Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov5s_edgetpu.tflite` |
|
||||||
|
| [TensorFlow.js](https://www.tensorflow.org/js) | `tfjs` | `yolov5s_web_model/` |
|
||||||
|
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov5s_paddle_model/` |
|
||||||
|
|
||||||
|
|
||||||
|
## Benchmarks
|
||||||
|
|
||||||
|
Benchmarks below run on a Colab Pro with the YOLOv5 tutorial notebook <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>. To reproduce:
|
||||||
|
```bash
|
||||||
|
python benchmarks.py --weights yolov5s.pt --imgsz 640 --device 0
|
||||||
|
```
|
||||||
|
|
||||||
|
### Colab Pro V100 GPU
|
||||||
|
|
||||||
|
```
|
||||||
|
benchmarks: weights=/content/yolov5/yolov5s.pt, imgsz=640, batch_size=1, data=/content/yolov5/data/coco128.yaml, device=0, half=False, test=False
|
||||||
|
Checking setup...
|
||||||
|
YOLOv5 🚀 v6.1-135-g7926afc torch 1.10.0+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)
|
||||||
|
Setup complete ✅ (8 CPUs, 51.0 GB RAM, 46.7/166.8 GB disk)
|
||||||
|
|
||||||
|
Benchmarks complete (458.07s)
|
||||||
|
Format mAP@0.5:0.95 Inference time (ms)
|
||||||
|
0 PyTorch 0.4623 10.19
|
||||||
|
1 TorchScript 0.4623 6.85
|
||||||
|
2 ONNX 0.4623 14.63
|
||||||
|
3 OpenVINO NaN NaN
|
||||||
|
4 TensorRT 0.4617 1.89
|
||||||
|
5 CoreML NaN NaN
|
||||||
|
6 TensorFlow SavedModel 0.4623 21.28
|
||||||
|
7 TensorFlow GraphDef 0.4623 21.22
|
||||||
|
8 TensorFlow Lite NaN NaN
|
||||||
|
9 TensorFlow Edge TPU NaN NaN
|
||||||
|
10 TensorFlow.js NaN NaN
|
||||||
|
```
|
||||||
|
|
||||||
|
### Colab Pro CPU
|
||||||
|
|
||||||
|
```
|
||||||
|
benchmarks: weights=/content/yolov5/yolov5s.pt, imgsz=640, batch_size=1, data=/content/yolov5/data/coco128.yaml, device=cpu, half=False, test=False
|
||||||
|
Checking setup...
|
||||||
|
YOLOv5 🚀 v6.1-135-g7926afc torch 1.10.0+cu111 CPU
|
||||||
|
Setup complete ✅ (8 CPUs, 51.0 GB RAM, 41.5/166.8 GB disk)
|
||||||
|
|
||||||
|
Benchmarks complete (241.20s)
|
||||||
|
Format mAP@0.5:0.95 Inference time (ms)
|
||||||
|
0 PyTorch 0.4623 127.61
|
||||||
|
1 TorchScript 0.4623 131.23
|
||||||
|
2 ONNX 0.4623 69.34
|
||||||
|
3 OpenVINO 0.4623 66.52
|
||||||
|
4 TensorRT NaN NaN
|
||||||
|
5 CoreML NaN NaN
|
||||||
|
6 TensorFlow SavedModel 0.4623 123.79
|
||||||
|
7 TensorFlow GraphDef 0.4623 121.57
|
||||||
|
8 TensorFlow Lite 0.4623 316.61
|
||||||
|
9 TensorFlow Edge TPU NaN NaN
|
||||||
|
10 TensorFlow.js NaN NaN
|
||||||
|
```
|
||||||
|
|
||||||
|
## Export a Trained YOLOv5 Model
|
||||||
|
|
||||||
|
This command exports a pretrained YOLOv5s model to TorchScript and ONNX formats. `yolov5s.pt` is the 'small' model, the second-smallest model available. Other options are `yolov5n.pt`, `yolov5m.pt`, `yolov5l.pt` and `yolov5x.pt`, along with their P6 counterparts i.e. `yolov5s6.pt` or you own custom training checkpoint i.e. `runs/exp/weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
|
||||||
|
```bash
|
||||||
|
python export.py --weights yolov5s.pt --include torchscript onnx
|
||||||
|
```
|
||||||
|
|
||||||
|
💡 ProTip: Add `--half` to export models at FP16 half precision for smaller file sizes
|
||||||
|
|
||||||
|
Output:
|
||||||
|
```bash
|
||||||
|
export: data=data/coco128.yaml, weights=['yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['torchscript', 'onnx']
|
||||||
|
YOLOv5 🚀 v6.2-104-ge3e5122 Python-3.7.13 torch-1.12.1+cu113 CPU
|
||||||
|
|
||||||
|
Downloading https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt to yolov5s.pt...
|
||||||
|
100% 14.1M/14.1M [00:00<00:00, 274MB/s]
|
||||||
|
|
||||||
|
Fusing layers...
|
||||||
|
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
|
||||||
|
|
||||||
|
PyTorch: starting from yolov5s.pt with output shape (1, 25200, 85) (14.1 MB)
|
||||||
|
|
||||||
|
TorchScript: starting export with torch 1.12.1+cu113...
|
||||||
|
TorchScript: export success ✅ 1.7s, saved as yolov5s.torchscript (28.1 MB)
|
||||||
|
|
||||||
|
ONNX: starting export with onnx 1.12.0...
|
||||||
|
ONNX: export success ✅ 2.3s, saved as yolov5s.onnx (28.0 MB)
|
||||||
|
|
||||||
|
Export complete (5.5s)
|
||||||
|
Results saved to /content/yolov5
|
||||||
|
Detect: python detect.py --weights yolov5s.onnx
|
||||||
|
Validate: python val.py --weights yolov5s.onnx
|
||||||
|
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.onnx')
|
||||||
|
Visualize: https://netron.app/
|
||||||
|
```
|
||||||
|
|
||||||
|
The 3 exported models will be saved alongside the original PyTorch model:
|
||||||
|
<p align="center"><img width="700" src="https://user-images.githubusercontent.com/26833433/122827190-57a8f880-d2e4-11eb-860e-dbb7f9fc57fb.png"></p>
|
||||||
|
|
||||||
|
[Netron Viewer](https://github.com/lutzroeder/netron) is recommended for visualizing exported models:
|
||||||
|
<p align="center"><img width="850" src="https://user-images.githubusercontent.com/26833433/191003260-f94011a7-5b2e-4fe3-93c1-e1a935e0a728.png"></p>
|
||||||
|
|
||||||
|
|
||||||
|
## Exported Model Usage Examples
|
||||||
|
|
||||||
|
`detect.py` runs inference on exported models:
|
||||||
|
```bash
|
||||||
|
python detect.py --weights yolov5s.pt # PyTorch
|
||||||
|
yolov5s.torchscript # TorchScript
|
||||||
|
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
|
||||||
|
yolov5s_openvino_model # OpenVINO
|
||||||
|
yolov5s.engine # TensorRT
|
||||||
|
yolov5s.mlmodel # CoreML (macOS only)
|
||||||
|
yolov5s_saved_model # TensorFlow SavedModel
|
||||||
|
yolov5s.pb # TensorFlow GraphDef
|
||||||
|
yolov5s.tflite # TensorFlow Lite
|
||||||
|
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
|
||||||
|
yolov5s_paddle_model # PaddlePaddle
|
||||||
|
```
|
||||||
|
|
||||||
|
`val.py` runs validation on exported models:
|
||||||
|
```bash
|
||||||
|
python val.py --weights yolov5s.pt # PyTorch
|
||||||
|
yolov5s.torchscript # TorchScript
|
||||||
|
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
|
||||||
|
yolov5s_openvino_model # OpenVINO
|
||||||
|
yolov5s.engine # TensorRT
|
||||||
|
yolov5s.mlmodel # CoreML (macOS Only)
|
||||||
|
yolov5s_saved_model # TensorFlow SavedModel
|
||||||
|
yolov5s.pb # TensorFlow GraphDef
|
||||||
|
yolov5s.tflite # TensorFlow Lite
|
||||||
|
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
|
||||||
|
yolov5s_paddle_model # PaddlePaddle
|
||||||
|
```
|
||||||
|
|
||||||
|
Use PyTorch Hub with exported YOLOv5 models:
|
||||||
|
``` python
|
||||||
|
import torch
|
||||||
|
|
||||||
|
# Model
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.pt')
|
||||||
|
'yolov5s.torchscript ') # TorchScript
|
||||||
|
'yolov5s.onnx') # ONNX Runtime
|
||||||
|
'yolov5s_openvino_model') # OpenVINO
|
||||||
|
'yolov5s.engine') # TensorRT
|
||||||
|
'yolov5s.mlmodel') # CoreML (macOS Only)
|
||||||
|
'yolov5s_saved_model') # TensorFlow SavedModel
|
||||||
|
'yolov5s.pb') # TensorFlow GraphDef
|
||||||
|
'yolov5s.tflite') # TensorFlow Lite
|
||||||
|
'yolov5s_edgetpu.tflite') # TensorFlow Edge TPU
|
||||||
|
'yolov5s_paddle_model') # PaddlePaddle
|
||||||
|
|
||||||
|
# Images
|
||||||
|
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
|
||||||
|
|
||||||
|
# Inference
|
||||||
|
results = model(img)
|
||||||
|
|
||||||
|
# Results
|
||||||
|
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
|
||||||
|
```
|
||||||
|
|
||||||
|
## OpenCV DNN inference
|
||||||
|
|
||||||
|
OpenCV inference with ONNX models:
|
||||||
|
```bash
|
||||||
|
python export.py --weights yolov5s.pt --include onnx
|
||||||
|
|
||||||
|
python detect.py --weights yolov5s.onnx --dnn # detect
|
||||||
|
python val.py --weights yolov5s.onnx --dnn # validate
|
||||||
|
```
|
||||||
|
|
||||||
|
## C++ Inference
|
||||||
|
|
||||||
|
YOLOv5 OpenCV DNN C++ inference on exported ONNX model examples:
|
||||||
|
|
||||||
|
- [https://github.com/Hexmagic/ONNX-yolov5/blob/master/src/test.cpp](https://github.com/Hexmagic/ONNX-yolov5/blob/master/src/test.cpp)
|
||||||
|
- [https://github.com/doleron/yolov5-opencv-cpp-python](https://github.com/doleron/yolov5-opencv-cpp-python)
|
||||||
|
|
||||||
|
YOLOv5 OpenVINO C++ inference examples:
|
||||||
|
|
||||||
|
- [https://github.com/dacquaviva/yolov5-openvino-cpp-python](https://github.com/dacquaviva/yolov5-openvino-cpp-python)
|
||||||
|
- [https://github.com/UNeedCryDear/yolov5-seg-opencv-dnn-cpp](https://github.com/UNeedCryDear/yolov5-seg-opencv-dnn-cpp)
|
||||||
|
|
||||||
|
## TensorFlow.js Web Browser Inference
|
||||||
|
|
||||||
|
- [https://aukerul-shuvo.github.io/YOLOv5_TensorFlow-JS/](https://aukerul-shuvo.github.io/YOLOv5_TensorFlow-JS/)
|
||||||
|
|
||||||
|
## Environments
|
||||||
|
|
||||||
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||||
|
|
||||||
|
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||||
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||||
|
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
|
||||||
|
## Status
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
|
||||||
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||||
161
docs/yolov5/hyp_evolution.md
Normal file
@@ -0,0 +1,161 @@
|
|||||||
|
📚 This guide explains **hyperparameter evolution** for YOLOv5 🚀. Hyperparameter evolution is a method of [Hyperparameter Optimization](https://en.wikipedia.org/wiki/Hyperparameter_optimization) using a [Genetic Algorithm](https://en.wikipedia.org/wiki/Genetic_algorithm) (GA) for optimization. UPDATED 25 September 2022.
|
||||||
|
|
||||||
|
Hyperparameters in ML control various aspects of training, and finding optimal values for them can be a challenge. Traditional methods like grid searches can quickly become intractable due to 1) the high dimensional search space 2) unknown correlations among the dimensions, and 3) expensive nature of evaluating the fitness at each point, making GA a suitable candidate for hyperparameter searches.
|
||||||
|
|
||||||
|
|
||||||
|
## Before You Start
|
||||||
|
|
||||||
|
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ultralytics/yolov5 # clone
|
||||||
|
cd yolov5
|
||||||
|
pip install -r requirements.txt # install
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## 1. Initialize Hyperparameters
|
||||||
|
|
||||||
|
YOLOv5 has about 30 hyperparameters used for various training settings. These are defined in `*.yaml` files in the `/data/hyps` directory. Better initial guesses will produce better final results, so it is important to initialize these values properly before evolving. If in doubt, simply use the default values, which are optimized for YOLOv5 COCO training from scratch.
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
# Hyperparameters for low-augmentation COCO training from scratch
|
||||||
|
# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
|
||||||
|
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
|
||||||
|
|
||||||
|
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
|
||||||
|
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
|
||||||
|
momentum: 0.937 # SGD momentum/Adam beta1
|
||||||
|
weight_decay: 0.0005 # optimizer weight decay 5e-4
|
||||||
|
warmup_epochs: 3.0 # warmup epochs (fractions ok)
|
||||||
|
warmup_momentum: 0.8 # warmup initial momentum
|
||||||
|
warmup_bias_lr: 0.1 # warmup initial bias lr
|
||||||
|
box: 0.05 # box loss gain
|
||||||
|
cls: 0.5 # cls loss gain
|
||||||
|
cls_pw: 1.0 # cls BCELoss positive_weight
|
||||||
|
obj: 1.0 # obj loss gain (scale with pixels)
|
||||||
|
obj_pw: 1.0 # obj BCELoss positive_weight
|
||||||
|
iou_t: 0.20 # IoU training threshold
|
||||||
|
anchor_t: 4.0 # anchor-multiple threshold
|
||||||
|
# anchors: 3 # anchors per output layer (0 to ignore)
|
||||||
|
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
|
||||||
|
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
|
||||||
|
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
|
||||||
|
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
|
||||||
|
degrees: 0.0 # image rotation (+/- deg)
|
||||||
|
translate: 0.1 # image translation (+/- fraction)
|
||||||
|
scale: 0.5 # image scale (+/- gain)
|
||||||
|
shear: 0.0 # image shear (+/- deg)
|
||||||
|
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
|
||||||
|
flipud: 0.0 # image flip up-down (probability)
|
||||||
|
fliplr: 0.5 # image flip left-right (probability)
|
||||||
|
mosaic: 1.0 # image mosaic (probability)
|
||||||
|
mixup: 0.0 # image mixup (probability)
|
||||||
|
copy_paste: 0.0 # segment copy-paste (probability)
|
||||||
|
```
|
||||||
|
|
||||||
|
## 2. Define Fitness
|
||||||
|
|
||||||
|
Fitness is the value we seek to maximize. In YOLOv5 we define a default fitness function as a weighted combination of metrics: `mAP@0.5` contributes 10% of the weight and `mAP@0.5:0.95` contributes the remaining 90%, with [Precision `P` and Recall `R`](https://en.wikipedia.org/wiki/Precision_and_recall) absent. You may adjust these as you see fit or use the default fitness definition in utils/metrics.py (recommended).
|
||||||
|
|
||||||
|
```python
|
||||||
|
def fitness(x):
|
||||||
|
# Model fitness as a weighted combination of metrics
|
||||||
|
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
|
||||||
|
return (x[:, :4] * w).sum(1)
|
||||||
|
```
|
||||||
|
|
||||||
|
## 3. Evolve
|
||||||
|
|
||||||
|
Evolution is performed about a base scenario which we seek to improve upon. The base scenario in this example is finetuning COCO128 for 10 epochs using pretrained YOLOv5s. The base scenario training command is:
|
||||||
|
```bash
|
||||||
|
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache
|
||||||
|
```
|
||||||
|
To evolve hyperparameters **specific to this scenario**, starting from our initial values defined in **Section 1.**, and maximizing the fitness defined in **Section 2.**, append `--evolve`:
|
||||||
|
```bash
|
||||||
|
# Single-GPU
|
||||||
|
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
|
||||||
|
|
||||||
|
# Multi-GPU
|
||||||
|
for i in 0 1 2 3 4 5 6 7; do
|
||||||
|
sleep $(expr 30 \* $i) && # 30-second delay (optional)
|
||||||
|
echo 'Starting GPU '$i'...' &&
|
||||||
|
nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --device $i --evolve > evolve_gpu_$i.log &
|
||||||
|
done
|
||||||
|
|
||||||
|
# Multi-GPU bash-while (not recommended)
|
||||||
|
for i in 0 1 2 3 4 5 6 7; do
|
||||||
|
sleep $(expr 30 \* $i) && # 30-second delay (optional)
|
||||||
|
echo 'Starting GPU '$i'...' &&
|
||||||
|
"$(while true; do nohup python train.py... --device $i --evolve 1 > evolve_gpu_$i.log; done)" &
|
||||||
|
done
|
||||||
|
```
|
||||||
|
|
||||||
|
The default evolution settings will run the base scenario 300 times, i.e. for 300 generations. You can modify generations via the `--evolve` argument, i.e. `python train.py --evolve 1000`.
|
||||||
|
https://github.com/ultralytics/yolov5/blob/6a3ee7cf03efb17fbffde0e68b1a854e80fe3213/train.py#L608
|
||||||
|
|
||||||
|
The main genetic operators are **crossover** and **mutation**. In this work mutation is used, with an 80% probability and a 0.04 variance to create new offspring based on a combination of the best parents from all previous generations. Results are logged to `runs/evolve/exp/evolve.csv`, and the highest fitness offspring is saved every generation as `runs/evolve/hyp_evolved.yaml`:
|
||||||
|
```yaml
|
||||||
|
# YOLOv5 Hyperparameter Evolution Results
|
||||||
|
# Best generation: 287
|
||||||
|
# Last generation: 300
|
||||||
|
# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
|
||||||
|
# 0.54634, 0.55625, 0.58201, 0.33665, 0.056451, 0.042892, 0.013441
|
||||||
|
|
||||||
|
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
|
||||||
|
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
|
||||||
|
momentum: 0.937 # SGD momentum/Adam beta1
|
||||||
|
weight_decay: 0.0005 # optimizer weight decay 5e-4
|
||||||
|
warmup_epochs: 3.0 # warmup epochs (fractions ok)
|
||||||
|
warmup_momentum: 0.8 # warmup initial momentum
|
||||||
|
warmup_bias_lr: 0.1 # warmup initial bias lr
|
||||||
|
box: 0.05 # box loss gain
|
||||||
|
cls: 0.5 # cls loss gain
|
||||||
|
cls_pw: 1.0 # cls BCELoss positive_weight
|
||||||
|
obj: 1.0 # obj loss gain (scale with pixels)
|
||||||
|
obj_pw: 1.0 # obj BCELoss positive_weight
|
||||||
|
iou_t: 0.20 # IoU training threshold
|
||||||
|
anchor_t: 4.0 # anchor-multiple threshold
|
||||||
|
# anchors: 3 # anchors per output layer (0 to ignore)
|
||||||
|
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
|
||||||
|
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
|
||||||
|
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
|
||||||
|
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
|
||||||
|
degrees: 0.0 # image rotation (+/- deg)
|
||||||
|
translate: 0.1 # image translation (+/- fraction)
|
||||||
|
scale: 0.5 # image scale (+/- gain)
|
||||||
|
shear: 0.0 # image shear (+/- deg)
|
||||||
|
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
|
||||||
|
flipud: 0.0 # image flip up-down (probability)
|
||||||
|
fliplr: 0.5 # image flip left-right (probability)
|
||||||
|
mosaic: 1.0 # image mosaic (probability)
|
||||||
|
mixup: 0.0 # image mixup (probability)
|
||||||
|
copy_paste: 0.0 # segment copy-paste (probability)
|
||||||
|
```
|
||||||
|
|
||||||
|
We recommend a minimum of 300 generations of evolution for best results. Note that **evolution is generally expensive and time-consuming**, as the base scenario is trained hundreds of times, possibly requiring hundreds or thousands of GPU hours.
|
||||||
|
|
||||||
|
|
||||||
|
## 4. Visualize
|
||||||
|
|
||||||
|
`evolve.csv` is plotted as `evolve.png` by `utils.plots.plot_evolve()` after evolution finishes with one subplot per hyperparameter showing fitness (y-axis) vs hyperparameter values (x-axis). Yellow indicates higher concentrations. Vertical distributions indicate that a parameter has been disabled and does not mutate. This is user selectable in the `meta` dictionary in train.py, and is useful for fixing parameters and preventing them from evolving.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Environments
|
||||||
|
|
||||||
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||||
|
|
||||||
|
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||||
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||||
|
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
|
||||||
|
## Status
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
|
||||||
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||||
87
docs/yolov5/index.md
Normal file
@@ -0,0 +1,87 @@
|
|||||||
|
# YOLOv5 Docs
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<p>
|
||||||
|
<a href="https://ultralytics.com/yolov5" target="_blank">
|
||||||
|
<img width="100%" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov5/v70/splash.png"></a>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
<a href="https://zenodo.org/badge/latestdoi/264818686"><img src="https://zenodo.org/badge/264818686.svg" alt="YOLOv5 Citation"></a>
|
||||||
|
<a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
<br>
|
||||||
|
<a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a>
|
||||||
|
<a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
||||||
|
<a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
<br>
|
||||||
|
<br>
|
||||||
|
|
||||||
|
Welcome to the Ultralytics YOLOv5 🚀 Docs! YOLOv5, or You Only Look Once version 5, is an Ultralytics object detection model designed to deliver fast and accurate real-time results.
|
||||||
|
<br><br>
|
||||||
|
This powerful deep learning framework is built on the PyTorch platform and has gained immense popularity due to its ease of use, high performance, and versatility. In this documentation, we will guide you through the installation process, explain the model's architecture, showcase various use-cases, and provide detailed tutorials to help you harness the full potential of YOLOv5 for your computer vision projects. Let's dive in!
|
||||||
|
|
||||||
|
</div>
|
||||||
|
|
||||||
|
## Tutorials
|
||||||
|
|
||||||
|
* [Train Custom Data](train_custom_data.md) 🚀 RECOMMENDED
|
||||||
|
* [Tips for Best Training Results](tips_for_best_training_results.md) ☘️
|
||||||
|
* [Multi-GPU Training](multi_gpu_training.md)
|
||||||
|
* [PyTorch Hub](pytorch_hub.md) 🌟 NEW
|
||||||
|
* [TFLite, ONNX, CoreML, TensorRT Export](export.md) 🚀
|
||||||
|
* [NVIDIA Jetson platform Deployment](jetson_nano.md) 🌟 NEW
|
||||||
|
* [Test-Time Augmentation (TTA)](tta.md)
|
||||||
|
* [Model Ensembling](ensemble.md)
|
||||||
|
* [Model Pruning/Sparsity](pruning_sparsity.md)
|
||||||
|
* [Hyperparameter Evolution](hyp_evolution.md)
|
||||||
|
* [Transfer Learning with Frozen Layers](transfer_learn_frozen.md)
|
||||||
|
* [Architecture Summary](architecture.md) 🌟 NEW
|
||||||
|
* [Roboflow for Datasets, Labeling, and Active Learning](roboflow.md)
|
||||||
|
* [ClearML Logging](clearml.md) 🌟 NEW
|
||||||
|
* [YOLOv5 with Neural Magic's Deepsparse](neural_magic.md) 🌟 NEW
|
||||||
|
* [Comet Logging](comet.md) 🌟 NEW
|
||||||
|
|
||||||
|
## Environments
|
||||||
|
|
||||||
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies
|
||||||
|
including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/)
|
||||||
|
and [PyTorch](https://pytorch.org/) preinstalled):
|
||||||
|
|
||||||
|
- **Notebooks** with free
|
||||||
|
GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
- **Google Cloud** Deep Learning VM.
|
||||||
|
See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||||
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||||
|
- **Docker Image**.
|
||||||
|
See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
## Status
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
|
||||||
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous
|
||||||
|
Integration (CI) tests are currently passing. CI tests verify correct operation of
|
||||||
|
YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py)
|
||||||
|
and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24
|
||||||
|
hours and on every commit.
|
||||||
|
|
||||||
|
<br>
|
||||||
|
<div align="center">
|
||||||
|
<a href="https://github.com/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="3%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="" />
|
||||||
|
<a href="https://www.linkedin.com/company/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="3%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="" />
|
||||||
|
<a href="https://twitter.com/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="3%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="" />
|
||||||
|
<a href="https://youtube.com/ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="3%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="" />
|
||||||
|
<a href="https://www.tiktok.com/@ultralytics" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="3%" alt="" /></a>
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="" />
|
||||||
|
<a href="https://www.instagram.com/ultralytics/" style="text-decoration:none;">
|
||||||
|
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="3%" alt="" /></a>
|
||||||
|
</div>
|
||||||
316
docs/yolov5/jetson_nano.md
Normal file
@@ -0,0 +1,316 @@
|
|||||||
|
# Deploy on NVIDIA Jetson using TensorRT and DeepStream SDK
|
||||||
|
|
||||||
|
📚 This guide explains how to deploy a trained model into NVIDIA Jetson Platform and perform inference using TensorRT and DeepStream SDK. Here we use TensorRT to maximize the inference performance on the Jetson platform.
|
||||||
|
UPDATED 18 November 2022.
|
||||||
|
|
||||||
|
## Hardware Verification
|
||||||
|
|
||||||
|
We have tested and verified this guide on the following Jetson devices
|
||||||
|
|
||||||
|
- [Seeed reComputer J1010 built with Jetson Nano module](https://www.seeedstudio.com/Jetson-10-1-A0-p-5336.html)
|
||||||
|
- [Seeed reComputer J2021 built with Jetson Xavier NX module](https://www.seeedstudio.com/reComputer-J2021-p-5438.html)
|
||||||
|
|
||||||
|
## Before You Start
|
||||||
|
|
||||||
|
Make sure you have properly installed **JetPack SDK** with all the **SDK Components** and **DeepStream SDK** on the Jetson device as this includes CUDA, TensorRT and DeepStream SDK which are needed for this guide.
|
||||||
|
|
||||||
|
JetPack SDK provides a full development environment for hardware-accelerated AI-at-the-edge development. All Jetson modules and developer kits are supported by JetPack SDK.
|
||||||
|
|
||||||
|
There are two major installation methods including,
|
||||||
|
|
||||||
|
1. SD Card Image Method
|
||||||
|
2. NVIDIA SDK Manager Method
|
||||||
|
|
||||||
|
You can find a very detailed installation guide from NVIDIA [official website](https://developer.nvidia.com/jetpack-sdk-461). You can also find guides corresponding to the above-mentioned [reComputer J1010](https://wiki.seeedstudio.com/reComputer_J1010_J101_Flash_Jetpack) and [reComputer J2021](https://wiki.seeedstudio.com/reComputer_J2021_J202_Flash_Jetpack).
|
||||||
|
|
||||||
|
|
||||||
|
## Install Necessary Packages
|
||||||
|
|
||||||
|
- **Step 1.** Access the terminal of Jetson device, install pip and upgrade it
|
||||||
|
|
||||||
|
```sh
|
||||||
|
sudo apt update
|
||||||
|
sudo apt install -y python3-pip
|
||||||
|
pip3 install --upgrade pip
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 2.** Clone the following repo
|
||||||
|
|
||||||
|
```sh
|
||||||
|
git clone https://github.com/ultralytics/yolov5
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 3.** Open **requirements.txt**
|
||||||
|
|
||||||
|
```sh
|
||||||
|
cd yolov5
|
||||||
|
vi requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 5.** Edit the following lines. Here you need to press **i** first to enter editing mode. Press **ESC**, then type **:wq** to save and quit
|
||||||
|
|
||||||
|
```sh
|
||||||
|
# torch>=1.7.0
|
||||||
|
# torchvision>=0.8.1
|
||||||
|
```
|
||||||
|
|
||||||
|
**Note:** torch and torchvision are excluded for now because they will be installed later.
|
||||||
|
|
||||||
|
- **Step 6.** install the below dependency
|
||||||
|
|
||||||
|
```sh
|
||||||
|
sudo apt install -y libfreetype6-dev
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 7.** Install the necessary packages
|
||||||
|
|
||||||
|
```sh
|
||||||
|
pip3 install -r requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
## Install PyTorch and Torchvision
|
||||||
|
|
||||||
|
We cannot install PyTorch and Torchvision from pip because they are not compatible to run on Jetson platform which is based on **ARM aarch64 architecture**. Therefore, we need to manually install pre-built PyTorch pip wheel and compile/ install Torchvision from source.
|
||||||
|
|
||||||
|
Visit [this page](https://forums.developer.nvidia.com/t/pytorch-for-jetson) to access all the PyTorch and Torchvision links.
|
||||||
|
|
||||||
|
Here are some of the versions supported by JetPack 4.6 and above.
|
||||||
|
|
||||||
|
**PyTorch v1.10.0**
|
||||||
|
|
||||||
|
Supported by JetPack 4.4 (L4T R32.4.3) / JetPack 4.4.1 (L4T R32.4.4) / JetPack 4.5 (L4T R32.5.0) / JetPack 4.5.1 (L4T R32.5.1) / JetPack 4.6 (L4T R32.6.1) with Python 3.6
|
||||||
|
|
||||||
|
**file_name:** torch-1.10.0-cp36-cp36m-linux_aarch64.whl
|
||||||
|
**URL:** [https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl](https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl)
|
||||||
|
|
||||||
|
**PyTorch v1.12.0**
|
||||||
|
|
||||||
|
Supported by JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) with Python 3.8
|
||||||
|
|
||||||
|
**file_name:** torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
|
||||||
|
**URL:** [https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl](https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl)
|
||||||
|
|
||||||
|
- **Step 1.** Install torch according to your JetPack version in the following format
|
||||||
|
|
||||||
|
```sh
|
||||||
|
wget <URL> -O <file_name>
|
||||||
|
pip3 install <file_name>
|
||||||
|
```
|
||||||
|
|
||||||
|
For example, here we are running **JP4.6.1**, and therefore we choose **PyTorch v1.10.0**
|
||||||
|
|
||||||
|
```sh
|
||||||
|
cd ~
|
||||||
|
sudo apt-get install -y libopenblas-base libopenmpi-dev
|
||||||
|
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
|
||||||
|
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 2.** Install torchvision depending on the version of PyTorch that you have installed. For example, we chose **PyTorch v1.10.0**, which means, we need to choose **Torchvision v0.11.1**
|
||||||
|
|
||||||
|
```sh
|
||||||
|
sudo apt install -y libjpeg-dev zlib1g-dev
|
||||||
|
git clone --branch v0.11.1 https://github.com/pytorch/vision torchvision
|
||||||
|
cd torchvision
|
||||||
|
sudo python3 setup.py install
|
||||||
|
```
|
||||||
|
|
||||||
|
Here a list of the corresponding torchvision version that you need to install according to the PyTorch version:
|
||||||
|
|
||||||
|
- PyTorch v1.10 - torchvision v0.11.1
|
||||||
|
- PyTorch v1.12 - torchvision v0.13.0
|
||||||
|
|
||||||
|
## DeepStream Configuration for YOLOv5
|
||||||
|
|
||||||
|
- **Step 1.** Clone the following repo
|
||||||
|
|
||||||
|
```sh
|
||||||
|
cd ~
|
||||||
|
git clone https://github.com/marcoslucianops/DeepStream-Yolo
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 2.** Copy **gen_wts_yoloV5.py** from **DeepStream-Yolo/utils** into **yolov5** directory
|
||||||
|
|
||||||
|
```sh
|
||||||
|
cp DeepStream-Yolo/utils/gen_wts_yoloV5.py yolov5
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 3.** Inside the yolov5 repo, download **pt file** from YOLOv5 releases (example for YOLOv5s 6.1)
|
||||||
|
|
||||||
|
```sh
|
||||||
|
cd yolov5
|
||||||
|
wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 4.** Generate the **cfg** and **wts** files
|
||||||
|
|
||||||
|
```sh
|
||||||
|
python3 gen_wts_yoloV5.py -w yolov5s.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
**Note**: To change the inference size (default: 640)
|
||||||
|
|
||||||
|
```sh
|
||||||
|
-s SIZE
|
||||||
|
--size SIZE
|
||||||
|
-s HEIGHT WIDTH
|
||||||
|
--size HEIGHT WIDTH
|
||||||
|
|
||||||
|
Example for 1280:
|
||||||
|
|
||||||
|
-s 1280
|
||||||
|
or
|
||||||
|
-s 1280 1280
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 5.** Copy the generated **cfg** and **wts** files into the **DeepStream-Yolo** folder
|
||||||
|
|
||||||
|
```sh
|
||||||
|
cp yolov5s.cfg ~/DeepStream-Yolo
|
||||||
|
cp yolov5s.wts ~/DeepStream-Yolo
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 6.** Open the **DeepStream-Yolo** folder and compile the library
|
||||||
|
|
||||||
|
```sh
|
||||||
|
cd ~/DeepStream-Yolo
|
||||||
|
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.1
|
||||||
|
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 7.** Edit the **config_infer_primary_yoloV5.txt** file according to your model
|
||||||
|
|
||||||
|
```sh
|
||||||
|
[property]
|
||||||
|
...
|
||||||
|
custom-network-config=yolov5s.cfg
|
||||||
|
model-file=yolov5s.wts
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 8.** Edit the **deepstream_app_config** file
|
||||||
|
|
||||||
|
```sh
|
||||||
|
...
|
||||||
|
[primary-gie]
|
||||||
|
...
|
||||||
|
config-file=config_infer_primary_yoloV5.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 9.** Change the video source in **deepstream_app_config** file. Here a default video file is loaded as you can see below
|
||||||
|
|
||||||
|
```sh
|
||||||
|
...
|
||||||
|
[source0]
|
||||||
|
...
|
||||||
|
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
|
||||||
|
```
|
||||||
|
|
||||||
|
## Run the Inference
|
||||||
|
|
||||||
|
```sh
|
||||||
|
deepstream-app -c deepstream_app_config.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
<div align=center><img width=1000 src="https://files.seeedstudio.com/wiki/YOLOV5/FP32-yolov5s.gif"/></div>
|
||||||
|
|
||||||
|
The above result is running on **Jetson Xavier NX** with **FP32** and **YOLOv5s 640x640**. We can see that the **FPS** is around **30**.
|
||||||
|
|
||||||
|
## INT8 Calibration
|
||||||
|
|
||||||
|
If you want to use INT8 precision for inference, you need to follow the steps below
|
||||||
|
|
||||||
|
- **Step 1.** Install OpenCV
|
||||||
|
|
||||||
|
```sh
|
||||||
|
sudo apt-get install libopencv-dev
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 2.** Compile/recompile the **nvdsinfer_custom_impl_Yolo** library with OpenCV support
|
||||||
|
|
||||||
|
```sh
|
||||||
|
cd ~/DeepStream-Yolo
|
||||||
|
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.1
|
||||||
|
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 3.** For COCO dataset, download the [val2017](https://drive.google.com/file/d/1gbvfn7mcsGDRZ_luJwtITL-ru2kK99aK/view?usp=sharing), extract, and move to **DeepStream-Yolo** folder
|
||||||
|
|
||||||
|
- **Step 4.** Make a new directory for calibration images
|
||||||
|
|
||||||
|
```sh
|
||||||
|
mkdir calibration
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 5.** Run the following to select 1000 random images from COCO dataset to run calibration
|
||||||
|
|
||||||
|
```sh
|
||||||
|
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
|
||||||
|
cp ${jpg} calibration/; \
|
||||||
|
done
|
||||||
|
```
|
||||||
|
|
||||||
|
**Note:** NVIDIA recommends at least 500 images to get a good accuracy. On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). Higher INT8_CALIB_BATCH_SIZE values will result in more accuracy and faster calibration speed. Set it according to you GPU memory. You can set it from **head -1000**. For example, for 2000 images, **head -2000**. This process can take a long time.
|
||||||
|
|
||||||
|
- **Step 6.** Create the **calibration.txt** file with all selected images
|
||||||
|
|
||||||
|
```sh
|
||||||
|
realpath calibration/*jpg > calibration.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 7.** Set environment variables
|
||||||
|
|
||||||
|
```sh
|
||||||
|
export INT8_CALIB_IMG_PATH=calibration.txt
|
||||||
|
export INT8_CALIB_BATCH_SIZE=1
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 8.** Update the **config_infer_primary_yoloV5.txt** file
|
||||||
|
|
||||||
|
From
|
||||||
|
|
||||||
|
```sh
|
||||||
|
...
|
||||||
|
model-engine-file=model_b1_gpu0_fp32.engine
|
||||||
|
#int8-calib-file=calib.table
|
||||||
|
...
|
||||||
|
network-mode=0
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
To
|
||||||
|
|
||||||
|
```sh
|
||||||
|
...
|
||||||
|
model-engine-file=model_b1_gpu0_int8.engine
|
||||||
|
int8-calib-file=calib.table
|
||||||
|
...
|
||||||
|
network-mode=1
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
- **Step 9.** Run the inference
|
||||||
|
|
||||||
|
```sh
|
||||||
|
deepstream-app -c deepstream_app_config.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
<div align=center><img width=1000 src="https://files.seeedstudio.com/wiki/YOLOV5/INT8-yolov5s.gif"/></div>
|
||||||
|
|
||||||
|
The above result is running on **Jetson Xavier NX** with **INT8** and **YOLOv5s 640x640**. We can see that the **FPS** is around **60**.
|
||||||
|
|
||||||
|
## Benchmark results
|
||||||
|
|
||||||
|
The following table summarizes how different models perform on **Jetson Xavier NX**.
|
||||||
|
|
||||||
|
| Model Name | Precision | Inference Size | Inference Time (ms) | FPS |
|
||||||
|
|------------|-----------|----------------|---------------------|-----|
|
||||||
|
| YOLOv5s | FP32 | 320x320 | 16.66 | 60 |
|
||||||
|
| | FP32 | 640x640 | 33.33 | 30 |
|
||||||
|
| | INT8 | 640x640 | 16.66 | 60 |
|
||||||
|
| YOLOv5n | FP32 | 640x640 | 16.66 | 60 |
|
||||||
|
|
||||||
|
|
||||||
|
### Additional
|
||||||
|
|
||||||
|
This tutorial is written by our friends at seeed @lakshanthad and Elaine
|
||||||
186
docs/yolov5/multi_gpu_training.md
Normal file
@@ -0,0 +1,186 @@
|
|||||||
|
📚 This guide explains how to properly use **multiple** GPUs to train a dataset with YOLOv5 🚀 on single or multiple machine(s).
|
||||||
|
UPDATED 25 December 2022.
|
||||||
|
|
||||||
|
## Before You Start
|
||||||
|
|
||||||
|
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ultralytics/yolov5 # clone
|
||||||
|
cd yolov5
|
||||||
|
pip install -r requirements.txt # install
|
||||||
|
```
|
||||||
|
|
||||||
|
💡 ProTip! **Docker Image** is recommended for all Multi-GPU trainings. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
💡 ProTip! `torch.distributed.run` replaces `torch.distributed.launch` in **PyTorch>=1.9**. See [docs](https://pytorch.org/docs/stable/distributed.html) for details.
|
||||||
|
|
||||||
|
## Training
|
||||||
|
|
||||||
|
Select a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models. We will train this model with Multi-GPU on the [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) dataset.
|
||||||
|
|
||||||
|
<p align="center"><img width="700" alt="YOLOv5 Models" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/model_comparison.png"></p>
|
||||||
|
|
||||||
|
|
||||||
|
### Single GPU
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python train.py --batch 64 --data coco.yaml --weights yolov5s.pt --device 0
|
||||||
|
```
|
||||||
|
|
||||||
|
### Multi-GPU [DataParallel](https://pytorch.org/docs/stable/nn.html#torch.nn.DataParallel) Mode (⚠️ not recommended)
|
||||||
|
|
||||||
|
You can increase the `device` to use Multiple GPUs in DataParallel mode.
|
||||||
|
```bash
|
||||||
|
python train.py --batch 64 --data coco.yaml --weights yolov5s.pt --device 0,1
|
||||||
|
```
|
||||||
|
|
||||||
|
This method is slow and barely speeds up training compared to using just 1 GPU.
|
||||||
|
|
||||||
|
### Multi-GPU [DistributedDataParallel](https://pytorch.org/docs/stable/nn.html#torch.nn.parallel.DistributedDataParallel) Mode (✅ recommended)
|
||||||
|
|
||||||
|
You will have to pass `python -m torch.distributed.run --nproc_per_node`, followed by the usual arguments.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data coco.yaml --weights yolov5s.pt --device 0,1
|
||||||
|
```
|
||||||
|
|
||||||
|
`--nproc_per_node` specifies how many GPUs you would like to use. In the example above, it is 2.
|
||||||
|
`--batch ` is the total batch-size. It will be divided evenly to each GPU. In the example above, it is 64/2=32 per GPU.
|
||||||
|
|
||||||
|
The code above will use GPUs `0... (N-1)`.
|
||||||
|
|
||||||
|
<details markdown>
|
||||||
|
<summary>Use specific GPUs (click to expand)</summary>
|
||||||
|
|
||||||
|
You can do so by simply passing `--device` followed by your specific GPUs. For example, in the code below, we will use GPUs `2,3`.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --device 2,3
|
||||||
|
```
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details markdown>
|
||||||
|
<summary>Use SyncBatchNorm (click to expand)</summary>
|
||||||
|
|
||||||
|
[SyncBatchNorm](https://pytorch.org/docs/master/generated/torch.nn.SyncBatchNorm.html) could increase accuracy for multiple gpu training, however, it will slow down training by a significant factor. It is **only** available for Multiple GPU DistributedDataParallel training.
|
||||||
|
|
||||||
|
It is best used when the batch-size on **each** GPU is small (<= 8).
|
||||||
|
|
||||||
|
To use SyncBatchNorm, simple pass `--sync-bn` to the command like below,
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --sync-bn
|
||||||
|
```
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details markdown>
|
||||||
|
<summary>Use Multiple machines (click to expand)</summary>
|
||||||
|
|
||||||
|
This is **only** available for Multiple GPU DistributedDataParallel training.
|
||||||
|
|
||||||
|
Before we continue, make sure the files on all machines are the same, dataset, codebase, etc. Afterwards, make sure the machines can communicate to each other.
|
||||||
|
|
||||||
|
You will have to choose a master machine(the machine that the others will talk to). Note down its address(`master_addr`) and choose a port(`master_port`). I will use `master_addr = 192.168.1.1` and `master_port = 1234` for the example below.
|
||||||
|
|
||||||
|
To use it, you can do as the following,
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# On master machine 0
|
||||||
|
python -m torch.distributed.run --nproc_per_node G --nnodes N --node_rank 0 --master_addr "192.168.1.1" --master_port 1234 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights ''
|
||||||
|
```
|
||||||
|
```bash
|
||||||
|
# On machine R
|
||||||
|
python -m torch.distributed.run --nproc_per_node G --nnodes N --node_rank R --master_addr "192.168.1.1" --master_port 1234 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights ''
|
||||||
|
```
|
||||||
|
where `G` is number of GPU per machine, `N` is the number of machines, and `R` is the machine number from `0...(N-1)`.
|
||||||
|
Let's say I have two machines with two GPUs each, it would be `G = 2` , `N = 2`, and `R = 1` for the above.
|
||||||
|
|
||||||
|
Training will not start until <b>all </b> `N` machines are connected. Output will only be shown on master machine!
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
|
||||||
|
### Notes
|
||||||
|
|
||||||
|
- Windows support is untested, Linux is recommended.
|
||||||
|
- `--batch ` must be a multiple of the number of GPUs.
|
||||||
|
- GPU 0 will take slightly more memory than the other GPUs as it maintains EMA and is responsible for checkpointing etc.
|
||||||
|
- If you get `RuntimeError: Address already in use`, it could be because you are running multiple trainings at a time. To fix this, simply use a different port number by adding `--master_port` like below,
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python -m torch.distributed.run --master_port 1234 --nproc_per_node 2 ...
|
||||||
|
```
|
||||||
|
|
||||||
|
## Results
|
||||||
|
|
||||||
|
DDP profiling results on an [AWS EC2 P4d instance](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart) with 8x A100 SXM4-40GB for YOLOv5l for 1 COCO epoch.
|
||||||
|
|
||||||
|
<details markdown>
|
||||||
|
<summary>Profiling code</summary>
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# prepare
|
||||||
|
t=ultralytics/yolov5:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v "$(pwd)"/coco:/usr/src/coco $t
|
||||||
|
pip3 install torch==1.9.0+cu111 torchvision==0.10.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
|
||||||
|
cd .. && rm -rf app && git clone https://github.com/ultralytics/yolov5 -b master app && cd app
|
||||||
|
cp data/coco.yaml data/coco_profile.yaml
|
||||||
|
|
||||||
|
# profile
|
||||||
|
python train.py --batch-size 16 --data coco_profile.yaml --weights yolov5l.pt --epochs 1 --device 0
|
||||||
|
python -m torch.distributed.run --nproc_per_node 2 train.py --batch-size 32 --data coco_profile.yaml --weights yolov5l.pt --epochs 1 --device 0,1
|
||||||
|
python -m torch.distributed.run --nproc_per_node 4 train.py --batch-size 64 --data coco_profile.yaml --weights yolov5l.pt --epochs 1 --device 0,1,2,3
|
||||||
|
python -m torch.distributed.run --nproc_per_node 8 train.py --batch-size 128 --data coco_profile.yaml --weights yolov5l.pt --epochs 1 --device 0,1,2,3,4,5,6,7
|
||||||
|
```
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
| GPUs<br>A100 | batch-size | CUDA_mem<br><sup>device0 (G) | COCO<br><sup>train | COCO<br><sup>val |
|
||||||
|
|--------------|------------|------------------------------|--------------------|------------------|
|
||||||
|
| 1x | 16 | 26GB | 20:39 | 0:55 |
|
||||||
|
| 2x | 32 | 26GB | 11:43 | 0:57 |
|
||||||
|
| 4x | 64 | 26GB | 5:57 | 0:55 |
|
||||||
|
| 8x | 128 | 26GB | 3:09 | 0:57 |
|
||||||
|
|
||||||
|
## FAQ
|
||||||
|
|
||||||
|
If an error occurs, please read the checklist below first! (It could save your time)
|
||||||
|
|
||||||
|
<details markdown>
|
||||||
|
<summary>Checklist (click to expand) </summary>
|
||||||
|
|
||||||
|
<ul>
|
||||||
|
<li>Have you properly read this post? </li>
|
||||||
|
<li>Have you tried to reclone the codebase? The code changes <b>daily</b>.</li>
|
||||||
|
<li>Have you tried to search for your error? Someone may have already encountered it in this repo or in another and have the solution. </li>
|
||||||
|
<li>Have you installed all the requirements listed on top (including the correct Python and Pytorch versions)? </li>
|
||||||
|
<li>Have you tried in other environments listed in the "Environments" section below? </li>
|
||||||
|
<li>Have you tried with another dataset like coco128 or coco2017? It will make it easier to find the root cause. </li>
|
||||||
|
</ul>
|
||||||
|
|
||||||
|
If you went through all the above, feel free to raise an Issue by giving as much detail as possible following the template.
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
|
||||||
|
## Environments
|
||||||
|
|
||||||
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||||
|
|
||||||
|
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||||
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||||
|
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
|
||||||
|
## Status
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
|
||||||
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||||
|
|
||||||
|
|
||||||
|
## Credits
|
||||||
|
|
||||||
|
I would like to thank @MagicFrogSJTU, who did all the heavy lifting, and @glenn-jocher for guiding us along the way.
|
||||||
260
docs/yolov5/neural_magic.md
Normal file
@@ -0,0 +1,260 @@
|
|||||||
|
<!--
|
||||||
|
Copyright (c) 2021 - present / Neuralmagic, Inc. All Rights Reserved.
|
||||||
|
|
||||||
|
Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
you may not use this file except in compliance with the License.
|
||||||
|
You may obtain a copy of the License at
|
||||||
|
|
||||||
|
http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
Unless required by applicable law or agreed to in writing,
|
||||||
|
software distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
See the License for the specific language governing permissions and
|
||||||
|
limitations under the License.
|
||||||
|
-->
|
||||||
|
|
||||||
|
Welcome to software-delivered AI.
|
||||||
|
|
||||||
|
This guide explains how to deploy YOLOv5 with Neural Magic's DeepSparse.
|
||||||
|
|
||||||
|
DeepSparse is an inference runtime with exceptional performance on CPUs. For instance, compared to the ONNX Runtime baseline, DeepSparse offers a 5.8x speed-up for YOLOv5s, running on the same machine!
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img width="60%" src="https://github.com/neuralmagic/deepsparse/raw/main/examples/ultralytics-yolo/ultralytics-readmes/performance-chart-5.8x.png">
|
||||||
|
</p>
|
||||||
|
|
||||||
|
For the first time, your deep learning workloads can meet the performance demands of production without the complexity and costs of hardware accelerators.
|
||||||
|
Put simply, DeepSparse gives you the performance of GPUs and the simplicity of software:
|
||||||
|
- **Flexible Deployments**: Run consistently across cloud, data center, and edge with any hardware provider from Intel to AMD to ARM
|
||||||
|
- **Infinite Scalability**: Scale vertically to 100s of cores, out with standard Kubernetes, or fully-abstracted with Serverless
|
||||||
|
- **Easy Integration**: Clean APIs for integrating your model into an application and monitoring it in production
|
||||||
|
|
||||||
|
**[Start your 90 day Free Trial](https://neuralmagic.com/deepsparse-free-trial/?utm_campaign=free_trial&utm_source=ultralytics_github).**
|
||||||
|
|
||||||
|
### How Does DeepSparse Achieve GPU-Class Performance?
|
||||||
|
|
||||||
|
DeepSparse takes advantage of model sparsity to gain its performance speedup.
|
||||||
|
|
||||||
|
Sparsification through pruning and quantization is a broadly studied technique, allowing order-of-magnitude reductions in the size and compute needed to
|
||||||
|
execute a network, while maintaining high accuracy. DeepSparse is sparsity-aware, meaning it skips the zeroed out parameters, shrinking amount of compute
|
||||||
|
in a forward pass. Since the sparse computation is now memory bound, DeepSparse executes the network depth-wise, breaking the problem into Tensor Columns,
|
||||||
|
vertical stripes of computation that fit in cache.
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img width="60%" src="https://github.com/neuralmagic/deepsparse/raw/main/examples/ultralytics-yolo/ultralytics-readmes/tensor-columns.png">
|
||||||
|
</p>
|
||||||
|
|
||||||
|
Sparse networks with compressed computation, executed depth-wise in cache, allows DeepSparse to deliver GPU-class performance on CPUs!
|
||||||
|
|
||||||
|
### How Do I Create A Sparse Version of YOLOv5 Trained on My Data?
|
||||||
|
|
||||||
|
Neural Magic's open-source model repository, SparseZoo, contains pre-sparsified checkpoints of each YOLOv5 model. Using SparseML, which is integrated with Ultralytics, you can fine-tune a sparse checkpoint onto your data with a single CLI command.
|
||||||
|
|
||||||
|
[Checkout Neural Magic's YOLOv5 documentation for more details](https://docs.neuralmagic.com/use-cases/object-detection/sparsifying).
|
||||||
|
|
||||||
|
## DeepSparse Usage
|
||||||
|
|
||||||
|
We will walk through an example benchmarking and deploying a sparse version of YOLOv5s with DeepSparse.
|
||||||
|
|
||||||
|
### Install DeepSparse
|
||||||
|
|
||||||
|
Run the following to install DeepSparse. We recommend you use a virtual environment with Python.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install deepsparse[server,yolo,onnxruntime]
|
||||||
|
```
|
||||||
|
|
||||||
|
### Collect an ONNX File
|
||||||
|
|
||||||
|
DeepSparse accepts a model in the ONNX format, passed either as:
|
||||||
|
- A SparseZoo stub which identifies an ONNX file in the SparseZoo
|
||||||
|
- A local path to an ONNX model in a filesystem
|
||||||
|
|
||||||
|
The examples below use the standard dense and pruned-quantized YOLOv5s checkpoints, identified by the following SparseZoo stubs:
|
||||||
|
```bash
|
||||||
|
zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none
|
||||||
|
zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none
|
||||||
|
```
|
||||||
|
|
||||||
|
### Deploy a Model
|
||||||
|
|
||||||
|
DeepSparse offers convenient APIs for integrating your model into an application.
|
||||||
|
|
||||||
|
To try the deployment examples below, pull down a sample image and save it as `basilica.jpg` with the following:
|
||||||
|
```bash
|
||||||
|
wget -O basilica.jpg https://raw.githubusercontent.com/neuralmagic/deepsparse/main/src/deepsparse/yolo/sample_images/basilica.jpg
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Python API
|
||||||
|
|
||||||
|
`Pipelines` wrap pre-processing and output post-processing around the runtime, providing a clean interface for adding DeepSparse to an application.
|
||||||
|
The DeepSparse-Ultralytics integration includes an out-of-the-box `Pipeline` that accepts raw images and outputs the bounding boxes.
|
||||||
|
|
||||||
|
Create a `Pipeline` and run inference:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from deepsparse import Pipeline
|
||||||
|
|
||||||
|
# list of images in local filesystem
|
||||||
|
images = ["basilica.jpg"]
|
||||||
|
|
||||||
|
# create Pipeline
|
||||||
|
model_stub = "zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none"
|
||||||
|
yolo_pipeline = Pipeline.create(
|
||||||
|
task="yolo",
|
||||||
|
model_path=model_stub,
|
||||||
|
)
|
||||||
|
|
||||||
|
# run inference on images, receive bounding boxes + classes
|
||||||
|
pipeline_outputs = yolo_pipeline(images=images, iou_thres=0.6, conf_thres=0.001)
|
||||||
|
print(pipeline_outputs)
|
||||||
|
```
|
||||||
|
|
||||||
|
If you are running in the cloud, you may get an error that open-cv cannot find `libGL.so.1`. Running the following on Ubuntu installs it:
|
||||||
|
|
||||||
|
```
|
||||||
|
apt-get install libgl1-mesa-glx
|
||||||
|
```
|
||||||
|
|
||||||
|
#### HTTP Server
|
||||||
|
|
||||||
|
DeepSparse Server runs on top of the popular FastAPI web framework and Uvicorn web server. With just a single CLI command, you can easily setup a model
|
||||||
|
service endpoint with DeepSparse. The Server supports any Pipeline from DeepSparse, including object detection with YOLOv5, enabling you to send raw
|
||||||
|
images to the endpoint and receive the bounding boxes.
|
||||||
|
|
||||||
|
Spin up the Server with the pruned-quantized YOLOv5s:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
deepsparse.server \
|
||||||
|
--task yolo \
|
||||||
|
--model_path zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none
|
||||||
|
```
|
||||||
|
|
||||||
|
An example request, using Python's `requests` package:
|
||||||
|
```python
|
||||||
|
import requests, json
|
||||||
|
|
||||||
|
# list of images for inference (local files on client side)
|
||||||
|
path = ['basilica.jpg']
|
||||||
|
files = [('request', open(img, 'rb')) for img in path]
|
||||||
|
|
||||||
|
# send request over HTTP to /predict/from_files endpoint
|
||||||
|
url = 'http://0.0.0.0:5543/predict/from_files'
|
||||||
|
resp = requests.post(url=url, files=files)
|
||||||
|
|
||||||
|
# response is returned in JSON
|
||||||
|
annotations = json.loads(resp.text) # dictionary of annotation results
|
||||||
|
bounding_boxes = annotations["boxes"]
|
||||||
|
labels = annotations["labels"]
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Annotate CLI
|
||||||
|
You can also use the annotate command to have the engine save an annotated photo on disk. Try --source 0 to annotate your live webcam feed!
|
||||||
|
```bash
|
||||||
|
deepsparse.object_detection.annotate --model_filepath zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none --source basilica.jpg
|
||||||
|
```
|
||||||
|
|
||||||
|
Running the above command will create an `annotation-results` folder and save the annotated image inside.
|
||||||
|
|
||||||
|
<p align = "center">
|
||||||
|
<img src="https://github.com/neuralmagic/deepsparse/raw/d31f02596ebff2ec62761d0bc9ca14c4663e8858/src/deepsparse/yolo/sample_images/basilica-annotated.jpg" alt="annotated" width="60%"/>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
## Benchmarking Performance
|
||||||
|
|
||||||
|
We will compare DeepSparse's throughput to ONNX Runtime's throughput on YOLOv5s, using DeepSparse's benchmarking script.
|
||||||
|
|
||||||
|
The benchmarks were run on an AWS `c6i.8xlarge` instance (16 cores).
|
||||||
|
|
||||||
|
### Batch 32 Performance Comparison
|
||||||
|
|
||||||
|
#### ONNX Runtime Baseline
|
||||||
|
|
||||||
|
At batch 32, ONNX Runtime achieves 42 images/sec with the standard dense YOLOv5s:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
deepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none -s sync -b 32 -nstreams 1 -e onnxruntime
|
||||||
|
|
||||||
|
> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none
|
||||||
|
> Batch Size: 32
|
||||||
|
> Scenario: sync
|
||||||
|
> Throughput (items/sec): 41.9025
|
||||||
|
```
|
||||||
|
|
||||||
|
#### DeepSparse Dense Performance
|
||||||
|
|
||||||
|
While DeepSparse offers its best performance with optimized sparse models, it also performs well with the standard dense YOLOv5s.
|
||||||
|
|
||||||
|
At batch 32, DeepSparse achieves 70 images/sec with the standard dense YOLOv5s, a **1.7x performance improvement over ORT**!
|
||||||
|
|
||||||
|
```bash
|
||||||
|
deepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none -s sync -b 32 -nstreams 1
|
||||||
|
|
||||||
|
> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none
|
||||||
|
> Batch Size: 32
|
||||||
|
> Scenario: sync
|
||||||
|
> Throughput (items/sec): 69.5546
|
||||||
|
```
|
||||||
|
#### DeepSparse Sparse Performance
|
||||||
|
|
||||||
|
When sparsity is applied to the model, DeepSparse's performance gains over ONNX Runtime is even stronger.
|
||||||
|
|
||||||
|
At batch 32, DeepSparse achieves 241 images/sec with the pruned-quantized YOLOv5s, a **5.8x performance improvement over ORT**!
|
||||||
|
|
||||||
|
```bash
|
||||||
|
deepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none -s sync -b 32 -nstreams 1
|
||||||
|
|
||||||
|
> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none
|
||||||
|
> Batch Size: 32
|
||||||
|
> Scenario: sync
|
||||||
|
> Throughput (items/sec): 241.2452
|
||||||
|
```
|
||||||
|
|
||||||
|
### Batch 1 Performance Comparison
|
||||||
|
|
||||||
|
DeepSparse is also able to gain a speed-up over ONNX Runtime for the latency-sensitive, batch 1 scenario.
|
||||||
|
|
||||||
|
#### ONNX Runtime Baseline
|
||||||
|
At batch 1, ONNX Runtime achieves 48 images/sec with the standard, dense YOLOv5s.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
deepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none -s sync -b 1 -nstreams 1 -e onnxruntime
|
||||||
|
|
||||||
|
> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none
|
||||||
|
> Batch Size: 1
|
||||||
|
> Scenario: sync
|
||||||
|
> Throughput (items/sec): 48.0921
|
||||||
|
```
|
||||||
|
|
||||||
|
#### DeepSparse Sparse Performance
|
||||||
|
|
||||||
|
At batch 1, DeepSparse achieves 135 items/sec with a pruned-quantized YOLOv5s, **a 2.8x performance gain over ONNX Runtime!**
|
||||||
|
|
||||||
|
```bash
|
||||||
|
deepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none -s sync -b 1 -nstreams 1
|
||||||
|
|
||||||
|
> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none
|
||||||
|
> Batch Size: 1
|
||||||
|
> Scenario: sync
|
||||||
|
> Throughput (items/sec): 134.9468
|
||||||
|
```
|
||||||
|
|
||||||
|
Since `c6i.8xlarge` instances have VNNI instructions, DeepSparse's throughput can be pushed further if weights are pruned in blocks of 4.
|
||||||
|
|
||||||
|
At batch 1, DeepSparse achieves 180 items/sec with a 4-block pruned-quantized YOLOv5s, a **3.7x performance gain over ONNX Runtime!**
|
||||||
|
|
||||||
|
```bash
|
||||||
|
deepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned35_quant-none-vnni -s sync -b 1 -nstreams 1
|
||||||
|
|
||||||
|
> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned35_quant-none-vnni
|
||||||
|
> Batch Size: 1
|
||||||
|
> Scenario: sync
|
||||||
|
> Throughput (items/sec): 179.7375
|
||||||
|
```
|
||||||
|
|
||||||
|
## Get Started With DeepSparse
|
||||||
|
|
||||||
|
**Research or Testing?** DeepSparse Community is free for research and testing. Get started with our [Documentation](https://docs.neuralmagic.com/).
|
||||||
|
|
||||||
|
**Want to Try DeepSparse Enterprise?** [Start your 90 day free trial](https://neuralmagic.com/deepsparse-free-trial/?utm_campaign=free_trial&utm_source=ultralytics_github).
|
||||||
103
docs/yolov5/pruning_sparsity.md
Normal file
@@ -0,0 +1,103 @@
|
|||||||
|
📚 This guide explains how to apply **pruning** to YOLOv5 🚀 models.
|
||||||
|
UPDATED 25 September 2022.
|
||||||
|
|
||||||
|
## Before You Start
|
||||||
|
|
||||||
|
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ultralytics/yolov5 # clone
|
||||||
|
cd yolov5
|
||||||
|
pip install -r requirements.txt # install
|
||||||
|
```
|
||||||
|
|
||||||
|
## Test Normally
|
||||||
|
|
||||||
|
Before pruning we want to establish a baseline performance to compare to. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
|
||||||
|
```bash
|
||||||
|
python val.py --weights yolov5x.pt --data coco.yaml --img 640 --half
|
||||||
|
```
|
||||||
|
|
||||||
|
Output:
|
||||||
|
```shell
|
||||||
|
val: data=/content/yolov5/data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False
|
||||||
|
YOLOv5 🚀 v6.0-224-g4c40933 torch 1.10.0+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)
|
||||||
|
|
||||||
|
Fusing layers...
|
||||||
|
Model Summary: 444 layers, 86705005 parameters, 0 gradients
|
||||||
|
val: Scanning '/content/datasets/coco/val2017.cache' images and labels... 4952 found, 48 missing, 0 empty, 0 corrupt: 100% 5000/5000 [00:00<?, ?it/s]
|
||||||
|
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [01:12<00:00, 2.16it/s]
|
||||||
|
all 5000 36335 0.732 0.628 0.683 0.496
|
||||||
|
Speed: 0.1ms pre-process, 5.2ms inference, 1.7ms NMS per image at shape (32, 3, 640, 640) # <--- base speed
|
||||||
|
|
||||||
|
Evaluating pycocotools mAP... saving runs/val/exp2/yolov5x_predictions.json...
|
||||||
|
...
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.507 # <--- base mAP
|
||||||
|
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.689
|
||||||
|
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.552
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.345
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.559
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.652
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.381
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.630
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.682
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.526
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.731
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.829
|
||||||
|
Results saved to runs/val/exp
|
||||||
|
```
|
||||||
|
|
||||||
|
## Test YOLOv5x on COCO (0.30 sparsity)
|
||||||
|
|
||||||
|
We repeat the above test with a pruned model by using the `torch_utils.prune()` command. We update `val.py` to prune YOLOv5x to 0.3 sparsity:
|
||||||
|
|
||||||
|
<img width="894" alt="Screenshot 2022-02-02 at 22 54 18" src="https://user-images.githubusercontent.com/26833433/152243799-b0ac2777-b1a8-47b1-801a-2e4c93c06ead.png">
|
||||||
|
|
||||||
|
30% pruned output:
|
||||||
|
```bash
|
||||||
|
val: data=/content/yolov5/data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False
|
||||||
|
YOLOv5 🚀 v6.0-224-g4c40933 torch 1.10.0+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)
|
||||||
|
|
||||||
|
Fusing layers...
|
||||||
|
Model Summary: 444 layers, 86705005 parameters, 0 gradients
|
||||||
|
Pruning model... 0.3 global sparsity
|
||||||
|
val: Scanning '/content/datasets/coco/val2017.cache' images and labels... 4952 found, 48 missing, 0 empty, 0 corrupt: 100% 5000/5000 [00:00<?, ?it/s]
|
||||||
|
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [01:11<00:00, 2.19it/s]
|
||||||
|
all 5000 36335 0.724 0.614 0.671 0.478
|
||||||
|
Speed: 0.1ms pre-process, 5.2ms inference, 1.7ms NMS per image at shape (32, 3, 640, 640) # <--- prune mAP
|
||||||
|
|
||||||
|
Evaluating pycocotools mAP... saving runs/val/exp3/yolov5x_predictions.json...
|
||||||
|
...
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.489 # <--- prune mAP
|
||||||
|
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.677
|
||||||
|
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.537
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.334
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.542
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.635
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.370
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.612
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.664
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.496
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.722
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.803
|
||||||
|
Results saved to runs/val/exp3
|
||||||
|
```
|
||||||
|
|
||||||
|
In the results we can observe that we have achieved a **sparsity of 30%** in our model after pruning, which means that 30% of the model's weight parameters in `nn.Conv2d` layers are equal to 0. **Inference time is essentially unchanged**, while the model's **AP and AR scores a slightly reduced**.
|
||||||
|
|
||||||
|
|
||||||
|
## Environments
|
||||||
|
|
||||||
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||||
|
|
||||||
|
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||||
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||||
|
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
|
||||||
|
## Status
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
|
||||||
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||||
290
docs/yolov5/pytorch_hub.md
Normal file
@@ -0,0 +1,290 @@
|
|||||||
|
📚 This guide explains how to load YOLOv5 🚀 from PyTorch Hub at [https://pytorch.org/hub/ultralytics_yolov5](https://pytorch.org/hub/ultralytics_yolov5).
|
||||||
|
UPDATED 26 March 2023.
|
||||||
|
|
||||||
|
## Before You Start
|
||||||
|
|
||||||
|
Install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install -r https://raw.githubusercontent.com/ultralytics/yolov5/master/requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
💡 ProTip: Cloning [https://github.com/ultralytics/yolov5](https://github.com/ultralytics/yolov5) is **not** required 😃
|
||||||
|
|
||||||
|
## Load YOLOv5 with PyTorch Hub
|
||||||
|
|
||||||
|
### Simple Example
|
||||||
|
|
||||||
|
This example loads a pretrained YOLOv5s model from PyTorch Hub as `model` and passes an image for inference. `'yolov5s'` is the lightest and fastest YOLOv5 model. For details on all available models please see the [README](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
|
||||||
|
```python
|
||||||
|
import torch
|
||||||
|
|
||||||
|
# Model
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
|
||||||
|
|
||||||
|
# Image
|
||||||
|
im = 'https://ultralytics.com/images/zidane.jpg'
|
||||||
|
|
||||||
|
# Inference
|
||||||
|
results = model(im)
|
||||||
|
|
||||||
|
results.pandas().xyxy[0]
|
||||||
|
# xmin ymin xmax ymax confidence class name
|
||||||
|
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
|
||||||
|
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
|
||||||
|
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
|
||||||
|
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
### Detailed Example
|
||||||
|
|
||||||
|
This example shows **batched inference** with **PIL** and **OpenCV** image sources. `results` can be **printed** to console, **saved** to `runs/hub`, **showed** to screen on supported environments, and returned as **tensors** or **pandas** dataframes.
|
||||||
|
```python
|
||||||
|
import cv2
|
||||||
|
import torch
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
|
# Model
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
|
||||||
|
|
||||||
|
# Images
|
||||||
|
for f in 'zidane.jpg', 'bus.jpg':
|
||||||
|
torch.hub.download_url_to_file('https://ultralytics.com/images/' + f, f) # download 2 images
|
||||||
|
im1 = Image.open('zidane.jpg') # PIL image
|
||||||
|
im2 = cv2.imread('bus.jpg')[..., ::-1] # OpenCV image (BGR to RGB)
|
||||||
|
|
||||||
|
# Inference
|
||||||
|
results = model([im1, im2], size=640) # batch of images
|
||||||
|
|
||||||
|
# Results
|
||||||
|
results.print()
|
||||||
|
results.save() # or .show()
|
||||||
|
|
||||||
|
results.xyxy[0] # im1 predictions (tensor)
|
||||||
|
results.pandas().xyxy[0] # im1 predictions (pandas)
|
||||||
|
# xmin ymin xmax ymax confidence class name
|
||||||
|
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
|
||||||
|
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
|
||||||
|
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
|
||||||
|
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
|
||||||
|
```
|
||||||
|
<img src="https://user-images.githubusercontent.com/26833433/124915064-62a49e00-dff1-11eb-86b3-a85b97061afb.jpg" width="500"> <img src="https://user-images.githubusercontent.com/26833433/124915055-60424400-dff1-11eb-9055-24585b375a29.jpg" width="300">
|
||||||
|
|
||||||
|
For all inference options see YOLOv5 `AutoShape()` forward [method](https://github.com/ultralytics/yolov5/blob/30e4c4f09297b67afedf8b2bcd851833ddc9dead/models/common.py#L243-L252).
|
||||||
|
|
||||||
|
### Inference Settings
|
||||||
|
YOLOv5 models contain various inference attributes such as **confidence threshold**, **IoU threshold**, etc. which can be set by:
|
||||||
|
```python
|
||||||
|
model.conf = 0.25 # NMS confidence threshold
|
||||||
|
iou = 0.45 # NMS IoU threshold
|
||||||
|
agnostic = False # NMS class-agnostic
|
||||||
|
multi_label = False # NMS multiple labels per box
|
||||||
|
classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
|
||||||
|
max_det = 1000 # maximum number of detections per image
|
||||||
|
amp = False # Automatic Mixed Precision (AMP) inference
|
||||||
|
|
||||||
|
results = model(im, size=320) # custom inference size
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
### Device
|
||||||
|
Models can be transferred to any device after creation:
|
||||||
|
```python
|
||||||
|
model.cpu() # CPU
|
||||||
|
model.cuda() # GPU
|
||||||
|
model.to(device) # i.e. device=torch.device(0)
|
||||||
|
```
|
||||||
|
|
||||||
|
Models can also be created directly on any `device`:
|
||||||
|
```python
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on CPU
|
||||||
|
```
|
||||||
|
|
||||||
|
💡 ProTip: Input images are automatically transferred to the correct model device before inference.
|
||||||
|
|
||||||
|
### Silence Outputs
|
||||||
|
Models can be loaded silently with `_verbose=False`:
|
||||||
|
```python
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', _verbose=False) # load silently
|
||||||
|
```
|
||||||
|
|
||||||
|
### Input Channels
|
||||||
|
To load a pretrained YOLOv5s model with 4 input channels rather than the default 3:
|
||||||
|
```python
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)
|
||||||
|
```
|
||||||
|
In this case the model will be composed of pretrained weights **except for** the very first input layer, which is no longer the same shape as the pretrained input layer. The input layer will remain initialized by random weights.
|
||||||
|
|
||||||
|
### Number of Classes
|
||||||
|
To load a pretrained YOLOv5s model with 10 output classes rather than the default 80:
|
||||||
|
```python
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)
|
||||||
|
```
|
||||||
|
In this case the model will be composed of pretrained weights **except for** the output layers, which are no longer the same shape as the pretrained output layers. The output layers will remain initialized by random weights.
|
||||||
|
|
||||||
|
### Force Reload
|
||||||
|
If you run into problems with the above steps, setting `force_reload=True` may help by discarding the existing cache and force a fresh download of the latest YOLOv5 version from PyTorch Hub.
|
||||||
|
```python
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reload
|
||||||
|
```
|
||||||
|
|
||||||
|
### Screenshot Inference
|
||||||
|
To run inference on your desktop screen:
|
||||||
|
```python
|
||||||
|
import torch
|
||||||
|
from PIL import ImageGrab
|
||||||
|
|
||||||
|
# Model
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
|
||||||
|
|
||||||
|
# Image
|
||||||
|
im = ImageGrab.grab() # take a screenshot
|
||||||
|
|
||||||
|
# Inference
|
||||||
|
results = model(im)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Multi-GPU Inference
|
||||||
|
|
||||||
|
YOLOv5 models can be loaded to multiple GPUs in parallel with threaded inference:
|
||||||
|
|
||||||
|
```python
|
||||||
|
import torch
|
||||||
|
import threading
|
||||||
|
|
||||||
|
def run(model, im):
|
||||||
|
results = model(im)
|
||||||
|
results.save()
|
||||||
|
|
||||||
|
# Models
|
||||||
|
model0 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=0)
|
||||||
|
model1 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=1)
|
||||||
|
|
||||||
|
# Inference
|
||||||
|
threading.Thread(target=run, args=[model0, 'https://ultralytics.com/images/zidane.jpg'], daemon=True).start()
|
||||||
|
threading.Thread(target=run, args=[model1, 'https://ultralytics.com/images/bus.jpg'], daemon=True).start()
|
||||||
|
```
|
||||||
|
|
||||||
|
### Training
|
||||||
|
To load a YOLOv5 model for training rather than inference, set `autoshape=False`. To load a model with randomly initialized weights (to train from scratch) use `pretrained=False`. You must provide your own training script in this case. Alternatively see our YOLOv5 [Train Custom Data Tutorial](https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data) for model training.
|
||||||
|
```python
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # load pretrained
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False) # load scratch
|
||||||
|
```
|
||||||
|
|
||||||
|
### Base64 Results
|
||||||
|
For use with API services. See https://github.com/ultralytics/yolov5/pull/2291 and [Flask REST API](https://github.com/ultralytics/yolov5/tree/master/utils/flask_rest_api) example for details.
|
||||||
|
```python
|
||||||
|
results = model(im) # inference
|
||||||
|
|
||||||
|
results.ims # array of original images (as np array) passed to model for inference
|
||||||
|
results.render() # updates results.ims with boxes and labels
|
||||||
|
for im in results.ims:
|
||||||
|
buffered = BytesIO()
|
||||||
|
im_base64 = Image.fromarray(im)
|
||||||
|
im_base64.save(buffered, format="JPEG")
|
||||||
|
print(base64.b64encode(buffered.getvalue()).decode('utf-8')) # base64 encoded image with results
|
||||||
|
```
|
||||||
|
|
||||||
|
### Cropped Results
|
||||||
|
Results can be returned and saved as detection crops:
|
||||||
|
```python
|
||||||
|
results = model(im) # inference
|
||||||
|
crops = results.crop(save=True) # cropped detections dictionary
|
||||||
|
```
|
||||||
|
|
||||||
|
### Pandas Results
|
||||||
|
Results can be returned as [Pandas DataFrames](https://pandas.pydata.org/):
|
||||||
|
```python
|
||||||
|
results = model(im) # inference
|
||||||
|
results.pandas().xyxy[0] # Pandas DataFrame
|
||||||
|
```
|
||||||
|
<details markdown>
|
||||||
|
<summary>Pandas Output (click to expand)</summary>
|
||||||
|
|
||||||
|
```python
|
||||||
|
print(results.pandas().xyxy[0])
|
||||||
|
# xmin ymin xmax ymax confidence class name
|
||||||
|
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
|
||||||
|
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
|
||||||
|
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
|
||||||
|
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
|
||||||
|
```
|
||||||
|
</details>
|
||||||
|
|
||||||
|
### Sorted Results
|
||||||
|
Results can be sorted by column, i.e. to sort license plate digit detection left-to-right (x-axis):
|
||||||
|
```python
|
||||||
|
results = model(im) # inference
|
||||||
|
results.pandas().xyxy[0].sort_values('xmin') # sorted left-right
|
||||||
|
```
|
||||||
|
|
||||||
|
### Box-Cropped Results
|
||||||
|
Results can be returned and saved as detection crops:
|
||||||
|
```python
|
||||||
|
results = model(im) # inference
|
||||||
|
crops = results.crop(save=True) # cropped detections dictionary
|
||||||
|
```
|
||||||
|
|
||||||
|
### JSON Results
|
||||||
|
Results can be returned in JSON format once converted to `.pandas()` dataframes using the `.to_json()` method. The JSON format can be modified using the `orient` argument. See pandas `.to_json()` [documentation](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_json.html) for details.
|
||||||
|
```python
|
||||||
|
results = model(ims) # inference
|
||||||
|
results.pandas().xyxy[0].to_json(orient="records") # JSON img1 predictions
|
||||||
|
```
|
||||||
|
|
||||||
|
<details markdown>
|
||||||
|
<summary>JSON Output (click to expand)</summary>
|
||||||
|
|
||||||
|
```json
|
||||||
|
[
|
||||||
|
{"xmin":749.5,"ymin":43.5,"xmax":1148.0,"ymax":704.5,"confidence":0.8740234375,"class":0,"name":"person"},
|
||||||
|
{"xmin":433.5,"ymin":433.5,"xmax":517.5,"ymax":714.5,"confidence":0.6879882812,"class":27,"name":"tie"},
|
||||||
|
{"xmin":115.25,"ymin":195.75,"xmax":1096.0,"ymax":708.0,"confidence":0.6254882812,"class":0,"name":"person"},
|
||||||
|
{"xmin":986.0,"ymin":304.0,"xmax":1028.0,"ymax":420.0,"confidence":0.2873535156,"class":27,"name":"tie"}
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
## Custom Models
|
||||||
|
This example loads a custom 20-class [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml)-trained YOLOv5s model `'best.pt'` with PyTorch Hub.
|
||||||
|
```python
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt') # local model
|
||||||
|
model = torch.hub.load('path/to/yolov5', 'custom', path='path/to/best.pt', source='local') # local repo
|
||||||
|
```
|
||||||
|
|
||||||
|
## TensorRT, ONNX and OpenVINO Models
|
||||||
|
|
||||||
|
PyTorch Hub supports inference on most YOLOv5 export formats, including custom trained models. See [TFLite, ONNX, CoreML, TensorRT Export tutorial](https://github.com/ultralytics/yolov5/issues/251) for details on exporting models.
|
||||||
|
|
||||||
|
💡 ProTip: **TensorRT** may be up to 2-5X faster than PyTorch on [**GPU benchmarks**](https://github.com/ultralytics/yolov5/pull/6963)
|
||||||
|
💡 ProTip: **ONNX** and **OpenVINO** may be up to 2-3X faster than PyTorch on [**CPU benchmarks**](https://github.com/ultralytics/yolov5/pull/6613)
|
||||||
|
|
||||||
|
```python
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.pt') # PyTorch
|
||||||
|
'yolov5s.torchscript') # TorchScript
|
||||||
|
'yolov5s.onnx') # ONNX
|
||||||
|
'yolov5s_openvino_model/') # OpenVINO
|
||||||
|
'yolov5s.engine') # TensorRT
|
||||||
|
'yolov5s.mlmodel') # CoreML (macOS-only)
|
||||||
|
'yolov5s.tflite') # TFLite
|
||||||
|
'yolov5s_paddle_model/') # PaddlePaddle
|
||||||
|
```
|
||||||
|
|
||||||
|
## Environments
|
||||||
|
|
||||||
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||||
|
|
||||||
|
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||||
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||||
|
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
|
||||||
|
## Status
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
|
||||||
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||||
37
docs/yolov5/roboflow.md
Normal file
@@ -0,0 +1,37 @@
|
|||||||
|
# Roboflow Datasets
|
||||||
|
|
||||||
|
You can now use Roboflow to organize, label, prepare, version, and host your datasets for training YOLOv5 🚀 models. Roboflow is free to use with YOLOv5 if you make your workspace public.
|
||||||
|
UPDATED 30 September 2021.
|
||||||
|
|
||||||
|
## Upload
|
||||||
|
You can upload your data to Roboflow via [web UI](https://docs.roboflow.com/adding-data), [rest API](https://docs.roboflow.com/adding-data/upload-api), or [python](https://docs.roboflow.com/python).
|
||||||
|
|
||||||
|
## Labeling
|
||||||
|
After uploading data to Roboflow, you can label your data and review previous labels.
|
||||||
|
|
||||||
|
[](https://roboflow.com/annotate)
|
||||||
|
|
||||||
|
## Versioning
|
||||||
|
You can make versions of your dataset with different preprocessing and offline augmentation options. YOLOv5 does online augmentations natively, so be intentional when layering Roboflow's offline augs on top.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Exporting Data
|
||||||
|
You can download your data in YOLOv5 format to quickly begin training.
|
||||||
|
|
||||||
|
```
|
||||||
|
from roboflow import Roboflow
|
||||||
|
rf = Roboflow(api_key="YOUR API KEY HERE")
|
||||||
|
project = rf.workspace().project("YOUR PROJECT")
|
||||||
|
dataset = project.version("YOUR VERSION").download("yolov5")
|
||||||
|
```
|
||||||
|
|
||||||
|
## Custom Training
|
||||||
|
We have released a custom training tutorial demonstrating all of the above capabilities. You can access the code here:
|
||||||
|
|
||||||
|
[](https://colab.research.google.com/github/roboflow-ai/yolov5-custom-training-tutorial/blob/main/yolov5-custom-training.ipynb)
|
||||||
|
|
||||||
|
## Active Learning
|
||||||
|
The real world is messy and your model will invariably encounter situations your dataset didn't anticipate. Using [active learning](https://blog.roboflow.com/what-is-active-learning/) is an important strategy to iteratively improve your dataset and model. With the Roboflow and YOLOv5 integration, you can quickly make improvements on your model deployments by using a battle tested machine learning pipeline.
|
||||||
|
|
||||||
|
<p align=""><a href="https://roboflow.com/?ref=ultralytics"><img width="1000" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/615627e5824c9c6195abfda9_computer-vision-cycle.png"/></a></p>
|
||||||
59
docs/yolov5/tips_for_best_training_results.md
Normal file
@@ -0,0 +1,59 @@
|
|||||||
|
📚 This guide explains how to produce the best mAP and training results with YOLOv5 🚀.
|
||||||
|
UPDATED 25 May 2022.
|
||||||
|
|
||||||
|
Most of the time good results can be obtained with no changes to the models or training settings, **provided your dataset is sufficiently large and well labelled**. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users **first train with all default settings** before considering any changes. This helps establish a performance baseline and spot areas for improvement.
|
||||||
|
|
||||||
|
If you have questions about your training results **we recommend you provide the maximum amount of information possible** if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, confusion matrix, training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your `project/name` directory, typically `yolov5/runs/train/exp`.
|
||||||
|
|
||||||
|
We've put together a full guide for users looking to get the best results on their YOLOv5 trainings below.
|
||||||
|
|
||||||
|
## Dataset
|
||||||
|
|
||||||
|
- **Images per class.** ≥ 1500 images per class recommended
|
||||||
|
- **Instances per class.** ≥ 10000 instances (labeled objects) per class recommended
|
||||||
|
- **Image variety.** Must be representative of deployed environment. For real-world use cases we recommend images from different times of day, different seasons, different weather, different lighting, different angles, different sources (scraped online, collected locally, different cameras) etc.
|
||||||
|
- **Label consistency.** All instances of all classes in all images must be labelled. Partial labelling will not work.
|
||||||
|
- **Label accuracy.** Labels must closely enclose each object. No space should exist between an object and it's bounding box. No objects should be missing a label.
|
||||||
|
- **Label verification.** View `train_batch*.jpg` on train start to verify your labels appear correct, i.e. see [example](https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data#local-logging) mosaic.
|
||||||
|
- **Background images.** Background images are images with no objects that are added to a dataset to reduce False Positives (FP). We recommend about 0-10% background images to help reduce FPs (COCO has 1000 background images for reference, 1% of the total). No labels are required for background images.
|
||||||
|
|
||||||
|
<a href="https://arxiv.org/abs/1405.0312"><img width="800" src="https://user-images.githubusercontent.com/26833433/109398377-82b0ac00-78f1-11eb-9c76-cc7820669d0d.png" alt="COCO Analysis"></a>
|
||||||
|
|
||||||
|
|
||||||
|
## Model Selection
|
||||||
|
|
||||||
|
Larger models like YOLOv5x and [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/tag/v5.0) will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For **mobile** deployments we recommend YOLOv5s/m, for **cloud** deployments we recommend YOLOv5l/x. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
|
||||||
|
|
||||||
|
<p align="center"><img width="700" alt="YOLOv5 Models" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/model_comparison.png"></p>
|
||||||
|
|
||||||
|
- **Start from Pretrained weights.** Recommended for small to medium-sized datasets (i.e. [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml), [VisDrone](https://github.com/ultralytics/yolov5/blob/master/data/VisDrone.yaml), [GlobalWheat](https://github.com/ultralytics/yolov5/blob/master/data/GlobalWheat2020.yaml)). Pass the name of the model to the `--weights` argument. Models download automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases).
|
||||||
|
```shell
|
||||||
|
python train.py --data custom.yaml --weights yolov5s.pt
|
||||||
|
yolov5m.pt
|
||||||
|
yolov5l.pt
|
||||||
|
yolov5x.pt
|
||||||
|
custom_pretrained.pt
|
||||||
|
```
|
||||||
|
- **Start from Scratch.** Recommended for large datasets (i.e. [COCO](https://github.com/ultralytics/yolov5/blob/master/data/coco.yaml), [Objects365](https://github.com/ultralytics/yolov5/blob/master/data/Objects365.yaml), [OIv6](https://storage.googleapis.com/openimages/web/index.html)). Pass the model architecture yaml you are interested in, along with an empty `--weights ''` argument:
|
||||||
|
```bash
|
||||||
|
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
|
||||||
|
yolov5m.yaml
|
||||||
|
yolov5l.yaml
|
||||||
|
yolov5x.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## Training Settings
|
||||||
|
|
||||||
|
Before modifying anything, **first train with default settings to establish a performance baseline**. A full list of train.py settings can be found in the [train.py](https://github.com/ultralytics/yolov5/blob/master/train.py) argparser.
|
||||||
|
|
||||||
|
- **Epochs.** Start with 300 epochs. If this overfits early then you can reduce epochs. If overfitting does not occur after 300 epochs, train longer, i.e. 600, 1200 etc epochs.
|
||||||
|
- **Image size.** COCO trains at native resolution of `--img 640`, though due to the high amount of small objects in the dataset it can benefit from training at higher resolutions such as `--img 1280`. If there are many small objects then custom datasets will benefit from training at native or higher resolution. Best inference results are obtained at the same `--img` as the training was run at, i.e. if you train at `--img 1280` you should also test and detect at `--img 1280`.
|
||||||
|
- **Batch size.** Use the largest `--batch-size` that your hardware allows for. Small batch sizes produce poor batchnorm statistics and should be avoided.
|
||||||
|
- **Hyperparameters.** Default hyperparameters are in [hyp.scratch-low.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml). We recommend you train with default hyperparameters first before thinking of modifying any. In general, increasing augmentation hyperparameters will reduce and delay overfitting, allowing for longer trainings and higher final mAP. Reduction in loss component gain hyperparameters like `hyp['obj']` will help reduce overfitting in those specific loss components. For an automated method of optimizing these hyperparameters, see our [Hyperparameter Evolution Tutorial](https://github.com/ultralytics/yolov5/issues/607).
|
||||||
|
|
||||||
|
## Further Reading
|
||||||
|
|
||||||
|
If you'd like to know more, a good place to start is Karpathy's 'Recipe for Training Neural Networks', which has great ideas for training that apply broadly across all ML domains: [http://karpathy.github.io/2019/04/25/recipe/](http://karpathy.github.io/2019/04/25/recipe/)
|
||||||
|
|
||||||
|
Good luck 🍀 and let us know if you have any other questions!
|
||||||
229
docs/yolov5/train_custom_data.md
Normal file
@@ -0,0 +1,229 @@
|
|||||||
|
📚 This guide explains how to train your own **custom dataset** with [YOLOv5](https://github.com/ultralytics/yolov5) 🚀.
|
||||||
|
UPDATED 26 March 2023.
|
||||||
|
|
||||||
|
## Before You Start
|
||||||
|
|
||||||
|
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ultralytics/yolov5 # clone
|
||||||
|
cd yolov5
|
||||||
|
pip install -r requirements.txt # install
|
||||||
|
```
|
||||||
|
|
||||||
|
## Train On Custom Data
|
||||||
|
|
||||||
|
<a href="https://bit.ly/ultralytics_hub" target="_blank">
|
||||||
|
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/integrations-loop.png"></a>
|
||||||
|
<br>
|
||||||
|
<br>
|
||||||
|
|
||||||
|
Creating a custom model to detect your objects is an iterative process of collecting and organizing images, labeling your objects of interest, training a model, deploying it into the wild to make predictions, and then using that deployed model to collect examples of edge cases to repeat and improve.
|
||||||
|
|
||||||
|
### 1. Create Dataset
|
||||||
|
|
||||||
|
YOLOv5 models must be trained on labelled data in order to learn classes of objects in that data. There are two options for creating your dataset before you start training:
|
||||||
|
|
||||||
|
<details markdown>
|
||||||
|
<summary>Use Roboflow to manage your dataset in YOLO format</summary>
|
||||||
|
|
||||||
|
### 1.1 Collect Images
|
||||||
|
|
||||||
|
Your model will learn by example. Training on images similar to the ones it will see in the wild is of the utmost importance. Ideally, you will collect a wide variety of images from the same configuration (camera, angle, lighting, etc.) as you will ultimately deploy your project.
|
||||||
|
|
||||||
|
If this is not possible, you can start from [a public dataset](https://universe.roboflow.com/?ref=ultralytics) to train your initial model and then [sample images from the wild during inference](https://blog.roboflow.com/computer-vision-active-learning-tips/?ref=ultralytics) to improve your dataset and model iteratively.
|
||||||
|
|
||||||
|
### 1.2 Create Labels
|
||||||
|
|
||||||
|
Once you have collected images, you will need to annotate the objects of interest to create a ground truth for your model to learn from.
|
||||||
|
|
||||||
|
<p align="center"><a href="https://app.roboflow.com/?model=yolov5&ref=ultralytics" title="Create a Free Roboflow Account"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a275ad4b4ac20cd2e21a_roboflow-annotate.gif" /></a></p>
|
||||||
|
|
||||||
|
[Roboflow Annotate](https://roboflow.com/annotate?ref=ultralytics) is a simple
|
||||||
|
web-based tool for managing and labeling your images with your team and exporting
|
||||||
|
them in [YOLOv5's annotation format](https://roboflow.com/formats/yolov5-pytorch-txt?ref=ultralytics).
|
||||||
|
|
||||||
|
### 1.3 Prepare Dataset for YOLOv5
|
||||||
|
|
||||||
|
Whether you [label your images with Roboflow](https://roboflow.com/annotate?ref=ultralytics) or not, you can use it to convert your dataset into YOLO format, create a YOLOv5 YAML configuration file, and host it for importing into your training script.
|
||||||
|
|
||||||
|
[Create a free Roboflow account](https://app.roboflow.com/?model=yolov5&ref=ultralytics)
|
||||||
|
and upload your dataset to a `Public` workspace, label any unannotated images,
|
||||||
|
then generate and export a version of your dataset in `YOLOv5 Pytorch` format.
|
||||||
|
|
||||||
|
Note: YOLOv5 does online augmentation during training, so we do not recommend
|
||||||
|
applying any augmentation steps in Roboflow for training with YOLOv5. But we
|
||||||
|
recommend applying the following preprocessing steps:
|
||||||
|
|
||||||
|
<p align="center"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a273477fccf42a0fd3d6_roboflow-preprocessing.png" title="Recommended Preprocessing Steps" /></p>
|
||||||
|
|
||||||
|
* **Auto-Orient** - to strip EXIF orientation from your images.
|
||||||
|
* **Resize (Stretch)** - to the square input size of your model (640x640 is the YOLOv5 default).
|
||||||
|
|
||||||
|
Generating a version will give you a point in time snapshot of your dataset so
|
||||||
|
you can always go back and compare your future model training runs against it,
|
||||||
|
even if you add more images or change its configuration later.
|
||||||
|
|
||||||
|
<p align="center"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a2733fd1da943619934e_roboflow-export.png" title="Export in YOLOv5 Format" /></p>
|
||||||
|
|
||||||
|
Export in `YOLOv5 Pytorch` format, then copy the snippet into your training
|
||||||
|
script or notebook to download your dataset.
|
||||||
|
|
||||||
|
<p align="center"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a273a92e4f5cb72594df_roboflow-snippet.png" title="Roboflow dataset download snippet" /></p>
|
||||||
|
|
||||||
|
Now continue with `2. Select a Model`.
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open markdown>
|
||||||
|
<summary>Or manually prepare your dataset</summary>
|
||||||
|
|
||||||
|
### 1.1 Create dataset.yaml
|
||||||
|
|
||||||
|
[COCO128](https://www.kaggle.com/ultralytics/coco128) is an example small tutorial dataset composed of the first 128 images in [COCO](http://cocodataset.org/#home) train2017. These same 128 images are used for both training and validation to verify our training pipeline is capable of overfitting. [data/coco128.yaml](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), shown below, is the dataset config file that defines 1) the dataset root directory `path` and relative paths to `train` / `val` / `test` image directories (or *.txt files with image paths) and 2) a class `names` dictionary:
|
||||||
|
```yaml
|
||||||
|
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||||
|
path: ../datasets/coco128 # dataset root dir
|
||||||
|
train: images/train2017 # train images (relative to 'path') 128 images
|
||||||
|
val: images/train2017 # val images (relative to 'path') 128 images
|
||||||
|
test: # test images (optional)
|
||||||
|
|
||||||
|
# Classes (80 COCO classes)
|
||||||
|
names:
|
||||||
|
0: person
|
||||||
|
1: bicycle
|
||||||
|
2: car
|
||||||
|
...
|
||||||
|
77: teddy bear
|
||||||
|
78: hair drier
|
||||||
|
79: toothbrush
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
### 1.2 Create Labels
|
||||||
|
|
||||||
|
After using an annotation tool to label your images, export your labels to **YOLO format**, with one `*.txt` file per image (if no objects in image, no `*.txt` file is required). The `*.txt` file specifications are:
|
||||||
|
|
||||||
|
- One row per object
|
||||||
|
- Each row is `class x_center y_center width height` format.
|
||||||
|
- Box coordinates must be in **normalized xywh** format (from 0 - 1). If your boxes are in pixels, divide `x_center` and `width` by image width, and `y_center` and `height` by image height.
|
||||||
|
- Class numbers are zero-indexed (start from 0).
|
||||||
|
|
||||||
|
<p align="center"><img width="750" src="https://user-images.githubusercontent.com/26833433/91506361-c7965000-e886-11ea-8291-c72b98c25eec.jpg"></p>
|
||||||
|
|
||||||
|
The label file corresponding to the above image contains 2 persons (class `0`) and a tie (class `27`):
|
||||||
|
|
||||||
|
<p align="center"><img width="428" src="https://user-images.githubusercontent.com/26833433/112467037-d2568c00-8d66-11eb-8796-55402ac0d62f.png"></p>
|
||||||
|
|
||||||
|
|
||||||
|
### 1.3 Organize Directories
|
||||||
|
|
||||||
|
Organize your train and val images and labels according to the example below. YOLOv5 assumes `/coco128` is inside a `/datasets` directory **next to** the `/yolov5` directory. **YOLOv5 locates labels automatically for each image** by replacing the last instance of `/images/` in each image path with `/labels/`. For example:
|
||||||
|
```bash
|
||||||
|
../datasets/coco128/images/im0.jpg # image
|
||||||
|
../datasets/coco128/labels/im0.txt # label
|
||||||
|
```
|
||||||
|
|
||||||
|
<p align="center"><img width="700" src="https://user-images.githubusercontent.com/26833433/134436012-65111ad1-9541-4853-81a6-f19a3468b75f.png"></p>
|
||||||
|
</details>
|
||||||
|
|
||||||
|
|
||||||
|
### 2. Select a Model
|
||||||
|
|
||||||
|
Select a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the second-smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
|
||||||
|
|
||||||
|
<p align="center"><img width="800" alt="YOLOv5 Models" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/model_comparison.png"></p>
|
||||||
|
|
||||||
|
### 3. Train
|
||||||
|
|
||||||
|
Train a YOLOv5s model on COCO128 by specifying dataset, batch-size, image size and either pretrained `--weights yolov5s.pt` (recommended), or randomly initialized `--weights '' --cfg yolov5s.yaml` (not recommended). Pretrained weights are auto-downloaded from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases).
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt
|
||||||
|
```
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
💡 Add `--cache ram` or `--cache disk` to speed up training (requires significant RAM/disk resources).
|
||||||
|
|
||||||
|
!!! tip "Tip"
|
||||||
|
|
||||||
|
💡 Always train from a local dataset. Mounted or network drives like Google Drive will be very slow.
|
||||||
|
|
||||||
|
All training results are saved to `runs/train/` with incrementing run directories, i.e. `runs/train/exp2`, `runs/train/exp3` etc. For more details see the Training section of our tutorial notebook. <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
|
||||||
|
### 4. Visualize
|
||||||
|
|
||||||
|
#### Comet Logging and Visualization 🌟 NEW
|
||||||
|
|
||||||
|
[Comet](https://bit.ly/yolov5-readme-comet) is now fully integrated with YOLOv5. Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://bit.ly/yolov5-colab-comet-panels)! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
|
||||||
|
|
||||||
|
Getting started is easy:
|
||||||
|
```shell
|
||||||
|
pip install comet_ml # 1. install
|
||||||
|
export COMET_API_KEY=<Your API Key> # 2. paste API key
|
||||||
|
python train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt # 3. train
|
||||||
|
```
|
||||||
|
|
||||||
|
To learn more about all the supported Comet features for this integration, check out the [Comet Tutorial](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/comet). If you'd like to learn more about Comet, head over to our [documentation](https://bit.ly/yolov5-colab-comet-docs). Get started by trying out the Comet Colab Notebook:
|
||||||
|
[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
|
||||||
|
|
||||||
|
<img width="1920" alt="yolo-ui" src="https://user-images.githubusercontent.com/26833433/202851203-164e94e1-2238-46dd-91f8-de020e9d6b41.png">
|
||||||
|
|
||||||
|
#### ClearML Logging and Automation 🌟 NEW
|
||||||
|
|
||||||
|
[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML:
|
||||||
|
|
||||||
|
- `pip install clearml`
|
||||||
|
- run `clearml-init` to connect to a ClearML server (**deploy your own open-source server [here](https://github.com/allegroai/clearml-server)**, or use our free hosted server [here](https://cutt.ly/yolov5-notebook-clearml))
|
||||||
|
|
||||||
|
You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).
|
||||||
|
|
||||||
|
You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/clearml) for details!
|
||||||
|
|
||||||
|
<a href="https://cutt.ly/yolov5-notebook-clearml">
|
||||||
|
<img alt="ClearML Experiment Management UI" src="https://github.com/thepycoder/clearml_screenshots/raw/main/scalars.jpg" width="1280"/></a>
|
||||||
|
|
||||||
|
|
||||||
|
#### Local Logging
|
||||||
|
|
||||||
|
Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.
|
||||||
|
|
||||||
|
This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.
|
||||||
|
|
||||||
|
<img alt="Local logging results" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/image-local_logging.jpg" width="1280"/>
|
||||||
|
|
||||||
|
Results file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from utils.plots import plot_results
|
||||||
|
plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
|
||||||
|
```
|
||||||
|
|
||||||
|
<p align="center"><img width="800" alt="results.png" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/results.png"></p>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Next Steps
|
||||||
|
|
||||||
|
Once your model is trained you can use your best checkpoint `best.pt` to:
|
||||||
|
* Run [CLI](https://github.com/ultralytics/yolov5#quick-start-examples) or [Python](https://github.com/ultralytics/yolov5/issues/36) inference on new images and videos
|
||||||
|
* [Validate](https://github.com/ultralytics/yolov5/blob/master/val.py) accuracy on train, val and test splits
|
||||||
|
* [Export](https://github.com/ultralytics/yolov5/issues/251) to TensorFlow, Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats
|
||||||
|
* [Evolve](https://github.com/ultralytics/yolov5/issues/607) hyperparameters to improve performance
|
||||||
|
* [Improve](https://docs.roboflow.com/adding-data/upload-api?ref=ultralytics) your model by sampling real-world images and adding them to your dataset
|
||||||
|
|
||||||
|
|
||||||
|
## Environments
|
||||||
|
|
||||||
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||||
|
|
||||||
|
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||||
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||||
|
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
|
||||||
|
## Status
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
|
||||||
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||||
146
docs/yolov5/transfer_learn_frozen.md
Normal file
@@ -0,0 +1,146 @@
|
|||||||
|
📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **transfer learning**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy.
|
||||||
|
UPDATED 25 September 2022.
|
||||||
|
|
||||||
|
|
||||||
|
## Before You Start
|
||||||
|
|
||||||
|
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ultralytics/yolov5 # clone
|
||||||
|
cd yolov5
|
||||||
|
pip install -r requirements.txt # install
|
||||||
|
```
|
||||||
|
|
||||||
|
## Freeze Backbone
|
||||||
|
|
||||||
|
All layers that match the train.py `freeze` list in train.py will be frozen by setting their gradients to zero before training starts.
|
||||||
|
```python
|
||||||
|
# Freeze
|
||||||
|
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
|
||||||
|
for k, v in model.named_parameters():
|
||||||
|
v.requires_grad = True # train all layers
|
||||||
|
if any(x in k for x in freeze):
|
||||||
|
print(f'freezing {k}')
|
||||||
|
v.requires_grad = False
|
||||||
|
```
|
||||||
|
|
||||||
|
To see a list of module names:
|
||||||
|
```python
|
||||||
|
for k, v in model.named_parameters():
|
||||||
|
print(k)
|
||||||
|
|
||||||
|
# Output
|
||||||
|
model.0.conv.conv.weight
|
||||||
|
model.0.conv.bn.weight
|
||||||
|
model.0.conv.bn.bias
|
||||||
|
model.1.conv.weight
|
||||||
|
model.1.bn.weight
|
||||||
|
model.1.bn.bias
|
||||||
|
model.2.cv1.conv.weight
|
||||||
|
model.2.cv1.bn.weight
|
||||||
|
...
|
||||||
|
model.23.m.0.cv2.bn.weight
|
||||||
|
model.23.m.0.cv2.bn.bias
|
||||||
|
model.24.m.0.weight
|
||||||
|
model.24.m.0.bias
|
||||||
|
model.24.m.1.weight
|
||||||
|
model.24.m.1.bias
|
||||||
|
model.24.m.2.weight
|
||||||
|
model.24.m.2.bias
|
||||||
|
```
|
||||||
|
|
||||||
|
Looking at the model architecture we can see that the model backbone is layers 0-9:
|
||||||
|
```yaml
|
||||||
|
# YOLOv5 backbone
|
||||||
|
backbone:
|
||||||
|
# [from, number, module, args]
|
||||||
|
[[-1, 1, Focus, [64, 3]], # 0-P1/2
|
||||||
|
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
|
||||||
|
[-1, 3, BottleneckCSP, [128]],
|
||||||
|
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
|
||||||
|
[-1, 9, BottleneckCSP, [256]],
|
||||||
|
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
|
||||||
|
[-1, 9, BottleneckCSP, [512]],
|
||||||
|
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
|
||||||
|
[-1, 1, SPP, [1024, [5, 9, 13]]],
|
||||||
|
[-1, 3, BottleneckCSP, [1024, False]], # 9
|
||||||
|
]
|
||||||
|
|
||||||
|
# YOLOv5 head
|
||||||
|
head:
|
||||||
|
[[-1, 1, Conv, [512, 1, 1]],
|
||||||
|
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
||||||
|
[[-1, 6], 1, Concat, [1]], # cat backbone P4
|
||||||
|
[-1, 3, BottleneckCSP, [512, False]], # 13
|
||||||
|
|
||||||
|
[-1, 1, Conv, [256, 1, 1]],
|
||||||
|
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
||||||
|
[[-1, 4], 1, Concat, [1]], # cat backbone P3
|
||||||
|
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
|
||||||
|
|
||||||
|
[-1, 1, Conv, [256, 3, 2]],
|
||||||
|
[[-1, 14], 1, Concat, [1]], # cat head P4
|
||||||
|
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
|
||||||
|
|
||||||
|
[-1, 1, Conv, [512, 3, 2]],
|
||||||
|
[[-1, 10], 1, Concat, [1]], # cat head P5
|
||||||
|
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
|
||||||
|
|
||||||
|
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
so we can define the freeze list to contain all modules with 'model.0.' - 'model.9.' in their names:
|
||||||
|
```bash
|
||||||
|
python train.py --freeze 10
|
||||||
|
```
|
||||||
|
|
||||||
|
## Freeze All Layers
|
||||||
|
|
||||||
|
To freeze the full model except for the final output convolution layers in Detect(), we set freeze list to contain all modules with 'model.0.' - 'model.23.' in their names:
|
||||||
|
```bash
|
||||||
|
python train.py --freeze 24
|
||||||
|
```
|
||||||
|
|
||||||
|
## Results
|
||||||
|
|
||||||
|
We train YOLOv5m on VOC on both of the above scenarios, along with a default model (no freezing), starting from the official COCO pretrained `--weights yolov5m.pt`:
|
||||||
|
```python
|
||||||
|
train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --img 512 --hyp hyp.finetune.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
### Accuracy Comparison
|
||||||
|
|
||||||
|
The results show that freezing speeds up training, but reduces final accuracy slightly.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
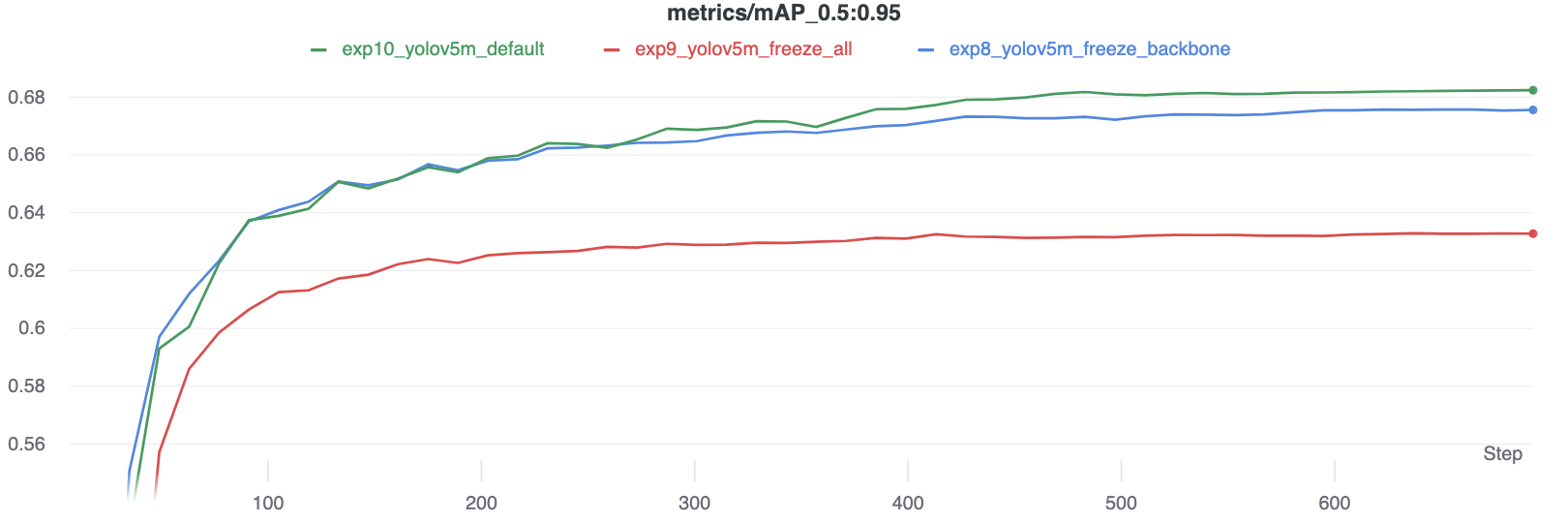
|
||||||
|
|
||||||
|
<img width="922" alt="Screenshot 2020-11-06 at 18 08 13" src="https://user-images.githubusercontent.com/26833433/98394485-22081580-205b-11eb-9e37-1f9869fe91d8.png">
|
||||||
|
|
||||||
|
### GPU Utilization Comparison
|
||||||
|
|
||||||
|
Interestingly, the more modules are frozen the less GPU memory is required to train, and the lower GPU utilization. This indicates that larger models, or models trained at larger --image-size may benefit from freezing in order to train faster.
|
||||||
|
|
||||||
|
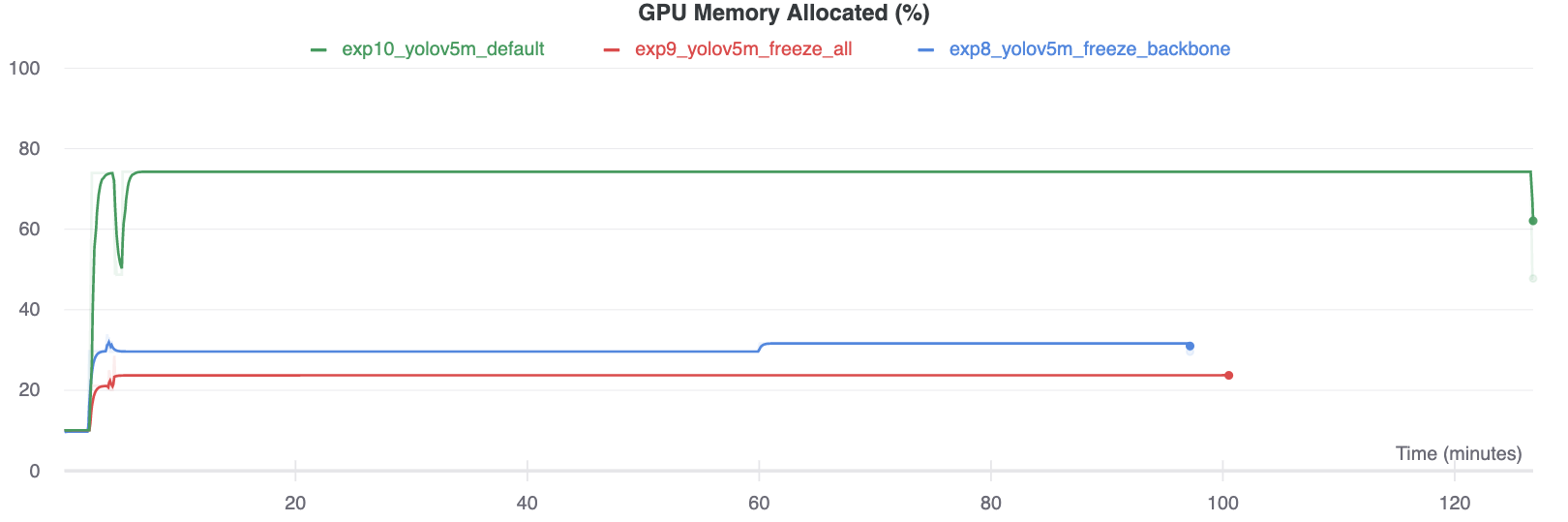
|
||||||
|
|
||||||
|
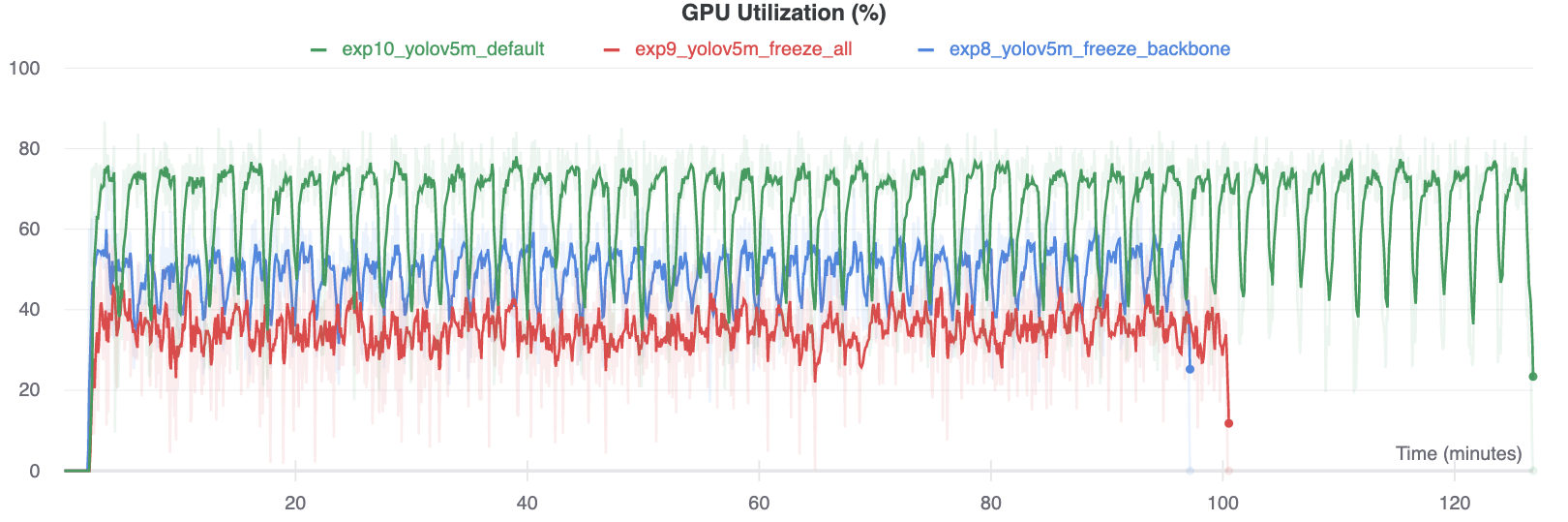
|
||||||
|
|
||||||
|
|
||||||
|
## Environments
|
||||||
|
|
||||||
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||||
|
|
||||||
|
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||||
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||||
|
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
|
||||||
|
## Status
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
|
||||||
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||||
154
docs/yolov5/tta.md
Normal file
@@ -0,0 +1,154 @@
|
|||||||
|
# Test-Time Augmentation (TTA)
|
||||||
|
|
||||||
|
📚 This guide explains how to use Test Time Augmentation (TTA) during testing and inference for improved mAP and Recall with YOLOv5 🚀.
|
||||||
|
UPDATED 25 September 2022.
|
||||||
|
|
||||||
|
## Before You Start
|
||||||
|
|
||||||
|
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/ultralytics/yolov5 # clone
|
||||||
|
cd yolov5
|
||||||
|
pip install -r requirements.txt # install
|
||||||
|
```
|
||||||
|
|
||||||
|
## Test Normally
|
||||||
|
|
||||||
|
Before trying TTA we want to establish a baseline performance to compare to. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
|
||||||
|
```bash
|
||||||
|
python val.py --weights yolov5x.pt --data coco.yaml --img 640 --half
|
||||||
|
```
|
||||||
|
|
||||||
|
Output:
|
||||||
|
```shell
|
||||||
|
val: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
|
||||||
|
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||||
|
|
||||||
|
Fusing layers...
|
||||||
|
Model Summary: 476 layers, 87730285 parameters, 0 gradients
|
||||||
|
|
||||||
|
val: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2846.03it/s]
|
||||||
|
val: New cache created: ../datasets/coco/val2017.cache
|
||||||
|
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [02:30<00:00, 1.05it/s]
|
||||||
|
all 5000 36335 0.746 0.626 0.68 0.49
|
||||||
|
Speed: 0.1ms pre-process, 22.4ms inference, 1.4ms NMS per image at shape (32, 3, 640, 640) # <--- baseline speed
|
||||||
|
|
||||||
|
Evaluating pycocotools mAP... saving runs/val/exp/yolov5x_predictions.json...
|
||||||
|
...
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.504 # <--- baseline mAP
|
||||||
|
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.688
|
||||||
|
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.546
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.351
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.551
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.644
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.382
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.628
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.681 # <--- baseline mAR
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.524
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.735
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.826
|
||||||
|
```
|
||||||
|
|
||||||
|
## Test with TTA
|
||||||
|
Append `--augment` to any existing `val.py` command to enable TTA, and increase the image size by about 30% for improved results. Note that inference with TTA enabled will typically take about 2-3X the time of normal inference as the images are being left-right flipped and processed at 3 different resolutions, with the outputs merged before NMS. Part of the speed decrease is simply due to larger image sizes (832 vs 640), while part is due to the actual TTA operations.
|
||||||
|
```bash
|
||||||
|
python val.py --weights yolov5x.pt --data coco.yaml --img 832 --augment --half
|
||||||
|
```
|
||||||
|
|
||||||
|
Output:
|
||||||
|
```shell
|
||||||
|
val: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=832, conf_thres=0.001, iou_thres=0.6, task=val, device=, single_cls=False, augment=True, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
|
||||||
|
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||||
|
|
||||||
|
Fusing layers...
|
||||||
|
/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)
|
||||||
|
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
|
||||||
|
Model Summary: 476 layers, 87730285 parameters, 0 gradients
|
||||||
|
val: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2885.61it/s]
|
||||||
|
val: New cache created: ../datasets/coco/val2017.cache
|
||||||
|
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [07:29<00:00, 2.86s/it]
|
||||||
|
all 5000 36335 0.718 0.656 0.695 0.503
|
||||||
|
Speed: 0.2ms pre-process, 80.6ms inference, 2.7ms NMS per image at shape (32, 3, 832, 832) # <--- TTA speed
|
||||||
|
|
||||||
|
Evaluating pycocotools mAP... saving runs/val/exp2/yolov5x_predictions.json...
|
||||||
|
...
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.516 # <--- TTA mAP
|
||||||
|
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.701
|
||||||
|
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.562
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.361
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.564
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.656
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.388
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.640
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.696 # <--- TTA mAR
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.553
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.744
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.833
|
||||||
|
```
|
||||||
|
|
||||||
|
## Inference with TTA
|
||||||
|
|
||||||
|
`detect.py` TTA inference operates identically to `val.py` TTA: simply append `--augment` to any existing `detect.py` command:
|
||||||
|
```bash
|
||||||
|
python detect.py --weights yolov5s.pt --img 832 --source data/images --augment
|
||||||
|
```
|
||||||
|
|
||||||
|
Output:
|
||||||
|
```bash
|
||||||
|
detect: weights=['yolov5s.pt'], source=data/images, imgsz=832, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=True, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False
|
||||||
|
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||||
|
|
||||||
|
Downloading https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.pt to yolov5s.pt...
|
||||||
|
100% 14.1M/14.1M [00:00<00:00, 81.9MB/s]
|
||||||
|
|
||||||
|
Fusing layers...
|
||||||
|
Model Summary: 224 layers, 7266973 parameters, 0 gradients
|
||||||
|
image 1/2 /content/yolov5/data/images/bus.jpg: 832x640 4 persons, 1 bus, 1 fire hydrant, Done. (0.029s)
|
||||||
|
image 2/2 /content/yolov5/data/images/zidane.jpg: 480x832 3 persons, 3 ties, Done. (0.024s)
|
||||||
|
Results saved to runs/detect/exp
|
||||||
|
Done. (0.156s)
|
||||||
|
```
|
||||||
|
|
||||||
|
<img src="https://user-images.githubusercontent.com/26833433/124491703-dbb6b200-ddb3-11eb-8b57-ed0d58d0d8b4.jpg" width="500">
|
||||||
|
|
||||||
|
|
||||||
|
### PyTorch Hub TTA
|
||||||
|
|
||||||
|
TTA is automatically integrated into all [YOLOv5 PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5) models, and can be accessed by passing `augment=True` at inference time.
|
||||||
|
```python
|
||||||
|
import torch
|
||||||
|
|
||||||
|
# Model
|
||||||
|
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom
|
||||||
|
|
||||||
|
# Images
|
||||||
|
img = 'https://ultralytics.com/images/zidane.jpg' # or file, PIL, OpenCV, numpy, multiple
|
||||||
|
|
||||||
|
# Inference
|
||||||
|
results = model(img, augment=True) # <--- TTA inference
|
||||||
|
|
||||||
|
# Results
|
||||||
|
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
|
||||||
|
```
|
||||||
|
|
||||||
|
### Customize
|
||||||
|
|
||||||
|
You can customize the TTA ops applied in the YOLOv5 `forward_augment()` method [here](https://github.com/ultralytics/yolov5/blob/8c6f9e15bfc0000d18b976a95b9d7c17d407ec91/models/yolo.py#L125-L137).
|
||||||
|
|
||||||
|
|
||||||
|
## Environments
|
||||||
|
|
||||||
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||||
|
|
||||||
|
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||||
|
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||||
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||||
|
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
|
|
||||||
|
## Status
|
||||||
|
|
||||||
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||||
|
|
||||||
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||||
24
examples/README.md
Normal file
@@ -0,0 +1,24 @@
|
|||||||
|
## Ultralytics YOLOv8 Example Applications
|
||||||
|
|
||||||
|
This repository features a collection of real-world applications and walkthroughs, provided as either Python files or notebooks. Explore the examples below to see how YOLOv8 can be integrated into various applications.
|
||||||
|
|
||||||
|
### Ultralytics YOLO Example Applications
|
||||||
|
|
||||||
|
| Title | Format | Contributor |
|
||||||
|
| ------------------------------------------------------------------------ | ------------------ | --------------------------------------------------- |
|
||||||
|
| [YOLO ONNX Detection Inference with C++](./YOLOv8-CPP-Inference) | C++/ONNX | [Justas Bartnykas](https://github.com/JustasBart) |
|
||||||
|
| [YOLO OpenCV ONNX Detection Python](./YOLOv8-OpenCV-ONNX-Python) | OpenCV/Python/ONNX | [Farid Inawan](https://github.com/frdteknikelektro) |
|
||||||
|
| [YOLO .Net ONNX Detection C#](https://www.nuget.org/packages/Yolov8.Net) | C# .Net | [Samuel Stainback](https://github.com/sstainba) |
|
||||||
|
|
||||||
|
### How to Contribute
|
||||||
|
|
||||||
|
We welcome contributions from the community in the form of examples, applications, and guides. To contribute, please follow these steps:
|
||||||
|
|
||||||
|
1. Create a pull request (PR) with the `[Example]` prefix in the title, adding your project folder to the `examples/` directory in the repository.
|
||||||
|
1. Ensure that your project meets the following criteria:
|
||||||
|
- Utilizes the `ultralytics` package.
|
||||||
|
- Includes a `README.md` file with instructions on how to run the project.
|
||||||
|
- Avoids adding large assets or dependencies unless absolutely necessary.
|
||||||
|
- The contributor is expected to provide support for issues related to their examples.
|
||||||
|
|
||||||
|
If you have any questions or concerns about these requirements, please submit a PR, and we will be more than happy to guide you.
|
||||||
28
examples/YOLOv8-CPP-Inference/CMakeLists.txt
Normal file
@@ -0,0 +1,28 @@
|
|||||||
|
cmake_minimum_required(VERSION 3.5)
|
||||||
|
|
||||||
|
project(Yolov8CPPInference VERSION 0.1)
|
||||||
|
|
||||||
|
set(CMAKE_INCLUDE_CURRENT_DIR ON)
|
||||||
|
|
||||||
|
# CUDA
|
||||||
|
set(CUDA_TOOLKIT_ROOT_DIR "/usr/local/cuda")
|
||||||
|
find_package(CUDA 11 REQUIRED)
|
||||||
|
|
||||||
|
set(CMAKE_CUDA_STANDARD 11)
|
||||||
|
set(CMAKE_CUDA_STANDARD_REQUIRED ON)
|
||||||
|
# !CUDA
|
||||||
|
|
||||||
|
# OpenCV
|
||||||
|
find_package(OpenCV REQUIRED)
|
||||||
|
include_directories(${OpenCV_INCLUDE_DIRS})
|
||||||
|
# !OpenCV
|
||||||
|
|
||||||
|
set(PROJECT_SOURCES
|
||||||
|
main.cpp
|
||||||
|
|
||||||
|
inference.h
|
||||||
|
inference.cpp
|
||||||
|
)
|
||||||
|
|
||||||
|
add_executable(Yolov8CPPInference ${PROJECT_SOURCES})
|
||||||
|
target_link_libraries(Yolov8CPPInference ${OpenCV_LIBS})
|
||||||
50
examples/YOLOv8-CPP-Inference/README.md
Normal file
@@ -0,0 +1,50 @@
|
|||||||
|
# YOLOv8/YOLOv5 Inference C++
|
||||||
|
|
||||||
|
This example demonstrates how to perform inference using YOLOv8 and YOLOv5 models in C++ with OpenCV's DNN API.
|
||||||
|
|
||||||
|
## Usage
|
||||||
|
|
||||||
|
```commandline
|
||||||
|
git clone ultralytics
|
||||||
|
cd ultralytics
|
||||||
|
pip install .
|
||||||
|
cd examples/cpp_
|
||||||
|
|
||||||
|
# Add a **yolov8\_.onnx** and/or **yolov5\_.onnx** model(s) to the ultralytics folder.
|
||||||
|
# Edit the **main.cpp** to change the **projectBasePath** to match your user.
|
||||||
|
|
||||||
|
# Note that by default the CMake file will try and import the CUDA library to be used with the OpenCVs dnn (cuDNN) GPU Inference.
|
||||||
|
# If your OpenCV build does not use CUDA/cuDNN you can remove that import call and run the example on CPU.
|
||||||
|
|
||||||
|
mkdir build
|
||||||
|
cd build
|
||||||
|
cmake ..
|
||||||
|
make
|
||||||
|
./Yolov8CPPInference
|
||||||
|
```
|
||||||
|
|
||||||
|
## Exporting YOLOv8 and YOLOv5 Models
|
||||||
|
|
||||||
|
To export YOLOv8 models:
|
||||||
|
|
||||||
|
```commandline
|
||||||
|
yolo export model=yolov8s.pt imgsz=480,640 format=onnx opset=12
|
||||||
|
```
|
||||||
|
|
||||||
|
To export YOLOv5 models:
|
||||||
|
|
||||||
|
```commandline
|
||||||
|
python3 export.py --weights yolov5s.pt --img 480 640 --include onnx --opset 12
|
||||||
|
```
|
||||||
|
|
||||||
|
yolov8s.onnx:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
yolov5s.onnx:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
This repository utilizes OpenCV's DNN API to run ONNX exported models of YOLOv5 and YOLOv8. In theory, it should work for YOLOv6 and YOLOv7 as well, but they have not been tested. Note that the example networks are exported with rectangular (640x480) resolutions, but any exported resolution will work. You may want to use the letterbox approach for square images, depending on your use case.
|
||||||
|
|
||||||
|
The **main** branch version uses Qt as a GUI wrapper. The primary focus here is the **Inference** class file, which demonstrates how to transpose YOLOv8 models to work as YOLOv5 models.
|
||||||
185
examples/YOLOv8-CPP-Inference/inference.cpp
Normal file
@@ -0,0 +1,185 @@
|
|||||||
|
#include "inference.h"
|
||||||
|
|
||||||
|
Inference::Inference(const std::string &onnxModelPath, const cv::Size &modelInputShape, const std::string &classesTxtFile, const bool &runWithCuda)
|
||||||
|
{
|
||||||
|
modelPath = onnxModelPath;
|
||||||
|
modelShape = modelInputShape;
|
||||||
|
classesPath = classesTxtFile;
|
||||||
|
cudaEnabled = runWithCuda;
|
||||||
|
|
||||||
|
loadOnnxNetwork();
|
||||||
|
// loadClassesFromFile(); The classes are hard-coded for this example
|
||||||
|
}
|
||||||
|
|
||||||
|
std::vector<Detection> Inference::runInference(const cv::Mat &input)
|
||||||
|
{
|
||||||
|
cv::Mat modelInput = input;
|
||||||
|
if (letterBoxForSquare && modelShape.width == modelShape.height)
|
||||||
|
modelInput = formatToSquare(modelInput);
|
||||||
|
|
||||||
|
cv::Mat blob;
|
||||||
|
cv::dnn::blobFromImage(modelInput, blob, 1.0/255.0, modelShape, cv::Scalar(), true, false);
|
||||||
|
net.setInput(blob);
|
||||||
|
|
||||||
|
std::vector<cv::Mat> outputs;
|
||||||
|
net.forward(outputs, net.getUnconnectedOutLayersNames());
|
||||||
|
|
||||||
|
int rows = outputs[0].size[1];
|
||||||
|
int dimensions = outputs[0].size[2];
|
||||||
|
|
||||||
|
bool yolov8 = false;
|
||||||
|
// yolov5 has an output of shape (batchSize, 25200, 85) (Num classes + box[x,y,w,h] + confidence[c])
|
||||||
|
// yolov8 has an output of shape (batchSize, 84, 8400) (Num classes + box[x,y,w,h])
|
||||||
|
if (dimensions > rows) // Check if the shape[2] is more than shape[1] (yolov8)
|
||||||
|
{
|
||||||
|
yolov8 = true;
|
||||||
|
rows = outputs[0].size[2];
|
||||||
|
dimensions = outputs[0].size[1];
|
||||||
|
|
||||||
|
outputs[0] = outputs[0].reshape(1, dimensions);
|
||||||
|
cv::transpose(outputs[0], outputs[0]);
|
||||||
|
}
|
||||||
|
float *data = (float *)outputs[0].data;
|
||||||
|
|
||||||
|
float x_factor = modelInput.cols / modelShape.width;
|
||||||
|
float y_factor = modelInput.rows / modelShape.height;
|
||||||
|
|
||||||
|
std::vector<int> class_ids;
|
||||||
|
std::vector<float> confidences;
|
||||||
|
std::vector<cv::Rect> boxes;
|
||||||
|
|
||||||
|
for (int i = 0; i < rows; ++i)
|
||||||
|
{
|
||||||
|
if (yolov8)
|
||||||
|
{
|
||||||
|
float *classes_scores = data+4;
|
||||||
|
|
||||||
|
cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);
|
||||||
|
cv::Point class_id;
|
||||||
|
double maxClassScore;
|
||||||
|
|
||||||
|
minMaxLoc(scores, 0, &maxClassScore, 0, &class_id);
|
||||||
|
|
||||||
|
if (maxClassScore > modelScoreThreshold)
|
||||||
|
{
|
||||||
|
confidences.push_back(maxClassScore);
|
||||||
|
class_ids.push_back(class_id.x);
|
||||||
|
|
||||||
|
float x = data[0];
|
||||||
|
float y = data[1];
|
||||||
|
float w = data[2];
|
||||||
|
float h = data[3];
|
||||||
|
|
||||||
|
int left = int((x - 0.5 * w) * x_factor);
|
||||||
|
int top = int((y - 0.5 * h) * y_factor);
|
||||||
|
|
||||||
|
int width = int(w * x_factor);
|
||||||
|
int height = int(h * y_factor);
|
||||||
|
|
||||||
|
boxes.push_back(cv::Rect(left, top, width, height));
|
||||||
|
}
|
||||||
|
}
|
||||||
|
else // yolov5
|
||||||
|
{
|
||||||
|
float confidence = data[4];
|
||||||
|
|
||||||
|
if (confidence >= modelConfidenceThreshold)
|
||||||
|
{
|
||||||
|
float *classes_scores = data+5;
|
||||||
|
|
||||||
|
cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);
|
||||||
|
cv::Point class_id;
|
||||||
|
double max_class_score;
|
||||||
|
|
||||||
|
minMaxLoc(scores, 0, &max_class_score, 0, &class_id);
|
||||||
|
|
||||||
|
if (max_class_score > modelScoreThreshold)
|
||||||
|
{
|
||||||
|
confidences.push_back(confidence);
|
||||||
|
class_ids.push_back(class_id.x);
|
||||||
|
|
||||||
|
float x = data[0];
|
||||||
|
float y = data[1];
|
||||||
|
float w = data[2];
|
||||||
|
float h = data[3];
|
||||||
|
|
||||||
|
int left = int((x - 0.5 * w) * x_factor);
|
||||||
|
int top = int((y - 0.5 * h) * y_factor);
|
||||||
|
|
||||||
|
int width = int(w * x_factor);
|
||||||
|
int height = int(h * y_factor);
|
||||||
|
|
||||||
|
boxes.push_back(cv::Rect(left, top, width, height));
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
data += dimensions;
|
||||||
|
}
|
||||||
|
|
||||||
|
std::vector<int> nms_result;
|
||||||
|
cv::dnn::NMSBoxes(boxes, confidences, modelScoreThreshold, modelNMSThreshold, nms_result);
|
||||||
|
|
||||||
|
std::vector<Detection> detections{};
|
||||||
|
for (unsigned long i = 0; i < nms_result.size(); ++i)
|
||||||
|
{
|
||||||
|
int idx = nms_result[i];
|
||||||
|
|
||||||
|
Detection result;
|
||||||
|
result.class_id = class_ids[idx];
|
||||||
|
result.confidence = confidences[idx];
|
||||||
|
|
||||||
|
std::random_device rd;
|
||||||
|
std::mt19937 gen(rd());
|
||||||
|
std::uniform_int_distribution<int> dis(100, 255);
|
||||||
|
result.color = cv::Scalar(dis(gen),
|
||||||
|
dis(gen),
|
||||||
|
dis(gen));
|
||||||
|
|
||||||
|
result.className = classes[result.class_id];
|
||||||
|
result.box = boxes[idx];
|
||||||
|
|
||||||
|
detections.push_back(result);
|
||||||
|
}
|
||||||
|
|
||||||
|
return detections;
|
||||||
|
}
|
||||||
|
|
||||||
|
void Inference::loadClassesFromFile()
|
||||||
|
{
|
||||||
|
std::ifstream inputFile(classesPath);
|
||||||
|
if (inputFile.is_open())
|
||||||
|
{
|
||||||
|
std::string classLine;
|
||||||
|
while (std::getline(inputFile, classLine))
|
||||||
|
classes.push_back(classLine);
|
||||||
|
inputFile.close();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
void Inference::loadOnnxNetwork()
|
||||||
|
{
|
||||||
|
net = cv::dnn::readNetFromONNX(modelPath);
|
||||||
|
if (cudaEnabled)
|
||||||
|
{
|
||||||
|
std::cout << "\nRunning on CUDA" << std::endl;
|
||||||
|
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
|
||||||
|
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
|
||||||
|
}
|
||||||
|
else
|
||||||
|
{
|
||||||
|
std::cout << "\nRunning on CPU" << std::endl;
|
||||||
|
net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
|
||||||
|
net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
cv::Mat Inference::formatToSquare(const cv::Mat &source)
|
||||||
|
{
|
||||||
|
int col = source.cols;
|
||||||
|
int row = source.rows;
|
||||||
|
int _max = MAX(col, row);
|
||||||
|
cv::Mat result = cv::Mat::zeros(_max, _max, CV_8UC3);
|
||||||
|
source.copyTo(result(cv::Rect(0, 0, col, row)));
|
||||||
|
return result;
|
||||||
|
}
|
||||||
52
examples/YOLOv8-CPP-Inference/inference.h
Normal file
@@ -0,0 +1,52 @@
|
|||||||
|
#ifndef INFERENCE_H
|
||||||
|
#define INFERENCE_H
|
||||||
|
|
||||||
|
// Cpp native
|
||||||
|
#include <fstream>
|
||||||
|
#include <vector>
|
||||||
|
#include <string>
|
||||||
|
#include <random>
|
||||||
|
|
||||||
|
// OpenCV / DNN / Inference
|
||||||
|
#include <opencv2/imgproc.hpp>
|
||||||
|
#include <opencv2/opencv.hpp>
|
||||||
|
#include <opencv2/dnn.hpp>
|
||||||
|
|
||||||
|
struct Detection
|
||||||
|
{
|
||||||
|
int class_id{0};
|
||||||
|
std::string className{};
|
||||||
|
float confidence{0.0};
|
||||||
|
cv::Scalar color{};
|
||||||
|
cv::Rect box{};
|
||||||
|
};
|
||||||
|
|
||||||
|
class Inference
|
||||||
|
{
|
||||||
|
public:
|
||||||
|
Inference(const std::string &onnxModelPath, const cv::Size &modelInputShape = {640, 640}, const std::string &classesTxtFile = "", const bool &runWithCuda = true);
|
||||||
|
std::vector<Detection> runInference(const cv::Mat &input);
|
||||||
|
|
||||||
|
private:
|
||||||
|
void loadClassesFromFile();
|
||||||
|
void loadOnnxNetwork();
|
||||||
|
cv::Mat formatToSquare(const cv::Mat &source);
|
||||||
|
|
||||||
|
std::string modelPath{};
|
||||||
|
std::string classesPath{};
|
||||||
|
bool cudaEnabled{};
|
||||||
|
|
||||||
|
std::vector<std::string> classes{"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"};
|
||||||
|
|
||||||
|
cv::Size2f modelShape{};
|
||||||
|
|
||||||
|
float modelConfidenceThreshold {0.25};
|
||||||
|
float modelScoreThreshold {0.45};
|
||||||
|
float modelNMSThreshold {0.50};
|
||||||
|
|
||||||
|
bool letterBoxForSquare = true;
|
||||||
|
|
||||||
|
cv::dnn::Net net;
|
||||||
|
};
|
||||||
|
|
||||||
|
#endif // INFERENCE_H
|
||||||
70
examples/YOLOv8-CPP-Inference/main.cpp
Normal file
@@ -0,0 +1,70 @@
|
|||||||
|
#include <iostream>
|
||||||
|
#include <vector>
|
||||||
|
#include <getopt.h>
|
||||||
|
|
||||||
|
#include <opencv2/opencv.hpp>
|
||||||
|
|
||||||
|
#include "inference.h"
|
||||||
|
|
||||||
|
using namespace std;
|
||||||
|
using namespace cv;
|
||||||
|
|
||||||
|
int main(int argc, char **argv)
|
||||||
|
{
|
||||||
|
std::string projectBasePath = "/home/user/ultralytics"; // Set your ultralytics base path
|
||||||
|
|
||||||
|
bool runOnGPU = true;
|
||||||
|
|
||||||
|
//
|
||||||
|
// Pass in either:
|
||||||
|
//
|
||||||
|
// "yolov8s.onnx" or "yolov5s.onnx"
|
||||||
|
//
|
||||||
|
// To run Inference with yolov8/yolov5 (ONNX)
|
||||||
|
//
|
||||||
|
|
||||||
|
// Note that in this example the classes are hard-coded and 'classes.txt' is a place holder.
|
||||||
|
Inference inf(projectBasePath + "/yolov8s.onnx", cv::Size(640, 480), "classes.txt", runOnGPU);
|
||||||
|
|
||||||
|
std::vector<std::string> imageNames;
|
||||||
|
imageNames.push_back(projectBasePath + "/ultralytics/assets/bus.jpg");
|
||||||
|
imageNames.push_back(projectBasePath + "/ultralytics/assets/zidane.jpg");
|
||||||
|
|
||||||
|
for (int i = 0; i < imageNames.size(); ++i)
|
||||||
|
{
|
||||||
|
cv::Mat frame = cv::imread(imageNames[i]);
|
||||||
|
|
||||||
|
// Inference starts here...
|
||||||
|
std::vector<Detection> output = inf.runInference(frame);
|
||||||
|
|
||||||
|
int detections = output.size();
|
||||||
|
std::cout << "Number of detections:" << detections << std::endl;
|
||||||
|
|
||||||
|
for (int i = 0; i < detections; ++i)
|
||||||
|
{
|
||||||
|
Detection detection = output[i];
|
||||||
|
|
||||||
|
cv::Rect box = detection.box;
|
||||||
|
cv::Scalar color = detection.color;
|
||||||
|
|
||||||
|
// Detection box
|
||||||
|
cv::rectangle(frame, box, color, 2);
|
||||||
|
|
||||||
|
// Detection box text
|
||||||
|
std::string classString = detection.className + ' ' + std::to_string(detection.confidence).substr(0, 4);
|
||||||
|
cv::Size textSize = cv::getTextSize(classString, cv::FONT_HERSHEY_DUPLEX, 1, 2, 0);
|
||||||
|
cv::Rect textBox(box.x, box.y - 40, textSize.width + 10, textSize.height + 20);
|
||||||
|
|
||||||
|
cv::rectangle(frame, textBox, color, cv::FILLED);
|
||||||
|
cv::putText(frame, classString, cv::Point(box.x + 5, box.y - 10), cv::FONT_HERSHEY_DUPLEX, 1, cv::Scalar(0, 0, 0), 2, 0);
|
||||||
|
}
|
||||||
|
// Inference ends here...
|
||||||
|
|
||||||
|
// This is only for preview purposes
|
||||||
|
float scale = 0.8;
|
||||||
|
cv::resize(frame, frame, cv::Size(frame.cols*scale, frame.rows*scale));
|
||||||
|
cv::imshow("Inference", frame);
|
||||||
|
|
||||||
|
cv::waitKey(-1);
|
||||||
|
}
|
||||||
|
}
|
||||||
19
examples/YOLOv8-OpenCV-ONNX-Python/README.md
Normal file
@@ -0,0 +1,19 @@
|
|||||||
|
# YOLOv8 - OpenCV
|
||||||
|
|
||||||
|
Implementation YOLOv8 on OpenCV using ONNX Format.
|
||||||
|
|
||||||
|
Just simply clone and run
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install -r requirements.txt
|
||||||
|
python main.py --model yolov8n.onnx --img image.jpg
|
||||||
|
```
|
||||||
|
|
||||||
|
If you start from scratch:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install ultralytics
|
||||||
|
yolo export model=yolov8n.pt imgsz=640 format=onnx opset=12
|
||||||
|
```
|
||||||
|
|
||||||
|
_\*Make sure to include "opset=12"_
|
||||||
80
examples/YOLOv8-OpenCV-ONNX-Python/main.py
Normal file
@@ -0,0 +1,80 @@
|
|||||||
|
import argparse
|
||||||
|
|
||||||
|
import cv2.dnn
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
from ultralytics.yolo.utils import ROOT, yaml_load
|
||||||
|
from ultralytics.yolo.utils.checks import check_yaml
|
||||||
|
|
||||||
|
CLASSES = yaml_load(check_yaml('coco128.yaml'))['names']
|
||||||
|
|
||||||
|
colors = np.random.uniform(0, 255, size=(len(CLASSES), 3))
|
||||||
|
|
||||||
|
|
||||||
|
def draw_bounding_box(img, class_id, confidence, x, y, x_plus_w, y_plus_h):
|
||||||
|
label = f'{CLASSES[class_id]} ({confidence:.2f})'
|
||||||
|
color = colors[class_id]
|
||||||
|
cv2.rectangle(img, (x, y), (x_plus_w, y_plus_h), color, 2)
|
||||||
|
cv2.putText(img, label, (x - 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
|
||||||
|
|
||||||
|
|
||||||
|
def main(onnx_model, input_image):
|
||||||
|
model: cv2.dnn.Net = cv2.dnn.readNetFromONNX(onnx_model)
|
||||||
|
original_image: np.ndarray = cv2.imread(input_image)
|
||||||
|
[height, width, _] = original_image.shape
|
||||||
|
length = max((height, width))
|
||||||
|
image = np.zeros((length, length, 3), np.uint8)
|
||||||
|
image[0:height, 0:width] = original_image
|
||||||
|
scale = length / 640
|
||||||
|
|
||||||
|
blob = cv2.dnn.blobFromImage(image, scalefactor=1 / 255, size=(640, 640), swapRB=True)
|
||||||
|
model.setInput(blob)
|
||||||
|
outputs = model.forward()
|
||||||
|
|
||||||
|
outputs = np.array([cv2.transpose(outputs[0])])
|
||||||
|
rows = outputs.shape[1]
|
||||||
|
|
||||||
|
boxes = []
|
||||||
|
scores = []
|
||||||
|
class_ids = []
|
||||||
|
|
||||||
|
for i in range(rows):
|
||||||
|
classes_scores = outputs[0][i][4:]
|
||||||
|
(minScore, maxScore, minClassLoc, (x, maxClassIndex)) = cv2.minMaxLoc(classes_scores)
|
||||||
|
if maxScore >= 0.25:
|
||||||
|
box = [
|
||||||
|
outputs[0][i][0] - (0.5 * outputs[0][i][2]), outputs[0][i][1] - (0.5 * outputs[0][i][3]),
|
||||||
|
outputs[0][i][2], outputs[0][i][3]]
|
||||||
|
boxes.append(box)
|
||||||
|
scores.append(maxScore)
|
||||||
|
class_ids.append(maxClassIndex)
|
||||||
|
|
||||||
|
result_boxes = cv2.dnn.NMSBoxes(boxes, scores, 0.25, 0.45, 0.5)
|
||||||
|
|
||||||
|
detections = []
|
||||||
|
for i in range(len(result_boxes)):
|
||||||
|
index = result_boxes[i]
|
||||||
|
box = boxes[index]
|
||||||
|
detection = {
|
||||||
|
'class_id': class_ids[index],
|
||||||
|
'class_name': CLASSES[class_ids[index]],
|
||||||
|
'confidence': scores[index],
|
||||||
|
'box': box,
|
||||||
|
'scale': scale}
|
||||||
|
detections.append(detection)
|
||||||
|
draw_bounding_box(original_image, class_ids[index], scores[index], round(box[0] * scale), round(box[1] * scale),
|
||||||
|
round((box[0] + box[2]) * scale), round((box[1] + box[3]) * scale))
|
||||||
|
|
||||||
|
cv2.imshow('image', original_image)
|
||||||
|
cv2.waitKey(0)
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
|
||||||
|
return detections
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument('--model', default='yolov8n.onnx', help='Input your onnx model.')
|
||||||
|
parser.add_argument('--img', default=str(ROOT / 'assets/bus.jpg'), help='Path to input image.')
|
||||||
|
args = parser.parse_args()
|
||||||
|
main(args.model, args.img)
|
||||||
22
fonts/cv_puttext.py
Normal file
@@ -0,0 +1,22 @@
|
|||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
from PIL import Image, ImageDraw, ImageFont
|
||||||
|
|
||||||
|
def cv2ImgAddText(img, text, left, top, textColor=(0, 255, 0), textSize=20):
|
||||||
|
if (isinstance(img, np.ndarray)): #判断是否OpenCV图片类型
|
||||||
|
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
|
||||||
|
draw = ImageDraw.Draw(img)
|
||||||
|
fontText = ImageFont.truetype(
|
||||||
|
"fonts/platech.ttf", textSize, encoding="utf-8")
|
||||||
|
draw.text((left, top), text, textColor, font=fontText)
|
||||||
|
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
imgPath = "result.jpg"
|
||||||
|
img = cv2.imread(imgPath)
|
||||||
|
|
||||||
|
saveImg = cv2ImgAddText(img, '中国加油!', 50, 100, (255, 0, 0), 50)
|
||||||
|
|
||||||
|
# cv2.imshow('display',saveImg)
|
||||||
|
cv2.imwrite('save.jpg',saveImg)
|
||||||
|
# cv2.waitKey()
|
||||||
BIN
fonts/platech.ttf
Normal file
BIN
imgs/Quicker_20220930_180856.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.4 MiB |
BIN
imgs/Quicker_20220930_180919.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.0 MiB |
BIN
imgs/Quicker_20220930_180938.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 241 KiB |
BIN
imgs/Quicker_20220930_181044.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 328 KiB |
BIN
imgs/double_yellow.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
BIN
imgs/hongkang1.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 571 KiB |
BIN
imgs/police.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 382 KiB |
BIN
imgs/shi_lin_guan.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 47 KiB |
BIN
imgs/single_blue.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.8 MiB |
BIN
imgs/single_green.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 903 KiB |
BIN
imgs/single_yellow.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 85 KiB |
BIN
imgs/tmpA5E3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 513 KiB |
BIN
imgs/xue.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 999 KiB |
15
plate_recognition/double_plate_split_merge.py
Normal file
@@ -0,0 +1,15 @@
|
|||||||
|
import os
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
def get_split_merge(img):
|
||||||
|
h,w,c = img.shape
|
||||||
|
img_upper = img[0:int(5/12*h),:]
|
||||||
|
img_lower = img[int(1/3*h):,:]
|
||||||
|
img_upper = cv2.resize(img_upper,(img_lower.shape[1],img_lower.shape[0]))
|
||||||
|
new_img = np.hstack((img_upper,img_lower))
|
||||||
|
return new_img
|
||||||
|
|
||||||
|
if __name__=="__main__":
|
||||||
|
img = cv2.imread("double_plate/tmp8078.png")
|
||||||
|
new_img =get_split_merge(img)
|
||||||
|
cv2.imwrite("double_plate/new.jpg",new_img)
|
||||||
203
plate_recognition/plateNet.py
Normal file
@@ -0,0 +1,203 @@
|
|||||||
|
import torch.nn as nn
|
||||||
|
import torch
|
||||||
|
|
||||||
|
|
||||||
|
class myNet_ocr(nn.Module):
|
||||||
|
def __init__(self,cfg=None,num_classes=78,export=False):
|
||||||
|
super(myNet_ocr, self).__init__()
|
||||||
|
if cfg is None:
|
||||||
|
cfg =[32,32,64,64,'M',128,128,'M',196,196,'M',256,256]
|
||||||
|
# cfg =[32,32,'M',64,64,'M',128,128,'M',256,256]
|
||||||
|
self.feature = self.make_layers(cfg, True)
|
||||||
|
self.export = export
|
||||||
|
# self.classifier = nn.Linear(cfg[-1], num_classes)
|
||||||
|
# self.loc = nn.MaxPool2d((2, 2), (5, 1), (0, 1),ceil_mode=True)
|
||||||
|
# self.loc = nn.AvgPool2d((2, 2), (5, 2), (0, 1),ceil_mode=False)
|
||||||
|
self.loc = nn.MaxPool2d((5, 2), (1, 1),(0,1),ceil_mode=False)
|
||||||
|
self.newCnn=nn.Conv2d(cfg[-1],num_classes,1,1)
|
||||||
|
# self.newBn=nn.BatchNorm2d(num_classes)
|
||||||
|
def make_layers(self, cfg, batch_norm=False):
|
||||||
|
layers = []
|
||||||
|
in_channels = 3
|
||||||
|
for i in range(len(cfg)):
|
||||||
|
if i == 0:
|
||||||
|
conv2d =nn.Conv2d(in_channels, cfg[i], kernel_size=5,stride =1)
|
||||||
|
if batch_norm:
|
||||||
|
layers += [conv2d, nn.BatchNorm2d(cfg[i]), nn.ReLU(inplace=True)]
|
||||||
|
else:
|
||||||
|
layers += [conv2d, nn.ReLU(inplace=True)]
|
||||||
|
in_channels = cfg[i]
|
||||||
|
else :
|
||||||
|
if cfg[i] == 'M':
|
||||||
|
layers += [nn.MaxPool2d(kernel_size=3, stride=2,ceil_mode=True)]
|
||||||
|
else:
|
||||||
|
conv2d = nn.Conv2d(in_channels, cfg[i], kernel_size=3, padding=(1,1),stride =1)
|
||||||
|
if batch_norm:
|
||||||
|
layers += [conv2d, nn.BatchNorm2d(cfg[i]), nn.ReLU(inplace=True)]
|
||||||
|
else:
|
||||||
|
layers += [conv2d, nn.ReLU(inplace=True)]
|
||||||
|
in_channels = cfg[i]
|
||||||
|
return nn.Sequential(*layers)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.feature(x)
|
||||||
|
x=self.loc(x)
|
||||||
|
x=self.newCnn(x)
|
||||||
|
# x=self.newBn(x)
|
||||||
|
if self.export:
|
||||||
|
conv = x.squeeze(2) # b *512 * width
|
||||||
|
conv = conv.transpose(2,1) # [w, b, c]
|
||||||
|
# conv =conv.argmax(dim=2)
|
||||||
|
return conv
|
||||||
|
else:
|
||||||
|
b, c, h, w = x.size()
|
||||||
|
assert h == 1, "the height of conv must be 1"
|
||||||
|
conv = x.squeeze(2) # b *512 * width
|
||||||
|
conv = conv.permute(2, 0, 1) # [w, b, c]
|
||||||
|
# output = F.log_softmax(self.rnn(conv), dim=2)
|
||||||
|
output = torch.softmax(conv, dim=2)
|
||||||
|
return output
|
||||||
|
|
||||||
|
myCfg = [32,'M',64,'M',96,'M',128,'M',256]
|
||||||
|
class myNet(nn.Module):
|
||||||
|
def __init__(self,cfg=None,num_classes=3):
|
||||||
|
super(myNet, self).__init__()
|
||||||
|
if cfg is None:
|
||||||
|
cfg = myCfg
|
||||||
|
self.feature = self.make_layers(cfg, True)
|
||||||
|
self.classifier = nn.Linear(cfg[-1], num_classes)
|
||||||
|
def make_layers(self, cfg, batch_norm=False):
|
||||||
|
layers = []
|
||||||
|
in_channels = 3
|
||||||
|
for i in range(len(cfg)):
|
||||||
|
if i == 0:
|
||||||
|
conv2d =nn.Conv2d(in_channels, cfg[i], kernel_size=5,stride =1)
|
||||||
|
if batch_norm:
|
||||||
|
layers += [conv2d, nn.BatchNorm2d(cfg[i]), nn.ReLU(inplace=True)]
|
||||||
|
else:
|
||||||
|
layers += [conv2d, nn.ReLU(inplace=True)]
|
||||||
|
in_channels = cfg[i]
|
||||||
|
else :
|
||||||
|
if cfg[i] == 'M':
|
||||||
|
layers += [nn.MaxPool2d(kernel_size=3, stride=2,ceil_mode=True)]
|
||||||
|
else:
|
||||||
|
conv2d = nn.Conv2d(in_channels, cfg[i], kernel_size=3, padding=1,stride =1)
|
||||||
|
if batch_norm:
|
||||||
|
layers += [conv2d, nn.BatchNorm2d(cfg[i]), nn.ReLU(inplace=True)]
|
||||||
|
else:
|
||||||
|
layers += [conv2d, nn.ReLU(inplace=True)]
|
||||||
|
in_channels = cfg[i]
|
||||||
|
return nn.Sequential(*layers)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.feature(x)
|
||||||
|
x = nn.AvgPool2d(kernel_size=3, stride=1)(x)
|
||||||
|
x = x.view(x.size(0), -1)
|
||||||
|
y = self.classifier(x)
|
||||||
|
return y
|
||||||
|
|
||||||
|
|
||||||
|
class MyNet_color(nn.Module):
|
||||||
|
def __init__(self, class_num=6):
|
||||||
|
super(MyNet_color, self).__init__()
|
||||||
|
self.class_num = class_num
|
||||||
|
self.backbone = nn.Sequential(
|
||||||
|
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=(5, 5), stride=(1, 1)), # 0
|
||||||
|
torch.nn.BatchNorm2d(16),
|
||||||
|
nn.ReLU(),
|
||||||
|
nn.MaxPool2d(kernel_size=(2, 2)),
|
||||||
|
nn.Dropout(0),
|
||||||
|
nn.Flatten(),
|
||||||
|
nn.Linear(480, 64),
|
||||||
|
nn.Dropout(0),
|
||||||
|
nn.ReLU(),
|
||||||
|
nn.Linear(64, class_num),
|
||||||
|
nn.Dropout(0),
|
||||||
|
nn.Softmax(1)
|
||||||
|
)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
logits = self.backbone(x)
|
||||||
|
|
||||||
|
return logits
|
||||||
|
|
||||||
|
|
||||||
|
class myNet_ocr_color(nn.Module):
|
||||||
|
def __init__(self,cfg=None,num_classes=78,export=False,color_num=None):
|
||||||
|
super(myNet_ocr_color, self).__init__()
|
||||||
|
if cfg is None:
|
||||||
|
cfg =[32,32,64,64,'M',128,128,'M',196,196,'M',256,256]
|
||||||
|
# cfg =[32,32,'M',64,64,'M',128,128,'M',256,256]
|
||||||
|
self.feature = self.make_layers(cfg, True)
|
||||||
|
self.export = export
|
||||||
|
self.color_num=color_num
|
||||||
|
self.conv_out_num=12 #颜色第一个卷积层输出通道12
|
||||||
|
if self.color_num:
|
||||||
|
self.conv1=nn.Conv2d(cfg[-1],self.conv_out_num,kernel_size=3,stride=2)
|
||||||
|
self.bn1=nn.BatchNorm2d(self.conv_out_num)
|
||||||
|
self.relu1=nn.ReLU(inplace=True)
|
||||||
|
self.gap =nn.AdaptiveAvgPool2d(output_size=1)
|
||||||
|
self.color_classifier=nn.Conv2d(self.conv_out_num,self.color_num,kernel_size=1,stride=1)
|
||||||
|
self.color_bn = nn.BatchNorm2d(self.color_num)
|
||||||
|
self.flatten = nn.Flatten()
|
||||||
|
self.loc = nn.MaxPool2d((5, 2), (1, 1),(0,1),ceil_mode=False)
|
||||||
|
self.newCnn=nn.Conv2d(cfg[-1],num_classes,1,1)
|
||||||
|
# self.newBn=nn.BatchNorm2d(num_classes)
|
||||||
|
def make_layers(self, cfg, batch_norm=False):
|
||||||
|
layers = []
|
||||||
|
in_channels = 3
|
||||||
|
for i in range(len(cfg)):
|
||||||
|
if i == 0:
|
||||||
|
conv2d =nn.Conv2d(in_channels, cfg[i], kernel_size=5,stride =1)
|
||||||
|
if batch_norm:
|
||||||
|
layers += [conv2d, nn.BatchNorm2d(cfg[i]), nn.ReLU(inplace=True)]
|
||||||
|
else:
|
||||||
|
layers += [conv2d, nn.ReLU(inplace=True)]
|
||||||
|
in_channels = cfg[i]
|
||||||
|
else :
|
||||||
|
if cfg[i] == 'M':
|
||||||
|
layers += [nn.MaxPool2d(kernel_size=3, stride=2,ceil_mode=True)]
|
||||||
|
else:
|
||||||
|
conv2d = nn.Conv2d(in_channels, cfg[i], kernel_size=3, padding=(1,1),stride =1)
|
||||||
|
if batch_norm:
|
||||||
|
layers += [conv2d, nn.BatchNorm2d(cfg[i]), nn.ReLU(inplace=True)]
|
||||||
|
else:
|
||||||
|
layers += [conv2d, nn.ReLU(inplace=True)]
|
||||||
|
in_channels = cfg[i]
|
||||||
|
return nn.Sequential(*layers)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.feature(x)
|
||||||
|
if self.color_num:
|
||||||
|
x_color=self.conv1(x)
|
||||||
|
x_color=self.bn1(x_color)
|
||||||
|
x_color =self.relu1(x_color)
|
||||||
|
x_color = self.color_classifier(x_color)
|
||||||
|
x_color = self.color_bn(x_color)
|
||||||
|
x_color =self.gap(x_color)
|
||||||
|
x_color = self.flatten(x_color)
|
||||||
|
x=self.loc(x)
|
||||||
|
x=self.newCnn(x)
|
||||||
|
|
||||||
|
if self.export:
|
||||||
|
conv = x.squeeze(2) # b *512 * width
|
||||||
|
conv = conv.transpose(2,1) # [w, b, c]
|
||||||
|
if self.color_num:
|
||||||
|
return conv,x_color
|
||||||
|
return conv
|
||||||
|
else:
|
||||||
|
b, c, h, w = x.size()
|
||||||
|
assert h == 1, "the height of conv must be 1"
|
||||||
|
conv = x.squeeze(2) # b *512 * width
|
||||||
|
conv = conv.permute(2, 0, 1) # [w, b, c]
|
||||||
|
output = F.log_softmax(conv, dim=2)
|
||||||
|
if self.color_num:
|
||||||
|
return output,x_color
|
||||||
|
return output
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
x = torch.randn(1,3,48,216)
|
||||||
|
model = myNet_ocr(num_classes=78,export=True)
|
||||||
|
out = model(x)
|
||||||
|
print(out.shape)
|
||||||
119
plate_recognition/plate_rec.py
Normal file
@@ -0,0 +1,119 @@
|
|||||||
|
from plate_recognition.plateNet import myNet_ocr,myNet_ocr_color
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
import os
|
||||||
|
import time
|
||||||
|
import sys
|
||||||
|
|
||||||
|
def cv_imread(path): #可以读取中文路径的图片
|
||||||
|
img=cv2.imdecode(np.fromfile(path,dtype=np.uint8),-1)
|
||||||
|
return img
|
||||||
|
|
||||||
|
def allFilePath(rootPath,allFIleList):
|
||||||
|
fileList = os.listdir(rootPath)
|
||||||
|
for temp in fileList:
|
||||||
|
if os.path.isfile(os.path.join(rootPath,temp)):
|
||||||
|
if temp.endswith('.jpg') or temp.endswith('.png') or temp.endswith('.JPG'):
|
||||||
|
allFIleList.append(os.path.join(rootPath,temp))
|
||||||
|
else:
|
||||||
|
allFilePath(os.path.join(rootPath,temp),allFIleList)
|
||||||
|
device = torch.device('cuda') if torch.cuda.is_available() else torch.device("cpu")
|
||||||
|
color=['黑色','蓝色','绿色','白色','黄色']
|
||||||
|
plateName=r"#京沪津渝冀晋蒙辽吉黑苏浙皖闽赣鲁豫鄂湘粤桂琼川贵云藏陕甘青宁新学警港澳挂使领民航危0123456789ABCDEFGHJKLMNPQRSTUVWXYZ险品"
|
||||||
|
mean_value,std_value=(0.588,0.193)
|
||||||
|
def decodePlate(preds):
|
||||||
|
pre=0
|
||||||
|
newPreds=[]
|
||||||
|
index=[]
|
||||||
|
for i in range(len(preds)):
|
||||||
|
if preds[i]!=0 and preds[i]!=pre:
|
||||||
|
newPreds.append(preds[i])
|
||||||
|
index.append(i)
|
||||||
|
pre=preds[i]
|
||||||
|
return newPreds,index
|
||||||
|
|
||||||
|
def image_processing(img,device):
|
||||||
|
img = cv2.resize(img, (168,48))
|
||||||
|
img = np.reshape(img, (48, 168, 3))
|
||||||
|
|
||||||
|
# normalize
|
||||||
|
img = img.astype(np.float32)
|
||||||
|
img = (img / 255. - mean_value) / std_value
|
||||||
|
img = img.transpose([2, 0, 1])
|
||||||
|
img = torch.from_numpy(img)
|
||||||
|
|
||||||
|
img = img.to(device)
|
||||||
|
img = img.view(1, *img.size())
|
||||||
|
return img
|
||||||
|
|
||||||
|
def get_plate_result(img,device,model,is_color=False):
|
||||||
|
input = image_processing(img,device)
|
||||||
|
if is_color: #是否识别颜色
|
||||||
|
preds,color_preds = model(input)
|
||||||
|
color_preds = torch.softmax(color_preds,dim=-1)
|
||||||
|
color_conf,color_index = torch.max(color_preds,dim=-1)
|
||||||
|
color_conf=color_conf.item()
|
||||||
|
else:
|
||||||
|
preds = model(input)
|
||||||
|
preds=torch.softmax(preds,dim=-1)
|
||||||
|
prob,index=preds.max(dim=-1)
|
||||||
|
index = index.view(-1).detach().cpu().numpy()
|
||||||
|
prob=prob.view(-1).detach().cpu().numpy()
|
||||||
|
|
||||||
|
|
||||||
|
# preds=preds.view(-1).detach().cpu().numpy()
|
||||||
|
newPreds,new_index=decodePlate(index)
|
||||||
|
prob=prob[new_index]
|
||||||
|
plate=""
|
||||||
|
for i in newPreds:
|
||||||
|
plate+=plateName[i]
|
||||||
|
# if not (plate[0] in plateName[1:44] ):
|
||||||
|
# return ""
|
||||||
|
if is_color:
|
||||||
|
return plate,prob,color[color_index],color_conf #返回车牌号以及每个字符的概率,以及颜色,和颜色的概率
|
||||||
|
else:
|
||||||
|
return plate,prob
|
||||||
|
|
||||||
|
def init_model(device,model_path,is_color = False):
|
||||||
|
# print( print(sys.path))
|
||||||
|
# model_path ="plate_recognition/model/checkpoint_61_acc_0.9715.pth"
|
||||||
|
check_point = torch.load(model_path,map_location=device)
|
||||||
|
model_state=check_point['state_dict']
|
||||||
|
cfg=check_point['cfg']
|
||||||
|
color_classes=0
|
||||||
|
if is_color:
|
||||||
|
color_classes=5 #颜色类别数
|
||||||
|
model = myNet_ocr_color(num_classes=len(plateName),export=True,cfg=cfg,color_num=color_classes)
|
||||||
|
|
||||||
|
model.load_state_dict(model_state,strict=False)
|
||||||
|
model.to(device)
|
||||||
|
model.eval()
|
||||||
|
return model
|
||||||
|
|
||||||
|
# model = init_model(device)
|
||||||
|
if __name__ == '__main__':
|
||||||
|
model_path = r"weights/plate_rec_color.pth"
|
||||||
|
image_path ="images/tmp2424.png"
|
||||||
|
testPath = r"/mnt/Gpan/Mydata/pytorchPorject/CRNN/crnn_plate_recognition/images"
|
||||||
|
fileList=[]
|
||||||
|
allFilePath(testPath,fileList)
|
||||||
|
# result = get_plate_result(image_path,device)
|
||||||
|
# print(result)
|
||||||
|
is_color = False
|
||||||
|
model = init_model(device,model_path,is_color=is_color)
|
||||||
|
right=0
|
||||||
|
begin = time.time()
|
||||||
|
|
||||||
|
for imge_path in fileList:
|
||||||
|
img=cv2.imread(imge_path)
|
||||||
|
if is_color:
|
||||||
|
plate,_,plate_color,_=get_plate_result(img,device,model,is_color=is_color)
|
||||||
|
print(plate)
|
||||||
|
else:
|
||||||
|
plate,_=get_plate_result(img,device,model,is_color=is_color)
|
||||||
|
print(plate,imge_path)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
16
predict.py
Normal file
@@ -0,0 +1,16 @@
|
|||||||
|
from ultralytics import YOLO
|
||||||
|
from PIL import Image
|
||||||
|
from ultralytics.nn.tasks import attempt_load_weights
|
||||||
|
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('runs/pose/train4/weights/best.pt') # load an official model
|
||||||
|
# model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
|
# Predict with the model
|
||||||
|
results = model('h_0_008396.jpg') # predict on an image
|
||||||
|
for r in results:
|
||||||
|
print(r.boxes)
|
||||||
|
im_array = r.plot() # plot a BGR numpy array of predictions
|
||||||
|
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL image
|
||||||
|
# im.show() # show image
|
||||||
|
im.save('result.jpg') # save imagel9
|
||||||
32
readme/README.md
Normal file
@@ -0,0 +1,32 @@
|
|||||||
|
### **车牌检测训练**
|
||||||
|
|
||||||
|
1. **下载数据集:** [datasets](https://pan.baidu.com/s/1xa6zvOGjU02j8_lqHGVf0A) 提取码:pi6c 数据从CCPD和CRPD数据集中选取并转换的
|
||||||
|
数据集格式为yolo格式:
|
||||||
|
|
||||||
|
```
|
||||||
|
label x y w h pt1x pt1y pt2x pt2y pt3x pt3y pt4x pt4y
|
||||||
|
```
|
||||||
|
|
||||||
|
关键点依次是(左上,右上,右下,左下)
|
||||||
|
坐标都是经过归一化,x,y是中心点除以图片宽高,w,h是框的宽高除以图片宽高,ptx,pty是关键点坐标除以宽高
|
||||||
|
|
||||||
|
**自己的数据集**可以通过lablme 软件,create polygons标注车牌四个点即可,然后通过json2yolo.py 将数据集转为yolo格式,即可训练
|
||||||
|
2. **修改ultralytics/datasets/yolov8-plate.yaml train和val路径,换成你的数据路径**
|
||||||
|
|
||||||
|
```
|
||||||
|
train: /your/train/path #修改成你的训练集路径
|
||||||
|
val: /your/val/path #修改成你的验证集路径
|
||||||
|
# number of classes
|
||||||
|
nc: 2 #这里用的是2分类,0 单层车牌 1 双层车牌
|
||||||
|
|
||||||
|
# class names
|
||||||
|
names: [ 'single','double']
|
||||||
|
|
||||||
|
```
|
||||||
|
3. **训练**
|
||||||
|
|
||||||
|
```
|
||||||
|
python3 train.py --data data/widerface.yaml --cfg models/yolov5n-0.5.yaml --weights weights/plate_detect.pt --epoch 120
|
||||||
|
```
|
||||||
|
|
||||||
|
结果存在run文件夹中
|
||||||
43
requirements.txt
Normal file
@@ -0,0 +1,43 @@
|
|||||||
|
# Ultralytics requirements
|
||||||
|
# Usage: pip install -r requirements.txt
|
||||||
|
|
||||||
|
# Base ----------------------------------------
|
||||||
|
matplotlib>=3.2.2
|
||||||
|
numpy>=1.21.6
|
||||||
|
opencv-python>=4.6.0
|
||||||
|
Pillow>=7.1.2
|
||||||
|
PyYAML>=5.3.1
|
||||||
|
requests>=2.23.0
|
||||||
|
scipy>=1.4.1
|
||||||
|
torch>=1.7.0
|
||||||
|
torchvision>=0.8.1
|
||||||
|
tqdm>=4.64.0
|
||||||
|
|
||||||
|
# Logging -------------------------------------
|
||||||
|
# tensorboard>=2.4.1
|
||||||
|
# clearml
|
||||||
|
# comet
|
||||||
|
|
||||||
|
# Plotting ------------------------------------
|
||||||
|
pandas>=1.1.4
|
||||||
|
seaborn>=0.11.0
|
||||||
|
|
||||||
|
# Export --------------------------------------
|
||||||
|
# coremltools>=6.0 # CoreML export
|
||||||
|
# onnx>=1.12.0 # ONNX export
|
||||||
|
# onnxsim>=0.4.1 # ONNX simplifier
|
||||||
|
# nvidia-pyindex # TensorRT export
|
||||||
|
# nvidia-tensorrt # TensorRT export
|
||||||
|
# scikit-learn==0.19.2 # CoreML quantization
|
||||||
|
# tensorflow>=2.4.1 # TF exports (-cpu, -aarch64, -macos)
|
||||||
|
# tflite-support
|
||||||
|
# tensorflowjs>=3.9.0 # TF.js export
|
||||||
|
# openvino-dev>=2022.3 # OpenVINO export
|
||||||
|
|
||||||
|
# Extras --------------------------------------
|
||||||
|
psutil # system utilization
|
||||||
|
thop>=0.1.1 # FLOPs computation
|
||||||
|
# ipython # interactive notebook
|
||||||
|
# albumentations>=1.0.3
|
||||||
|
# pycocotools>=2.0.6 # COCO mAP
|
||||||
|
# roboflow
|
||||||
65
setup.py
Normal file
@@ -0,0 +1,65 @@
|
|||||||
|
# Ultralytics YOLO 🚀, GPL-3.0 license
|
||||||
|
|
||||||
|
import re
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import pkg_resources as pkg
|
||||||
|
from setuptools import find_packages, setup
|
||||||
|
|
||||||
|
# Settings
|
||||||
|
FILE = Path(__file__).resolve()
|
||||||
|
PARENT = FILE.parent # root directory
|
||||||
|
README = (PARENT / 'README.md').read_text(encoding='utf-8')
|
||||||
|
REQUIREMENTS = [f'{x.name}{x.specifier}' for x in pkg.parse_requirements((PARENT / 'requirements.txt').read_text())]
|
||||||
|
PKG_REQUIREMENTS = ['sentry_sdk'] # pip-only requirements
|
||||||
|
|
||||||
|
|
||||||
|
def get_version():
|
||||||
|
file = PARENT / 'ultralytics/__init__.py'
|
||||||
|
return re.search(r'^__version__ = [\'"]([^\'"]*)[\'"]', file.read_text(encoding='utf-8'), re.M)[1]
|
||||||
|
|
||||||
|
|
||||||
|
setup(
|
||||||
|
name='ultralytics', # name of pypi package
|
||||||
|
version=get_version(), # version of pypi package
|
||||||
|
python_requires='>=3.7',
|
||||||
|
license='GPL-3.0',
|
||||||
|
description='Ultralytics YOLOv8',
|
||||||
|
long_description=README,
|
||||||
|
long_description_content_type='text/markdown',
|
||||||
|
url='https://github.com/ultralytics/ultralytics',
|
||||||
|
project_urls={
|
||||||
|
'Bug Reports': 'https://github.com/ultralytics/ultralytics/issues',
|
||||||
|
'Funding': 'https://ultralytics.com',
|
||||||
|
'Source': 'https://github.com/ultralytics/ultralytics'},
|
||||||
|
author='Ultralytics',
|
||||||
|
author_email='hello@ultralytics.com',
|
||||||
|
packages=find_packages(), # required
|
||||||
|
include_package_data=True,
|
||||||
|
install_requires=REQUIREMENTS + PKG_REQUIREMENTS,
|
||||||
|
extras_require={
|
||||||
|
'dev': ['check-manifest', 'pytest', 'pytest-cov', 'coverage', 'mkdocs-material', 'mkdocstrings[python]'],
|
||||||
|
'export': ['coremltools>=6.0', 'onnx', 'onnxsim', 'onnxruntime', 'openvino-dev>=2022.3'],
|
||||||
|
'tf': ['onnx2tf', 'sng4onnx', 'tflite_support', 'tensorflow']},
|
||||||
|
classifiers=[
|
||||||
|
'Development Status :: 4 - Beta',
|
||||||
|
'Intended Audience :: Developers',
|
||||||
|
'Intended Audience :: Education',
|
||||||
|
'Intended Audience :: Science/Research',
|
||||||
|
'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',
|
||||||
|
'Programming Language :: Python :: 3',
|
||||||
|
'Programming Language :: Python :: 3.7',
|
||||||
|
'Programming Language :: Python :: 3.8',
|
||||||
|
'Programming Language :: Python :: 3.9',
|
||||||
|
'Programming Language :: Python :: 3.10',
|
||||||
|
'Programming Language :: Python :: 3.11',
|
||||||
|
'Topic :: Software Development',
|
||||||
|
'Topic :: Scientific/Engineering',
|
||||||
|
'Topic :: Scientific/Engineering :: Artificial Intelligence',
|
||||||
|
'Topic :: Scientific/Engineering :: Image Recognition',
|
||||||
|
'Operating System :: POSIX :: Linux',
|
||||||
|
'Operating System :: MacOS',
|
||||||
|
'Operating System :: Microsoft :: Windows', ],
|
||||||
|
keywords='machine-learning, deep-learning, vision, ML, DL, AI, YOLO, YOLOv3, YOLOv5, YOLOv8, HUB, Ultralytics',
|
||||||
|
entry_points={
|
||||||
|
'console_scripts': ['yolo = ultralytics.yolo.cfg:entrypoint', 'ultralytics = ultralytics.yolo.cfg:entrypoint']})
|
||||||
48
test_widerface.py
Normal file
@@ -0,0 +1,48 @@
|
|||||||
|
import os
|
||||||
|
import argparse
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument('--weights', nargs='+', type=str, default='runs/pose/yolov8n-face/weights/best.pt', help='model.pt path(s)')
|
||||||
|
parser.add_argument('--img-size', nargs= '+', type=int, default=640, help='inference size (pixels)')
|
||||||
|
parser.add_argument('--conf-thres', type=float, default=0.01, help='object confidence threshold')
|
||||||
|
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
|
||||||
|
parser.add_argument('--device', type=str, default='cpu', help='augmented inference')
|
||||||
|
parser.add_argument('--augment', action='store_true', help='augmented inference')
|
||||||
|
parser.add_argument('--save_folder', default='./widerface_evaluate/widerface_txt/', type=str, help='Dir to save txt results')
|
||||||
|
parser.add_argument('--dataset_folder', default='./data/widerface/val/images/', type=str, help='dataset path')
|
||||||
|
opt = parser.parse_args()
|
||||||
|
print(opt)
|
||||||
|
|
||||||
|
model = YOLO(opt.weights)
|
||||||
|
|
||||||
|
# testing dataset
|
||||||
|
testset_folder = opt.dataset_folder
|
||||||
|
testset_list = opt.dataset_folder[:-7] + "wider_val.txt"
|
||||||
|
with open(testset_list, 'r') as fr:
|
||||||
|
test_dataset = fr.read().split()
|
||||||
|
num_images = len(test_dataset)
|
||||||
|
for img_name in test_dataset:
|
||||||
|
image_path = testset_folder + img_name
|
||||||
|
results = model.predict(source=image_path, imgsz=opt.img_size, conf=opt.conf_thres, iou=opt.iou_thres, augment=opt.augment, device=opt.device)
|
||||||
|
|
||||||
|
save_name = opt.save_folder + img_name[:-4] + ".txt"
|
||||||
|
dirname = os.path.dirname(save_name)
|
||||||
|
if not os.path.isdir(dirname):
|
||||||
|
os.makedirs(dirname)
|
||||||
|
with open(save_name, "w") as fd:
|
||||||
|
result = results[0].cpu().numpy()
|
||||||
|
file_name = os.path.basename(save_name)[:-4] + "\n"
|
||||||
|
bboxs_num = str(result.boxes.shape[0]) + '\n'
|
||||||
|
fd.write(file_name)
|
||||||
|
fd.write(bboxs_num)
|
||||||
|
for box in result.boxes:
|
||||||
|
conf = box.conf[0]
|
||||||
|
cls = box.cls[0]
|
||||||
|
xyxy = box.xyxy[0]
|
||||||
|
x1 = int(xyxy[0] + 0.5)
|
||||||
|
y1 = int(xyxy[1] + 0.5)
|
||||||
|
x2 = int(xyxy[2] + 0.5)
|
||||||
|
y2 = int(xyxy[3] + 0.5)
|
||||||
|
fd.write('%d %d %d %d %.03f' % (x1, y1, x2-x1, y2-y1, conf if conf <= 1 else 1) + '\n')
|
||||||
97
tests/test_cli.py
Normal file
@@ -0,0 +1,97 @@
|
|||||||
|
# Ultralytics YOLO 🚀, GPL-3.0 license
|
||||||
|
|
||||||
|
import subprocess
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
from ultralytics.yolo.utils import LINUX, ONLINE, ROOT, SETTINGS
|
||||||
|
|
||||||
|
MODEL = Path(SETTINGS['weights_dir']) / 'yolov8n'
|
||||||
|
CFG = 'yolov8n'
|
||||||
|
|
||||||
|
|
||||||
|
def run(cmd):
|
||||||
|
# Run a subprocess command with check=True
|
||||||
|
subprocess.run(cmd.split(), check=True)
|
||||||
|
|
||||||
|
|
||||||
|
def test_special_modes():
|
||||||
|
run('yolo checks')
|
||||||
|
run('yolo settings')
|
||||||
|
run('yolo help')
|
||||||
|
|
||||||
|
|
||||||
|
# Train checks ---------------------------------------------------------------------------------------------------------
|
||||||
|
def test_train_det():
|
||||||
|
run(f'yolo train detect model={CFG}.yaml data=coco8.yaml imgsz=32 epochs=1 v5loader')
|
||||||
|
|
||||||
|
|
||||||
|
def test_train_seg():
|
||||||
|
run(f'yolo train segment model={CFG}-seg.yaml data=coco8-seg.yaml imgsz=32 epochs=1')
|
||||||
|
|
||||||
|
|
||||||
|
def test_train_cls():
|
||||||
|
run(f'yolo train classify model={CFG}-cls.yaml data=imagenet10 imgsz=32 epochs=1')
|
||||||
|
|
||||||
|
|
||||||
|
def test_train_pose():
|
||||||
|
run(f'yolo train pose model={CFG}-pose.yaml data=coco8-pose.yaml imgsz=32 epochs=1')
|
||||||
|
|
||||||
|
|
||||||
|
# Val checks -----------------------------------------------------------------------------------------------------------
|
||||||
|
def test_val_detect():
|
||||||
|
run(f'yolo val detect model={MODEL}.pt data=coco8.yaml imgsz=32')
|
||||||
|
|
||||||
|
|
||||||
|
def test_val_segment():
|
||||||
|
run(f'yolo val segment model={MODEL}-seg.pt data=coco8-seg.yaml imgsz=32')
|
||||||
|
|
||||||
|
|
||||||
|
def test_val_classify():
|
||||||
|
run(f'yolo val classify model={MODEL}-cls.pt data=imagenet10 imgsz=32')
|
||||||
|
|
||||||
|
|
||||||
|
def test_val_pose():
|
||||||
|
run(f'yolo val pose model={MODEL}-pose.pt data=coco8-pose.yaml imgsz=32')
|
||||||
|
|
||||||
|
|
||||||
|
# Predict checks -------------------------------------------------------------------------------------------------------
|
||||||
|
def test_predict_detect():
|
||||||
|
run(f"yolo predict model={MODEL}.pt source={ROOT / 'assets'} imgsz=32 save save_crop save_txt")
|
||||||
|
if ONLINE:
|
||||||
|
run(f'yolo predict model={MODEL}.pt source=https://ultralytics.com/images/bus.jpg imgsz=32')
|
||||||
|
run(f'yolo predict model={MODEL}.pt source=https://ultralytics.com/assets/decelera_landscape_min.mov imgsz=32')
|
||||||
|
run(f'yolo predict model={MODEL}.pt source=https://ultralytics.com/assets/decelera_portrait_min.mov imgsz=32')
|
||||||
|
|
||||||
|
|
||||||
|
def test_predict_segment():
|
||||||
|
run(f"yolo predict model={MODEL}-seg.pt source={ROOT / 'assets'} imgsz=32 save save_txt")
|
||||||
|
|
||||||
|
|
||||||
|
def test_predict_classify():
|
||||||
|
run(f"yolo predict model={MODEL}-cls.pt source={ROOT / 'assets'} imgsz=32 save save_txt")
|
||||||
|
|
||||||
|
|
||||||
|
def test_predict_pose():
|
||||||
|
run(f"yolo predict model={MODEL}-pose.pt source={ROOT / 'assets'} imgsz=32 save save_txt")
|
||||||
|
|
||||||
|
|
||||||
|
# Export checks --------------------------------------------------------------------------------------------------------
|
||||||
|
def test_export_detect_torchscript():
|
||||||
|
run(f'yolo export model={MODEL}.pt format=torchscript')
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_segment_torchscript():
|
||||||
|
run(f'yolo export model={MODEL}-seg.pt format=torchscript')
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_classify_torchscript():
|
||||||
|
run(f'yolo export model={MODEL}-cls.pt format=torchscript')
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_classify_pose():
|
||||||
|
run(f'yolo export model={MODEL}-pose.pt format=torchscript')
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_detect_edgetpu(enabled=False):
|
||||||
|
if enabled and LINUX:
|
||||||
|
run(f'yolo export model={MODEL}.pt format=edgetpu')
|
||||||
93
tests/test_engine.py
Normal file
@@ -0,0 +1,93 @@
|
|||||||
|
# Ultralytics YOLO 🚀, GPL-3.0 license
|
||||||
|
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
from ultralytics.yolo.cfg import get_cfg
|
||||||
|
from ultralytics.yolo.utils import DEFAULT_CFG, ROOT, SETTINGS
|
||||||
|
from ultralytics.yolo.v8 import classify, detect, segment
|
||||||
|
|
||||||
|
CFG_DET = 'yolov8n.yaml'
|
||||||
|
CFG_SEG = 'yolov8n-seg.yaml'
|
||||||
|
CFG_CLS = 'squeezenet1_0'
|
||||||
|
CFG = get_cfg(DEFAULT_CFG)
|
||||||
|
MODEL = Path(SETTINGS['weights_dir']) / 'yolov8n'
|
||||||
|
SOURCE = ROOT / 'assets'
|
||||||
|
|
||||||
|
|
||||||
|
def test_detect():
|
||||||
|
overrides = {'data': 'coco8.yaml', 'model': CFG_DET, 'imgsz': 32, 'epochs': 1, 'save': False}
|
||||||
|
CFG.data = 'coco8.yaml'
|
||||||
|
|
||||||
|
# Trainer
|
||||||
|
trainer = detect.DetectionTrainer(overrides=overrides)
|
||||||
|
trainer.train()
|
||||||
|
|
||||||
|
# Validator
|
||||||
|
val = detect.DetectionValidator(args=CFG)
|
||||||
|
val(model=trainer.best) # validate best.pt
|
||||||
|
|
||||||
|
# Predictor
|
||||||
|
pred = detect.DetectionPredictor(overrides={'imgsz': [64, 64]})
|
||||||
|
result = pred(source=SOURCE, model=f'{MODEL}.pt')
|
||||||
|
assert len(result), 'predictor test failed'
|
||||||
|
|
||||||
|
overrides['resume'] = trainer.last
|
||||||
|
trainer = detect.DetectionTrainer(overrides=overrides)
|
||||||
|
try:
|
||||||
|
trainer.train()
|
||||||
|
except Exception as e:
|
||||||
|
print(f'Expected exception caught: {e}')
|
||||||
|
return
|
||||||
|
|
||||||
|
Exception('Resume test failed!')
|
||||||
|
|
||||||
|
|
||||||
|
def test_segment():
|
||||||
|
overrides = {'data': 'coco8-seg.yaml', 'model': CFG_SEG, 'imgsz': 32, 'epochs': 1, 'save': False}
|
||||||
|
CFG.data = 'coco8-seg.yaml'
|
||||||
|
CFG.v5loader = False
|
||||||
|
# YOLO(CFG_SEG).train(**overrides) # works
|
||||||
|
|
||||||
|
# trainer
|
||||||
|
trainer = segment.SegmentationTrainer(overrides=overrides)
|
||||||
|
trainer.train()
|
||||||
|
|
||||||
|
# Validator
|
||||||
|
val = segment.SegmentationValidator(args=CFG)
|
||||||
|
val(model=trainer.best) # validate best.pt
|
||||||
|
|
||||||
|
# Predictor
|
||||||
|
pred = segment.SegmentationPredictor(overrides={'imgsz': [64, 64]})
|
||||||
|
result = pred(source=SOURCE, model=f'{MODEL}-seg.pt')
|
||||||
|
assert len(result), 'predictor test failed'
|
||||||
|
|
||||||
|
# Test resume
|
||||||
|
overrides['resume'] = trainer.last
|
||||||
|
trainer = segment.SegmentationTrainer(overrides=overrides)
|
||||||
|
try:
|
||||||
|
trainer.train()
|
||||||
|
except Exception as e:
|
||||||
|
print(f'Expected exception caught: {e}')
|
||||||
|
return
|
||||||
|
|
||||||
|
Exception('Resume test failed!')
|
||||||
|
|
||||||
|
|
||||||
|
def test_classify():
|
||||||
|
overrides = {'data': 'imagenet10', 'model': 'yolov8n-cls.yaml', 'imgsz': 32, 'epochs': 1, 'save': False}
|
||||||
|
CFG.data = 'imagenet10'
|
||||||
|
CFG.imgsz = 32
|
||||||
|
# YOLO(CFG_SEG).train(**overrides) # works
|
||||||
|
|
||||||
|
# Trainer
|
||||||
|
trainer = classify.ClassificationTrainer(overrides=overrides)
|
||||||
|
trainer.train()
|
||||||
|
|
||||||
|
# Validator
|
||||||
|
val = classify.ClassificationValidator(args=CFG)
|
||||||
|
val(model=trainer.best)
|
||||||
|
|
||||||
|
# Predictor
|
||||||
|
pred = classify.ClassificationPredictor(overrides={'imgsz': [64, 64]})
|
||||||
|
result = pred(source=SOURCE, model=trainer.best)
|
||||||
|
assert len(result), 'predictor test failed'
|
||||||
222
tests/test_python.py
Normal file
@@ -0,0 +1,222 @@
|
|||||||
|
# Ultralytics YOLO 🚀, GPL-3.0 license
|
||||||
|
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
|
from ultralytics import YOLO
|
||||||
|
from ultralytics.yolo.data.build import load_inference_source
|
||||||
|
from ultralytics.yolo.utils import LINUX, ONLINE, ROOT, SETTINGS
|
||||||
|
|
||||||
|
MODEL = Path(SETTINGS['weights_dir']) / 'yolov8n.pt'
|
||||||
|
CFG = 'yolov8n.yaml'
|
||||||
|
SOURCE = ROOT / 'assets/bus.jpg'
|
||||||
|
SOURCE_GREYSCALE = Path(f'{SOURCE.parent / SOURCE.stem}_greyscale.jpg')
|
||||||
|
SOURCE_RGBA = Path(f'{SOURCE.parent / SOURCE.stem}_4ch.png')
|
||||||
|
|
||||||
|
# Convert SOURCE to greyscale and 4-ch
|
||||||
|
im = Image.open(SOURCE)
|
||||||
|
im.convert('L').save(SOURCE_GREYSCALE) # greyscale
|
||||||
|
im.convert('RGBA').save(SOURCE_RGBA) # 4-ch PNG with alpha
|
||||||
|
|
||||||
|
|
||||||
|
def test_model_forward():
|
||||||
|
model = YOLO(CFG)
|
||||||
|
model(SOURCE)
|
||||||
|
|
||||||
|
|
||||||
|
def test_model_info():
|
||||||
|
model = YOLO(CFG)
|
||||||
|
model.info()
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
model.info(verbose=True)
|
||||||
|
|
||||||
|
|
||||||
|
def test_model_fuse():
|
||||||
|
model = YOLO(CFG)
|
||||||
|
model.fuse()
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
model.fuse()
|
||||||
|
|
||||||
|
|
||||||
|
def test_predict_dir():
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
model(source=ROOT / 'assets')
|
||||||
|
|
||||||
|
|
||||||
|
def test_predict_img():
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
seg_model = YOLO('yolov8n-seg.pt')
|
||||||
|
cls_model = YOLO('yolov8n-cls.pt')
|
||||||
|
im = cv2.imread(str(SOURCE))
|
||||||
|
assert len(model(source=Image.open(SOURCE), save=True, verbose=True)) == 1 # PIL
|
||||||
|
assert len(model(source=im, save=True, save_txt=True)) == 1 # ndarray
|
||||||
|
assert len(model(source=[im, im], save=True, save_txt=True)) == 2 # batch
|
||||||
|
assert len(list(model(source=[im, im], save=True, stream=True))) == 2 # stream
|
||||||
|
assert len(model(torch.zeros(320, 640, 3).numpy())) == 1 # tensor to numpy
|
||||||
|
batch = [
|
||||||
|
str(SOURCE), # filename
|
||||||
|
Path(SOURCE), # Path
|
||||||
|
'https://ultralytics.com/images/zidane.jpg' if ONLINE else SOURCE, # URI
|
||||||
|
cv2.imread(str(SOURCE)), # OpenCV
|
||||||
|
Image.open(SOURCE), # PIL
|
||||||
|
np.zeros((320, 640, 3))] # numpy
|
||||||
|
assert len(model(batch)) == len(batch) # multiple sources in a batch
|
||||||
|
|
||||||
|
# Test tensor inference
|
||||||
|
im = cv2.imread(str(SOURCE)) # OpenCV
|
||||||
|
t = cv2.resize(im, (32, 32))
|
||||||
|
t = torch.from_numpy(t.transpose((2, 0, 1)))
|
||||||
|
t = torch.stack([t, t, t, t])
|
||||||
|
results = model(t)
|
||||||
|
assert len(results) == t.shape[0]
|
||||||
|
results = seg_model(t)
|
||||||
|
assert len(results) == t.shape[0]
|
||||||
|
results = cls_model(t)
|
||||||
|
assert len(results) == t.shape[0]
|
||||||
|
|
||||||
|
|
||||||
|
def test_predict_grey_and_4ch():
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
for f in SOURCE_RGBA, SOURCE_GREYSCALE:
|
||||||
|
for source in Image.open(f), cv2.imread(str(f)), f:
|
||||||
|
model(source, save=True, verbose=True)
|
||||||
|
|
||||||
|
|
||||||
|
def test_val():
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
model.val(data='coco8.yaml', imgsz=32)
|
||||||
|
|
||||||
|
|
||||||
|
def test_val_scratch():
|
||||||
|
model = YOLO(CFG)
|
||||||
|
model.val(data='coco8.yaml', imgsz=32)
|
||||||
|
|
||||||
|
|
||||||
|
def test_amp():
|
||||||
|
if torch.cuda.is_available():
|
||||||
|
from ultralytics.yolo.engine.trainer import check_amp
|
||||||
|
model = YOLO(MODEL).model.cuda()
|
||||||
|
assert check_amp(model)
|
||||||
|
|
||||||
|
|
||||||
|
def test_train_scratch():
|
||||||
|
model = YOLO(CFG)
|
||||||
|
model.train(data='coco8.yaml', epochs=1, imgsz=32)
|
||||||
|
model(SOURCE)
|
||||||
|
|
||||||
|
|
||||||
|
def test_train_pretrained():
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
model.train(data='coco8.yaml', epochs=1, imgsz=32)
|
||||||
|
model(SOURCE)
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_torchscript():
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
f = model.export(format='torchscript')
|
||||||
|
YOLO(f)(SOURCE) # exported model inference
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_torchscript_scratch():
|
||||||
|
model = YOLO(CFG)
|
||||||
|
f = model.export(format='torchscript')
|
||||||
|
YOLO(f)(SOURCE) # exported model inference
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_onnx():
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
f = model.export(format='onnx')
|
||||||
|
YOLO(f)(SOURCE) # exported model inference
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_openvino():
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
f = model.export(format='openvino')
|
||||||
|
YOLO(f)(SOURCE) # exported model inference
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_coreml(): # sourcery skip: move-assign
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
model.export(format='coreml')
|
||||||
|
# if MACOS:
|
||||||
|
# YOLO(f)(SOURCE) # model prediction only supported on macOS
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_tflite(enabled=False):
|
||||||
|
# TF suffers from install conflicts on Windows and macOS
|
||||||
|
if enabled and LINUX:
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
f = model.export(format='tflite')
|
||||||
|
YOLO(f)(SOURCE)
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_pb(enabled=False):
|
||||||
|
# TF suffers from install conflicts on Windows and macOS
|
||||||
|
if enabled and LINUX:
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
f = model.export(format='pb')
|
||||||
|
YOLO(f)(SOURCE)
|
||||||
|
|
||||||
|
|
||||||
|
def test_export_paddle(enabled=False):
|
||||||
|
# Paddle protobuf requirements conflicting with onnx protobuf requirements
|
||||||
|
if enabled:
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
model.export(format='paddle')
|
||||||
|
|
||||||
|
|
||||||
|
def test_all_model_yamls():
|
||||||
|
for m in list((ROOT / 'models').rglob('*.yaml')):
|
||||||
|
YOLO(m.name)
|
||||||
|
|
||||||
|
|
||||||
|
def test_workflow():
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
model.train(data='coco8.yaml', epochs=1, imgsz=32)
|
||||||
|
model.val()
|
||||||
|
model.predict(SOURCE)
|
||||||
|
model.export(format='onnx') # export a model to ONNX format
|
||||||
|
|
||||||
|
|
||||||
|
def test_predict_callback_and_setup():
|
||||||
|
# test callback addition for prediction
|
||||||
|
def on_predict_batch_end(predictor): # results -> List[batch_size]
|
||||||
|
path, _, im0s, _, _ = predictor.batch
|
||||||
|
# print('on_predict_batch_end', im0s[0].shape)
|
||||||
|
im0s = im0s if isinstance(im0s, list) else [im0s]
|
||||||
|
bs = [predictor.dataset.bs for _ in range(len(path))]
|
||||||
|
predictor.results = zip(predictor.results, im0s, bs)
|
||||||
|
|
||||||
|
model = YOLO(MODEL)
|
||||||
|
model.add_callback('on_predict_batch_end', on_predict_batch_end)
|
||||||
|
|
||||||
|
dataset = load_inference_source(source=SOURCE, transforms=model.transforms)
|
||||||
|
bs = dataset.bs # noqa access predictor properties
|
||||||
|
results = model.predict(dataset, stream=True) # source already setup
|
||||||
|
for _, (result, im0, bs) in enumerate(results):
|
||||||
|
print('test_callback', im0.shape)
|
||||||
|
print('test_callback', bs)
|
||||||
|
boxes = result.boxes # Boxes object for bbox outputs
|
||||||
|
print(boxes)
|
||||||
|
|
||||||
|
|
||||||
|
def test_result():
|
||||||
|
model = YOLO('yolov8n-seg.pt')
|
||||||
|
res = model([SOURCE, SOURCE])
|
||||||
|
res[0].plot(show_conf=False) # raises warning
|
||||||
|
res[0].plot(conf=True, boxes=False, masks=True)
|
||||||
|
res[0] = res[0].cpu().numpy()
|
||||||
|
print(res[0].path, res[0].masks.masks)
|
||||||
|
model = YOLO('yolov8n.pt')
|
||||||
|
res = model(SOURCE)
|
||||||
|
res[0].plot()
|
||||||
|
print(res[0].path)
|
||||||
|
|
||||||
|
model = YOLO('yolov8n-cls.pt')
|
||||||
|
res = model(SOURCE)
|
||||||
|
res[0].plot(probs=False)
|
||||||
|
print(res[0].path)
|
||||||
10
train.py
Normal file
@@ -0,0 +1,10 @@
|
|||||||
|
import os
|
||||||
|
# os.environ["OMP_NUM_THREADS"]='2'
|
||||||
|
|
||||||
|
from ultralytics import YOLO
|
||||||
|
# Load a model
|
||||||
|
model = YOLO('ultralytics/models/v8/yolov8-lite-t-pose.yaml') # build a new model from YAML
|
||||||
|
model = YOLO('yolov8-lite-t.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
|
# Train the model
|
||||||
|
model.train(data='yolov8-plate.yaml', epochs=100, imgsz=320, batch=16, device=[0])
|
||||||
14
ultralytics/__init__.py
Normal file
@@ -0,0 +1,14 @@
|
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
|
||||||
|
__version__ = '8.0.134'
|
||||||
|
|
||||||
|
from ultralytics.hub import start
|
||||||
|
from ultralytics.vit.rtdetr import RTDETR
|
||||||
|
from ultralytics.vit.sam import SAM
|
||||||
|
from ultralytics.yolo.engine.model import YOLO
|
||||||
|
from ultralytics.yolo.fastsam import FastSAM
|
||||||
|
from ultralytics.yolo.nas import NAS
|
||||||
|
from ultralytics.yolo.utils.checks import check_yolo as checks
|
||||||
|
from ultralytics.yolo.utils.downloads import download
|
||||||
|
|
||||||
|
__all__ = '__version__', 'YOLO', 'NAS', 'SAM', 'FastSAM', 'RTDETR', 'checks', 'download', 'start' # allow simpler import
|
||||||
BIN
ultralytics/assets/bus.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 134 KiB |
BIN
ultralytics/assets/zidane.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 49 KiB |
73
ultralytics/datasets/Argoverse.yaml
Normal file
@@ -0,0 +1,73 @@
|
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
# Argoverse-HD dataset (ring-front-center camera) http://www.cs.cmu.edu/~mengtial/proj/streaming/ by Argo AI
|
||||||
|
# Example usage: yolo train data=Argoverse.yaml
|
||||||
|
# parent
|
||||||
|
# ├── ultralytics
|
||||||
|
# └── datasets
|
||||||
|
# └── Argoverse ← downloads here (31.3 GB)
|
||||||
|
|
||||||
|
|
||||||
|
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||||
|
path: ../datasets/Argoverse # dataset root dir
|
||||||
|
train: Argoverse-1.1/images/train/ # train images (relative to 'path') 39384 images
|
||||||
|
val: Argoverse-1.1/images/val/ # val images (relative to 'path') 15062 images
|
||||||
|
test: Argoverse-1.1/images/test/ # test images (optional) https://eval.ai/web/challenges/challenge-page/800/overview
|
||||||
|
|
||||||
|
# Classes
|
||||||
|
names:
|
||||||
|
0: person
|
||||||
|
1: bicycle
|
||||||
|
2: car
|
||||||
|
3: motorcycle
|
||||||
|
4: bus
|
||||||
|
5: truck
|
||||||
|
6: traffic_light
|
||||||
|
7: stop_sign
|
||||||
|
|
||||||
|
|
||||||
|
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
||||||
|
download: |
|
||||||
|
import json
|
||||||
|
from tqdm import tqdm
|
||||||
|
from ultralytics.yolo.utils.downloads import download
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
def argoverse2yolo(set):
|
||||||
|
labels = {}
|
||||||
|
a = json.load(open(set, "rb"))
|
||||||
|
for annot in tqdm(a['annotations'], desc=f"Converting {set} to YOLOv5 format..."):
|
||||||
|
img_id = annot['image_id']
|
||||||
|
img_name = a['images'][img_id]['name']
|
||||||
|
img_label_name = f'{img_name[:-3]}txt'
|
||||||
|
|
||||||
|
cls = annot['category_id'] # instance class id
|
||||||
|
x_center, y_center, width, height = annot['bbox']
|
||||||
|
x_center = (x_center + width / 2) / 1920.0 # offset and scale
|
||||||
|
y_center = (y_center + height / 2) / 1200.0 # offset and scale
|
||||||
|
width /= 1920.0 # scale
|
||||||
|
height /= 1200.0 # scale
|
||||||
|
|
||||||
|
img_dir = set.parents[2] / 'Argoverse-1.1' / 'labels' / a['seq_dirs'][a['images'][annot['image_id']]['sid']]
|
||||||
|
if not img_dir.exists():
|
||||||
|
img_dir.mkdir(parents=True, exist_ok=True)
|
||||||
|
|
||||||
|
k = str(img_dir / img_label_name)
|
||||||
|
if k not in labels:
|
||||||
|
labels[k] = []
|
||||||
|
labels[k].append(f"{cls} {x_center} {y_center} {width} {height}\n")
|
||||||
|
|
||||||
|
for k in labels:
|
||||||
|
with open(k, "w") as f:
|
||||||
|
f.writelines(labels[k])
|
||||||
|
|
||||||
|
|
||||||
|
# Download
|
||||||
|
dir = Path(yaml['path']) # dataset root dir
|
||||||
|
urls = ['https://argoverse-hd.s3.us-east-2.amazonaws.com/Argoverse-HD-Full.zip']
|
||||||
|
download(urls, dir=dir)
|
||||||
|
|
||||||
|
# Convert
|
||||||
|
annotations_dir = 'Argoverse-HD/annotations/'
|
||||||
|
(dir / 'Argoverse-1.1' / 'tracking').rename(dir / 'Argoverse-1.1' / 'images') # rename 'tracking' to 'images'
|
||||||
|
for d in "train.json", "val.json":
|
||||||
|
argoverse2yolo(dir / annotations_dir / d) # convert VisDrone annotations to YOLO labels
|
||||||
54
ultralytics/datasets/GlobalWheat2020.yaml
Normal file
@@ -0,0 +1,54 @@
|
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
# Global Wheat 2020 dataset http://www.global-wheat.com/ by University of Saskatchewan
|
||||||
|
# Example usage: yolo train data=GlobalWheat2020.yaml
|
||||||
|
# parent
|
||||||
|
# ├── ultralytics
|
||||||
|
# └── datasets
|
||||||
|
# └── GlobalWheat2020 ← downloads here (7.0 GB)
|
||||||
|
|
||||||
|
|
||||||
|
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||||
|
path: ../datasets/GlobalWheat2020 # dataset root dir
|
||||||
|
train: # train images (relative to 'path') 3422 images
|
||||||
|
- images/arvalis_1
|
||||||
|
- images/arvalis_2
|
||||||
|
- images/arvalis_3
|
||||||
|
- images/ethz_1
|
||||||
|
- images/rres_1
|
||||||
|
- images/inrae_1
|
||||||
|
- images/usask_1
|
||||||
|
val: # val images (relative to 'path') 748 images (WARNING: train set contains ethz_1)
|
||||||
|
- images/ethz_1
|
||||||
|
test: # test images (optional) 1276 images
|
||||||
|
- images/utokyo_1
|
||||||
|
- images/utokyo_2
|
||||||
|
- images/nau_1
|
||||||
|
- images/uq_1
|
||||||
|
|
||||||
|
# Classes
|
||||||
|
names:
|
||||||
|
0: wheat_head
|
||||||
|
|
||||||
|
|
||||||
|
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
||||||
|
download: |
|
||||||
|
from ultralytics.yolo.utils.downloads import download
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
# Download
|
||||||
|
dir = Path(yaml['path']) # dataset root dir
|
||||||
|
urls = ['https://zenodo.org/record/4298502/files/global-wheat-codalab-official.zip',
|
||||||
|
'https://github.com/ultralytics/yolov5/releases/download/v1.0/GlobalWheat2020_labels.zip']
|
||||||
|
download(urls, dir=dir)
|
||||||
|
|
||||||
|
# Make Directories
|
||||||
|
for p in 'annotations', 'images', 'labels':
|
||||||
|
(dir / p).mkdir(parents=True, exist_ok=True)
|
||||||
|
|
||||||
|
# Move
|
||||||
|
for p in 'arvalis_1', 'arvalis_2', 'arvalis_3', 'ethz_1', 'rres_1', 'inrae_1', 'usask_1', \
|
||||||
|
'utokyo_1', 'utokyo_2', 'nau_1', 'uq_1':
|
||||||
|
(dir / p).rename(dir / 'images' / p) # move to /images
|
||||||
|
f = (dir / p).with_suffix('.json') # json file
|
||||||
|
if f.exists():
|
||||||
|
f.rename((dir / 'annotations' / p).with_suffix('.json')) # move to /annotations
|
||||||
2025
ultralytics/datasets/ImageNet.yaml
Normal file
443
ultralytics/datasets/Objects365.yaml
Normal file
@@ -0,0 +1,443 @@
|
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
# Objects365 dataset https://www.objects365.org/ by Megvii
|
||||||
|
# Example usage: yolo train data=Objects365.yaml
|
||||||
|
# parent
|
||||||
|
# ├── ultralytics
|
||||||
|
# └── datasets
|
||||||
|
# └── Objects365 ← downloads here (712 GB = 367G data + 345G zips)
|
||||||
|
|
||||||
|
|
||||||
|
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||||
|
path: ../datasets/Objects365 # dataset root dir
|
||||||
|
train: images/train # train images (relative to 'path') 1742289 images
|
||||||
|
val: images/val # val images (relative to 'path') 80000 images
|
||||||
|
test: # test images (optional)
|
||||||
|
|
||||||
|
# Classes
|
||||||
|
names:
|
||||||
|
0: Person
|
||||||
|
1: Sneakers
|
||||||
|
2: Chair
|
||||||
|
3: Other Shoes
|
||||||
|
4: Hat
|
||||||
|
5: Car
|
||||||
|
6: Lamp
|
||||||
|
7: Glasses
|
||||||
|
8: Bottle
|
||||||
|
9: Desk
|
||||||
|
10: Cup
|
||||||
|
11: Street Lights
|
||||||
|
12: Cabinet/shelf
|
||||||
|
13: Handbag/Satchel
|
||||||
|
14: Bracelet
|
||||||
|
15: Plate
|
||||||
|
16: Picture/Frame
|
||||||
|
17: Helmet
|
||||||
|
18: Book
|
||||||
|
19: Gloves
|
||||||
|
20: Storage box
|
||||||
|
21: Boat
|
||||||
|
22: Leather Shoes
|
||||||
|
23: Flower
|
||||||
|
24: Bench
|
||||||
|
25: Potted Plant
|
||||||
|
26: Bowl/Basin
|
||||||
|
27: Flag
|
||||||
|
28: Pillow
|
||||||
|
29: Boots
|
||||||
|
30: Vase
|
||||||
|
31: Microphone
|
||||||
|
32: Necklace
|
||||||
|
33: Ring
|
||||||
|
34: SUV
|
||||||
|
35: Wine Glass
|
||||||
|
36: Belt
|
||||||
|
37: Monitor/TV
|
||||||
|
38: Backpack
|
||||||
|
39: Umbrella
|
||||||
|
40: Traffic Light
|
||||||
|
41: Speaker
|
||||||
|
42: Watch
|
||||||
|
43: Tie
|
||||||
|
44: Trash bin Can
|
||||||
|
45: Slippers
|
||||||
|
46: Bicycle
|
||||||
|
47: Stool
|
||||||
|
48: Barrel/bucket
|
||||||
|
49: Van
|
||||||
|
50: Couch
|
||||||
|
51: Sandals
|
||||||
|
52: Basket
|
||||||
|
53: Drum
|
||||||
|
54: Pen/Pencil
|
||||||
|
55: Bus
|
||||||
|
56: Wild Bird
|
||||||
|
57: High Heels
|
||||||
|
58: Motorcycle
|
||||||
|
59: Guitar
|
||||||
|
60: Carpet
|
||||||
|
61: Cell Phone
|
||||||
|
62: Bread
|
||||||
|
63: Camera
|
||||||
|
64: Canned
|
||||||
|
65: Truck
|
||||||
|
66: Traffic cone
|
||||||
|
67: Cymbal
|
||||||
|
68: Lifesaver
|
||||||
|
69: Towel
|
||||||
|
70: Stuffed Toy
|
||||||
|
71: Candle
|
||||||
|
72: Sailboat
|
||||||
|
73: Laptop
|
||||||
|
74: Awning
|
||||||
|
75: Bed
|
||||||
|
76: Faucet
|
||||||
|
77: Tent
|
||||||
|
78: Horse
|
||||||
|
79: Mirror
|
||||||
|
80: Power outlet
|
||||||
|
81: Sink
|
||||||
|
82: Apple
|
||||||
|
83: Air Conditioner
|
||||||
|
84: Knife
|
||||||
|
85: Hockey Stick
|
||||||
|
86: Paddle
|
||||||
|
87: Pickup Truck
|
||||||
|
88: Fork
|
||||||
|
89: Traffic Sign
|
||||||
|
90: Balloon
|
||||||
|
91: Tripod
|
||||||
|
92: Dog
|
||||||
|
93: Spoon
|
||||||
|
94: Clock
|
||||||
|
95: Pot
|
||||||
|
96: Cow
|
||||||
|
97: Cake
|
||||||
|
98: Dinning Table
|
||||||
|
99: Sheep
|
||||||
|
100: Hanger
|
||||||
|
101: Blackboard/Whiteboard
|
||||||
|
102: Napkin
|
||||||
|
103: Other Fish
|
||||||
|
104: Orange/Tangerine
|
||||||
|
105: Toiletry
|
||||||
|
106: Keyboard
|
||||||
|
107: Tomato
|
||||||
|
108: Lantern
|
||||||
|
109: Machinery Vehicle
|
||||||
|
110: Fan
|
||||||
|
111: Green Vegetables
|
||||||
|
112: Banana
|
||||||
|
113: Baseball Glove
|
||||||
|
114: Airplane
|
||||||
|
115: Mouse
|
||||||
|
116: Train
|
||||||
|
117: Pumpkin
|
||||||
|
118: Soccer
|
||||||
|
119: Skiboard
|
||||||
|
120: Luggage
|
||||||
|
121: Nightstand
|
||||||
|
122: Tea pot
|
||||||
|
123: Telephone
|
||||||
|
124: Trolley
|
||||||
|
125: Head Phone
|
||||||
|
126: Sports Car
|
||||||
|
127: Stop Sign
|
||||||
|
128: Dessert
|
||||||
|
129: Scooter
|
||||||
|
130: Stroller
|
||||||
|
131: Crane
|
||||||
|
132: Remote
|
||||||
|
133: Refrigerator
|
||||||
|
134: Oven
|
||||||
|
135: Lemon
|
||||||
|
136: Duck
|
||||||
|
137: Baseball Bat
|
||||||
|
138: Surveillance Camera
|
||||||
|
139: Cat
|
||||||
|
140: Jug
|
||||||
|
141: Broccoli
|
||||||
|
142: Piano
|
||||||
|
143: Pizza
|
||||||
|
144: Elephant
|
||||||
|
145: Skateboard
|
||||||
|
146: Surfboard
|
||||||
|
147: Gun
|
||||||
|
148: Skating and Skiing shoes
|
||||||
|
149: Gas stove
|
||||||
|
150: Donut
|
||||||
|
151: Bow Tie
|
||||||
|
152: Carrot
|
||||||
|
153: Toilet
|
||||||
|
154: Kite
|
||||||
|
155: Strawberry
|
||||||
|
156: Other Balls
|
||||||
|
157: Shovel
|
||||||
|
158: Pepper
|
||||||
|
159: Computer Box
|
||||||
|
160: Toilet Paper
|
||||||
|
161: Cleaning Products
|
||||||
|
162: Chopsticks
|
||||||
|
163: Microwave
|
||||||
|
164: Pigeon
|
||||||
|
165: Baseball
|
||||||
|
166: Cutting/chopping Board
|
||||||
|
167: Coffee Table
|
||||||
|
168: Side Table
|
||||||
|
169: Scissors
|
||||||
|
170: Marker
|
||||||
|
171: Pie
|
||||||
|
172: Ladder
|
||||||
|
173: Snowboard
|
||||||
|
174: Cookies
|
||||||
|
175: Radiator
|
||||||
|
176: Fire Hydrant
|
||||||
|
177: Basketball
|
||||||
|
178: Zebra
|
||||||
|
179: Grape
|
||||||
|
180: Giraffe
|
||||||
|
181: Potato
|
||||||
|
182: Sausage
|
||||||
|
183: Tricycle
|
||||||
|
184: Violin
|
||||||
|
185: Egg
|
||||||
|
186: Fire Extinguisher
|
||||||
|
187: Candy
|
||||||
|
188: Fire Truck
|
||||||
|
189: Billiards
|
||||||
|
190: Converter
|
||||||
|
191: Bathtub
|
||||||
|
192: Wheelchair
|
||||||
|
193: Golf Club
|
||||||
|
194: Briefcase
|
||||||
|
195: Cucumber
|
||||||
|
196: Cigar/Cigarette
|
||||||
|
197: Paint Brush
|
||||||
|
198: Pear
|
||||||
|
199: Heavy Truck
|
||||||
|
200: Hamburger
|
||||||
|
201: Extractor
|
||||||
|
202: Extension Cord
|
||||||
|
203: Tong
|
||||||
|
204: Tennis Racket
|
||||||
|
205: Folder
|
||||||
|
206: American Football
|
||||||
|
207: earphone
|
||||||
|
208: Mask
|
||||||
|
209: Kettle
|
||||||
|
210: Tennis
|
||||||
|
211: Ship
|
||||||
|
212: Swing
|
||||||
|
213: Coffee Machine
|
||||||
|
214: Slide
|
||||||
|
215: Carriage
|
||||||
|
216: Onion
|
||||||
|
217: Green beans
|
||||||
|
218: Projector
|
||||||
|
219: Frisbee
|
||||||
|
220: Washing Machine/Drying Machine
|
||||||
|
221: Chicken
|
||||||
|
222: Printer
|
||||||
|
223: Watermelon
|
||||||
|
224: Saxophone
|
||||||
|
225: Tissue
|
||||||
|
226: Toothbrush
|
||||||
|
227: Ice cream
|
||||||
|
228: Hot-air balloon
|
||||||
|
229: Cello
|
||||||
|
230: French Fries
|
||||||
|
231: Scale
|
||||||
|
232: Trophy
|
||||||
|
233: Cabbage
|
||||||
|
234: Hot dog
|
||||||
|
235: Blender
|
||||||
|
236: Peach
|
||||||
|
237: Rice
|
||||||
|
238: Wallet/Purse
|
||||||
|
239: Volleyball
|
||||||
|
240: Deer
|
||||||
|
241: Goose
|
||||||
|
242: Tape
|
||||||
|
243: Tablet
|
||||||
|
244: Cosmetics
|
||||||
|
245: Trumpet
|
||||||
|
246: Pineapple
|
||||||
|
247: Golf Ball
|
||||||
|
248: Ambulance
|
||||||
|
249: Parking meter
|
||||||
|
250: Mango
|
||||||
|
251: Key
|
||||||
|
252: Hurdle
|
||||||
|
253: Fishing Rod
|
||||||
|
254: Medal
|
||||||
|
255: Flute
|
||||||
|
256: Brush
|
||||||
|
257: Penguin
|
||||||
|
258: Megaphone
|
||||||
|
259: Corn
|
||||||
|
260: Lettuce
|
||||||
|
261: Garlic
|
||||||
|
262: Swan
|
||||||
|
263: Helicopter
|
||||||
|
264: Green Onion
|
||||||
|
265: Sandwich
|
||||||
|
266: Nuts
|
||||||
|
267: Speed Limit Sign
|
||||||
|
268: Induction Cooker
|
||||||
|
269: Broom
|
||||||
|
270: Trombone
|
||||||
|
271: Plum
|
||||||
|
272: Rickshaw
|
||||||
|
273: Goldfish
|
||||||
|
274: Kiwi fruit
|
||||||
|
275: Router/modem
|
||||||
|
276: Poker Card
|
||||||
|
277: Toaster
|
||||||
|
278: Shrimp
|
||||||
|
279: Sushi
|
||||||
|
280: Cheese
|
||||||
|
281: Notepaper
|
||||||
|
282: Cherry
|
||||||
|
283: Pliers
|
||||||
|
284: CD
|
||||||
|
285: Pasta
|
||||||
|
286: Hammer
|
||||||
|
287: Cue
|
||||||
|
288: Avocado
|
||||||
|
289: Hamimelon
|
||||||
|
290: Flask
|
||||||
|
291: Mushroom
|
||||||
|
292: Screwdriver
|
||||||
|
293: Soap
|
||||||
|
294: Recorder
|
||||||
|
295: Bear
|
||||||
|
296: Eggplant
|
||||||
|
297: Board Eraser
|
||||||
|
298: Coconut
|
||||||
|
299: Tape Measure/Ruler
|
||||||
|
300: Pig
|
||||||
|
301: Showerhead
|
||||||
|
302: Globe
|
||||||
|
303: Chips
|
||||||
|
304: Steak
|
||||||
|
305: Crosswalk Sign
|
||||||
|
306: Stapler
|
||||||
|
307: Camel
|
||||||
|
308: Formula 1
|
||||||
|
309: Pomegranate
|
||||||
|
310: Dishwasher
|
||||||
|
311: Crab
|
||||||
|
312: Hoverboard
|
||||||
|
313: Meat ball
|
||||||
|
314: Rice Cooker
|
||||||
|
315: Tuba
|
||||||
|
316: Calculator
|
||||||
|
317: Papaya
|
||||||
|
318: Antelope
|
||||||
|
319: Parrot
|
||||||
|
320: Seal
|
||||||
|
321: Butterfly
|
||||||
|
322: Dumbbell
|
||||||
|
323: Donkey
|
||||||
|
324: Lion
|
||||||
|
325: Urinal
|
||||||
|
326: Dolphin
|
||||||
|
327: Electric Drill
|
||||||
|
328: Hair Dryer
|
||||||
|
329: Egg tart
|
||||||
|
330: Jellyfish
|
||||||
|
331: Treadmill
|
||||||
|
332: Lighter
|
||||||
|
333: Grapefruit
|
||||||
|
334: Game board
|
||||||
|
335: Mop
|
||||||
|
336: Radish
|
||||||
|
337: Baozi
|
||||||
|
338: Target
|
||||||
|
339: French
|
||||||
|
340: Spring Rolls
|
||||||
|
341: Monkey
|
||||||
|
342: Rabbit
|
||||||
|
343: Pencil Case
|
||||||
|
344: Yak
|
||||||
|
345: Red Cabbage
|
||||||
|
346: Binoculars
|
||||||
|
347: Asparagus
|
||||||
|
348: Barbell
|
||||||
|
349: Scallop
|
||||||
|
350: Noddles
|
||||||
|
351: Comb
|
||||||
|
352: Dumpling
|
||||||
|
353: Oyster
|
||||||
|
354: Table Tennis paddle
|
||||||
|
355: Cosmetics Brush/Eyeliner Pencil
|
||||||
|
356: Chainsaw
|
||||||
|
357: Eraser
|
||||||
|
358: Lobster
|
||||||
|
359: Durian
|
||||||
|
360: Okra
|
||||||
|
361: Lipstick
|
||||||
|
362: Cosmetics Mirror
|
||||||
|
363: Curling
|
||||||
|
364: Table Tennis
|
||||||
|
|
||||||
|
|
||||||
|
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
||||||
|
download: |
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from ultralytics.yolo.utils.checks import check_requirements
|
||||||
|
from ultralytics.yolo.utils.downloads import download
|
||||||
|
from ultralytics.yolo.utils.ops import xyxy2xywhn
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
check_requirements(('pycocotools>=2.0',))
|
||||||
|
from pycocotools.coco import COCO
|
||||||
|
|
||||||
|
# Make Directories
|
||||||
|
dir = Path(yaml['path']) # dataset root dir
|
||||||
|
for p in 'images', 'labels':
|
||||||
|
(dir / p).mkdir(parents=True, exist_ok=True)
|
||||||
|
for q in 'train', 'val':
|
||||||
|
(dir / p / q).mkdir(parents=True, exist_ok=True)
|
||||||
|
|
||||||
|
# Train, Val Splits
|
||||||
|
for split, patches in [('train', 50 + 1), ('val', 43 + 1)]:
|
||||||
|
print(f"Processing {split} in {patches} patches ...")
|
||||||
|
images, labels = dir / 'images' / split, dir / 'labels' / split
|
||||||
|
|
||||||
|
# Download
|
||||||
|
url = f"https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/{split}/"
|
||||||
|
if split == 'train':
|
||||||
|
download([f'{url}zhiyuan_objv2_{split}.tar.gz'], dir=dir) # annotations json
|
||||||
|
download([f'{url}patch{i}.tar.gz' for i in range(patches)], dir=images, curl=True, threads=8)
|
||||||
|
elif split == 'val':
|
||||||
|
download([f'{url}zhiyuan_objv2_{split}.json'], dir=dir) # annotations json
|
||||||
|
download([f'{url}images/v1/patch{i}.tar.gz' for i in range(15 + 1)], dir=images, curl=True, threads=8)
|
||||||
|
download([f'{url}images/v2/patch{i}.tar.gz' for i in range(16, patches)], dir=images, curl=True, threads=8)
|
||||||
|
|
||||||
|
# Move
|
||||||
|
for f in tqdm(images.rglob('*.jpg'), desc=f'Moving {split} images'):
|
||||||
|
f.rename(images / f.name) # move to /images/{split}
|
||||||
|
|
||||||
|
# Labels
|
||||||
|
coco = COCO(dir / f'zhiyuan_objv2_{split}.json')
|
||||||
|
names = [x["name"] for x in coco.loadCats(coco.getCatIds())]
|
||||||
|
for cid, cat in enumerate(names):
|
||||||
|
catIds = coco.getCatIds(catNms=[cat])
|
||||||
|
imgIds = coco.getImgIds(catIds=catIds)
|
||||||
|
for im in tqdm(coco.loadImgs(imgIds), desc=f'Class {cid + 1}/{len(names)} {cat}'):
|
||||||
|
width, height = im["width"], im["height"]
|
||||||
|
path = Path(im["file_name"]) # image filename
|
||||||
|
try:
|
||||||
|
with open(labels / path.with_suffix('.txt').name, 'a') as file:
|
||||||
|
annIds = coco.getAnnIds(imgIds=im["id"], catIds=catIds, iscrowd=None)
|
||||||
|
for a in coco.loadAnns(annIds):
|
||||||
|
x, y, w, h = a['bbox'] # bounding box in xywh (xy top-left corner)
|
||||||
|
xyxy = np.array([x, y, x + w, y + h])[None] # pixels(1,4)
|
||||||
|
x, y, w, h = xyxy2xywhn(xyxy, w=width, h=height, clip=True)[0] # normalized and clipped
|
||||||
|
file.write(f"{cid} {x:.5f} {y:.5f} {w:.5f} {h:.5f}\n")
|
||||||
|
except Exception as e:
|
||||||
|
print(e)
|
||||||
58
ultralytics/datasets/SKU-110K.yaml
Normal file
@@ -0,0 +1,58 @@
|
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
# SKU-110K retail items dataset https://github.com/eg4000/SKU110K_CVPR19 by Trax Retail
|
||||||
|
# Example usage: yolo train data=SKU-110K.yaml
|
||||||
|
# parent
|
||||||
|
# ├── ultralytics
|
||||||
|
# └── datasets
|
||||||
|
# └── SKU-110K ← downloads here (13.6 GB)
|
||||||
|
|
||||||
|
|
||||||
|
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||||
|
path: ../datasets/SKU-110K # dataset root dir
|
||||||
|
train: train.txt # train images (relative to 'path') 8219 images
|
||||||
|
val: val.txt # val images (relative to 'path') 588 images
|
||||||
|
test: test.txt # test images (optional) 2936 images
|
||||||
|
|
||||||
|
# Classes
|
||||||
|
names:
|
||||||
|
0: object
|
||||||
|
|
||||||
|
|
||||||
|
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
||||||
|
download: |
|
||||||
|
import shutil
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import pandas as pd
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from ultralytics.yolo.utils.downloads import download
|
||||||
|
from ultralytics.yolo.utils.ops import xyxy2xywh
|
||||||
|
|
||||||
|
# Download
|
||||||
|
dir = Path(yaml['path']) # dataset root dir
|
||||||
|
parent = Path(dir.parent) # download dir
|
||||||
|
urls = ['http://trax-geometry.s3.amazonaws.com/cvpr_challenge/SKU110K_fixed.tar.gz']
|
||||||
|
download(urls, dir=parent)
|
||||||
|
|
||||||
|
# Rename directories
|
||||||
|
if dir.exists():
|
||||||
|
shutil.rmtree(dir)
|
||||||
|
(parent / 'SKU110K_fixed').rename(dir) # rename dir
|
||||||
|
(dir / 'labels').mkdir(parents=True, exist_ok=True) # create labels dir
|
||||||
|
|
||||||
|
# Convert labels
|
||||||
|
names = 'image', 'x1', 'y1', 'x2', 'y2', 'class', 'image_width', 'image_height' # column names
|
||||||
|
for d in 'annotations_train.csv', 'annotations_val.csv', 'annotations_test.csv':
|
||||||
|
x = pd.read_csv(dir / 'annotations' / d, names=names).values # annotations
|
||||||
|
images, unique_images = x[:, 0], np.unique(x[:, 0])
|
||||||
|
with open((dir / d).with_suffix('.txt').__str__().replace('annotations_', ''), 'w') as f:
|
||||||
|
f.writelines(f'./images/{s}\n' for s in unique_images)
|
||||||
|
for im in tqdm(unique_images, desc=f'Converting {dir / d}'):
|
||||||
|
cls = 0 # single-class dataset
|
||||||
|
with open((dir / 'labels' / im).with_suffix('.txt'), 'a') as f:
|
||||||
|
for r in x[images == im]:
|
||||||
|
w, h = r[6], r[7] # image width, height
|
||||||
|
xywh = xyxy2xywh(np.array([[r[1] / w, r[2] / h, r[3] / w, r[4] / h]]))[0] # instance
|
||||||
|
f.write(f"{cls} {xywh[0]:.5f} {xywh[1]:.5f} {xywh[2]:.5f} {xywh[3]:.5f}\n") # write label
|
||||||
100
ultralytics/datasets/VOC.yaml
Normal file
@@ -0,0 +1,100 @@
|
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
|
||||||
|
# Example usage: yolo train data=VOC.yaml
|
||||||
|
# parent
|
||||||
|
# ├── ultralytics
|
||||||
|
# └── datasets
|
||||||
|
# └── VOC ← downloads here (2.8 GB)
|
||||||
|
|
||||||
|
|
||||||
|
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||||
|
path: /ssd2t/derron/datasets/VOC
|
||||||
|
train: # train images (relative to 'path') 16551 images
|
||||||
|
- images/train2012
|
||||||
|
- images/train2007
|
||||||
|
- images/val2012
|
||||||
|
- images/val2007
|
||||||
|
val: # val images (relative to 'path') 4952 images
|
||||||
|
- images/test2007
|
||||||
|
test: # test images (optional)
|
||||||
|
- images/test2007
|
||||||
|
|
||||||
|
# Classes
|
||||||
|
names:
|
||||||
|
0: aeroplane
|
||||||
|
1: bicycle
|
||||||
|
2: bird
|
||||||
|
3: boat
|
||||||
|
4: bottle
|
||||||
|
5: bus
|
||||||
|
6: car
|
||||||
|
7: cat
|
||||||
|
8: chair
|
||||||
|
9: cow
|
||||||
|
10: diningtable
|
||||||
|
11: dog
|
||||||
|
12: horse
|
||||||
|
13: motorbike
|
||||||
|
14: person
|
||||||
|
15: pottedplant
|
||||||
|
16: sheep
|
||||||
|
17: sofa
|
||||||
|
18: train
|
||||||
|
19: tvmonitor
|
||||||
|
|
||||||
|
|
||||||
|
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
||||||
|
download: |
|
||||||
|
import xml.etree.ElementTree as ET
|
||||||
|
|
||||||
|
from tqdm import tqdm
|
||||||
|
from ultralytics.yolo.utils.downloads import download
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
def convert_label(path, lb_path, year, image_id):
|
||||||
|
def convert_box(size, box):
|
||||||
|
dw, dh = 1. / size[0], 1. / size[1]
|
||||||
|
x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
|
||||||
|
return x * dw, y * dh, w * dw, h * dh
|
||||||
|
|
||||||
|
in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
|
||||||
|
out_file = open(lb_path, 'w')
|
||||||
|
tree = ET.parse(in_file)
|
||||||
|
root = tree.getroot()
|
||||||
|
size = root.find('size')
|
||||||
|
w = int(size.find('width').text)
|
||||||
|
h = int(size.find('height').text)
|
||||||
|
|
||||||
|
names = list(yaml['names'].values()) # names list
|
||||||
|
for obj in root.iter('object'):
|
||||||
|
cls = obj.find('name').text
|
||||||
|
if cls in names and int(obj.find('difficult').text) != 1:
|
||||||
|
xmlbox = obj.find('bndbox')
|
||||||
|
bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
|
||||||
|
cls_id = names.index(cls) # class id
|
||||||
|
out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')
|
||||||
|
|
||||||
|
|
||||||
|
# Download
|
||||||
|
dir = Path(yaml['path']) # dataset root dir
|
||||||
|
url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
|
||||||
|
urls = [f'{url}VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
|
||||||
|
f'{url}VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
|
||||||
|
f'{url}VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
|
||||||
|
download(urls, dir=dir / 'images', curl=True, threads=3)
|
||||||
|
|
||||||
|
# Convert
|
||||||
|
path = dir / 'images/VOCdevkit'
|
||||||
|
for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
|
||||||
|
imgs_path = dir / 'images' / f'{image_set}{year}'
|
||||||
|
lbs_path = dir / 'labels' / f'{image_set}{year}'
|
||||||
|
imgs_path.mkdir(exist_ok=True, parents=True)
|
||||||
|
lbs_path.mkdir(exist_ok=True, parents=True)
|
||||||
|
|
||||||
|
with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
|
||||||
|
image_ids = f.read().strip().split()
|
||||||
|
for id in tqdm(image_ids, desc=f'{image_set}{year}'):
|
||||||
|
f = path / f'VOC{year}/JPEGImages/{id}.jpg' # old img path
|
||||||
|
lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
|
||||||
|
f.rename(imgs_path / f.name) # move image
|
||||||
|
convert_label(path, lb_path, year, id) # convert labels to YOLO format
|
||||||
73
ultralytics/datasets/VisDrone.yaml
Normal file
@@ -0,0 +1,73 @@
|
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
# VisDrone2019-DET dataset https://github.com/VisDrone/VisDrone-Dataset by Tianjin University
|
||||||
|
# Example usage: yolo train data=VisDrone.yaml
|
||||||
|
# parent
|
||||||
|
# ├── ultralytics
|
||||||
|
# └── datasets
|
||||||
|
# └── VisDrone ← downloads here (2.3 GB)
|
||||||
|
|
||||||
|
|
||||||
|
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||||
|
path: ../datasets/VisDrone # dataset root dir
|
||||||
|
train: VisDrone2019-DET-train/images # train images (relative to 'path') 6471 images
|
||||||
|
val: VisDrone2019-DET-val/images # val images (relative to 'path') 548 images
|
||||||
|
test: VisDrone2019-DET-test-dev/images # test images (optional) 1610 images
|
||||||
|
|
||||||
|
# Classes
|
||||||
|
names:
|
||||||
|
0: pedestrian
|
||||||
|
1: people
|
||||||
|
2: bicycle
|
||||||
|
3: car
|
||||||
|
4: van
|
||||||
|
5: truck
|
||||||
|
6: tricycle
|
||||||
|
7: awning-tricycle
|
||||||
|
8: bus
|
||||||
|
9: motor
|
||||||
|
|
||||||
|
|
||||||
|
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
||||||
|
download: |
|
||||||
|
import os
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
from ultralytics.yolo.utils.downloads import download
|
||||||
|
|
||||||
|
def visdrone2yolo(dir):
|
||||||
|
from PIL import Image
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
def convert_box(size, box):
|
||||||
|
# Convert VisDrone box to YOLO xywh box
|
||||||
|
dw = 1. / size[0]
|
||||||
|
dh = 1. / size[1]
|
||||||
|
return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
|
||||||
|
|
||||||
|
(dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
|
||||||
|
pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
|
||||||
|
for f in pbar:
|
||||||
|
img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
|
||||||
|
lines = []
|
||||||
|
with open(f, 'r') as file: # read annotation.txt
|
||||||
|
for row in [x.split(',') for x in file.read().strip().splitlines()]:
|
||||||
|
if row[4] == '0': # VisDrone 'ignored regions' class 0
|
||||||
|
continue
|
||||||
|
cls = int(row[5]) - 1
|
||||||
|
box = convert_box(img_size, tuple(map(int, row[:4])))
|
||||||
|
lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
|
||||||
|
with open(str(f).replace(f'{os.sep}annotations{os.sep}', f'{os.sep}labels{os.sep}'), 'w') as fl:
|
||||||
|
fl.writelines(lines) # write label.txt
|
||||||
|
|
||||||
|
|
||||||
|
# Download
|
||||||
|
dir = Path(yaml['path']) # dataset root dir
|
||||||
|
urls = ['https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-train.zip',
|
||||||
|
'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-val.zip',
|
||||||
|
'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-dev.zip',
|
||||||
|
'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-challenge.zip']
|
||||||
|
download(urls, dir=dir, curl=True, threads=4)
|
||||||
|
|
||||||
|
# Convert
|
||||||
|
for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
|
||||||
|
visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
|
||||||