mirror of
https://github.com/PaddlePaddle/FastDeploy.git
synced 2025-10-06 17:17:14 +08:00
* first commit for yolov7 * pybind for yolov7 * CPP README.md * CPP README.md * modified yolov7.cc * README.md * python file modify * delete license in fastdeploy/ * repush the conflict part * README.md modified * README.md modified * file path modified * file path modified * file path modified * file path modified * file path modified * README modified * README modified * move some helpers to private * add examples for yolov7 * api.md modified * api.md modified * api.md modified * YOLOv7 * yolov7 release link * yolov7 release link * yolov7 release link * copyright * change some helpers to private * change variables to const and fix documents. * gitignore * Transfer some funtions to private member of class * Transfer some funtions to private member of class * Merge from develop (#9) * Fix compile problem in different python version (#26) * fix some usage problem in linux * Fix compile problem Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> * Add PaddleDetetion/PPYOLOE model support (#22) * add ppdet/ppyoloe * Add demo code and documents * add convert processor to vision (#27) * update .gitignore * Added checking for cmake include dir * fixed missing trt_backend option bug when init from trt * remove un-need data layout and add pre-check for dtype * changed RGB2BRG to BGR2RGB in ppcls model * add model_zoo yolov6 c++/python demo * fixed CMakeLists.txt typos * update yolov6 cpp/README.md * add yolox c++/pybind and model_zoo demo * move some helpers to private * fixed CMakeLists.txt typos * add normalize with alpha and beta * add version notes for yolov5/yolov6/yolox * add copyright to yolov5.cc * revert normalize * fixed some bugs in yolox * fixed examples/CMakeLists.txt to avoid conflicts * add convert processor to vision * format examples/CMakeLists summary * Fix bug while the inference result is empty with YOLOv5 (#29) * Add multi-label function for yolov5 * Update README.md Update doc * Update fastdeploy_runtime.cc fix variable option.trt_max_shape wrong name * Update runtime_option.md Update resnet model dynamic shape setting name from images to x * Fix bug when inference result boxes are empty * Delete detection.py Co-authored-by: Jason <jiangjiajun@baidu.com> Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> Co-authored-by: DefTruth <31974251+DefTruth@users.noreply.github.com> Co-authored-by: huangjianhui <852142024@qq.com> * first commit for yolor * for merge * Develop (#11) * Fix compile problem in different python version (#26) * fix some usage problem in linux * Fix compile problem Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> * Add PaddleDetetion/PPYOLOE model support (#22) * add ppdet/ppyoloe * Add demo code and documents * add convert processor to vision (#27) * update .gitignore * Added checking for cmake include dir * fixed missing trt_backend option bug when init from trt * remove un-need data layout and add pre-check for dtype * changed RGB2BRG to BGR2RGB in ppcls model * add model_zoo yolov6 c++/python demo * fixed CMakeLists.txt typos * update yolov6 cpp/README.md * add yolox c++/pybind and model_zoo demo * move some helpers to private * fixed CMakeLists.txt typos * add normalize with alpha and beta * add version notes for yolov5/yolov6/yolox * add copyright to yolov5.cc * revert normalize * fixed some bugs in yolox * fixed examples/CMakeLists.txt to avoid conflicts * add convert processor to vision * format examples/CMakeLists summary * Fix bug while the inference result is empty with YOLOv5 (#29) * Add multi-label function for yolov5 * Update README.md Update doc * Update fastdeploy_runtime.cc fix variable option.trt_max_shape wrong name * Update runtime_option.md Update resnet model dynamic shape setting name from images to x * Fix bug when inference result boxes are empty * Delete detection.py Co-authored-by: Jason <jiangjiajun@baidu.com> Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> Co-authored-by: DefTruth <31974251+DefTruth@users.noreply.github.com> Co-authored-by: huangjianhui <852142024@qq.com> * Yolor (#16) * Develop (#11) (#12) * Fix compile problem in different python version (#26) * fix some usage problem in linux * Fix compile problem Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> * Add PaddleDetetion/PPYOLOE model support (#22) * add ppdet/ppyoloe * Add demo code and documents * add convert processor to vision (#27) * update .gitignore * Added checking for cmake include dir * fixed missing trt_backend option bug when init from trt * remove un-need data layout and add pre-check for dtype * changed RGB2BRG to BGR2RGB in ppcls model * add model_zoo yolov6 c++/python demo * fixed CMakeLists.txt typos * update yolov6 cpp/README.md * add yolox c++/pybind and model_zoo demo * move some helpers to private * fixed CMakeLists.txt typos * add normalize with alpha and beta * add version notes for yolov5/yolov6/yolox * add copyright to yolov5.cc * revert normalize * fixed some bugs in yolox * fixed examples/CMakeLists.txt to avoid conflicts * add convert processor to vision * format examples/CMakeLists summary * Fix bug while the inference result is empty with YOLOv5 (#29) * Add multi-label function for yolov5 * Update README.md Update doc * Update fastdeploy_runtime.cc fix variable option.trt_max_shape wrong name * Update runtime_option.md Update resnet model dynamic shape setting name from images to x * Fix bug when inference result boxes are empty * Delete detection.py Co-authored-by: Jason <jiangjiajun@baidu.com> Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> Co-authored-by: DefTruth <31974251+DefTruth@users.noreply.github.com> Co-authored-by: huangjianhui <852142024@qq.com> Co-authored-by: Jason <jiangjiajun@baidu.com> Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> Co-authored-by: DefTruth <31974251+DefTruth@users.noreply.github.com> Co-authored-by: huangjianhui <852142024@qq.com> * Develop (#13) * Fix compile problem in different python version (#26) * fix some usage problem in linux * Fix compile problem Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> * Add PaddleDetetion/PPYOLOE model support (#22) * add ppdet/ppyoloe * Add demo code and documents * add convert processor to vision (#27) * update .gitignore * Added checking for cmake include dir * fixed missing trt_backend option bug when init from trt * remove un-need data layout and add pre-check for dtype * changed RGB2BRG to BGR2RGB in ppcls model * add model_zoo yolov6 c++/python demo * fixed CMakeLists.txt typos * update yolov6 cpp/README.md * add yolox c++/pybind and model_zoo demo * move some helpers to private * fixed CMakeLists.txt typos * add normalize with alpha and beta * add version notes for yolov5/yolov6/yolox * add copyright to yolov5.cc * revert normalize * fixed some bugs in yolox * fixed examples/CMakeLists.txt to avoid conflicts * add convert processor to vision * format examples/CMakeLists summary * Fix bug while the inference result is empty with YOLOv5 (#29) * Add multi-label function for yolov5 * Update README.md Update doc * Update fastdeploy_runtime.cc fix variable option.trt_max_shape wrong name * Update runtime_option.md Update resnet model dynamic shape setting name from images to x * Fix bug when inference result boxes are empty * Delete detection.py Co-authored-by: Jason <jiangjiajun@baidu.com> Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> Co-authored-by: DefTruth <31974251+DefTruth@users.noreply.github.com> Co-authored-by: huangjianhui <852142024@qq.com> * documents * documents * documents * documents * documents * documents * documents * documents * documents * documents * documents * documents * Develop (#14) * Fix compile problem in different python version (#26) * fix some usage problem in linux * Fix compile problem Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> * Add PaddleDetetion/PPYOLOE model support (#22) * add ppdet/ppyoloe * Add demo code and documents * add convert processor to vision (#27) * update .gitignore * Added checking for cmake include dir * fixed missing trt_backend option bug when init from trt * remove un-need data layout and add pre-check for dtype * changed RGB2BRG to BGR2RGB in ppcls model * add model_zoo yolov6 c++/python demo * fixed CMakeLists.txt typos * update yolov6 cpp/README.md * add yolox c++/pybind and model_zoo demo * move some helpers to private * fixed CMakeLists.txt typos * add normalize with alpha and beta * add version notes for yolov5/yolov6/yolox * add copyright to yolov5.cc * revert normalize * fixed some bugs in yolox * fixed examples/CMakeLists.txt to avoid conflicts * add convert processor to vision * format examples/CMakeLists summary * Fix bug while the inference result is empty with YOLOv5 (#29) * Add multi-label function for yolov5 * Update README.md Update doc * Update fastdeploy_runtime.cc fix variable option.trt_max_shape wrong name * Update runtime_option.md Update resnet model dynamic shape setting name from images to x * Fix bug when inference result boxes are empty * Delete detection.py Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> Co-authored-by: DefTruth <31974251+DefTruth@users.noreply.github.com> Co-authored-by: huangjianhui <852142024@qq.com> Co-authored-by: Jason <jiangjiajun@baidu.com> Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> Co-authored-by: DefTruth <31974251+DefTruth@users.noreply.github.com> Co-authored-by: huangjianhui <852142024@qq.com> Co-authored-by: Jason <928090362@qq.com> * add is_dynamic for YOLO series (#22) * modify ppmatting backend and docs * modify ppmatting docs * fix the PPMatting size problem * fix LimitShort's log * retrigger ci * modify PPMatting docs * modify the way for dealing with LimitShort * add python comments for external models * modify resnet c++ comments * modify C++ comments for external models * modify python comments and add result class comments * fix comments compile error * modify result.h comments * deadlink check * deadlink check * deadlink check Co-authored-by: Jason <jiangjiajun@baidu.com> Co-authored-by: root <root@bjyz-sys-gpu-kongming3.bjyz.baidu.com> Co-authored-by: DefTruth <31974251+DefTruth@users.noreply.github.com> Co-authored-by: huangjianhui <852142024@qq.com> Co-authored-by: Jason <928090362@qq.com>
目标检测 C++ API Demo 使用指南
在 ARMLinux 上实现实时的目标检测功能,此 Demo 有较好的的易用性和扩展性,如在 Demo 中跑自己训练好的模型等。
- 如果该开发板使用搭载了芯原 NPU (瑞芯微、晶晨、JQL、恩智浦)的 Soc,将有更好的加速效果。
如何运行目标检测 Demo
环境准备
- 准备 ARMLiunx 开发版,将系统刷为 Ubuntu,用于 Demo 编译和运行。请注意,本 Demo 是使用板上编译,而非交叉编译,因此需要图形界面的开发板操作系统。
- 如果需要使用 芯原 NPU 的计算加速,对 NPU 驱动版本有严格要求,请务必注意事先参考 芯原 TIM-VX 部署示例,将 NPU 驱动改为要求的版本。
- Paddle Lite 当前已验证的开发板为 Khadas VIM3(芯片为 Amlogic A311d)、荣品 RV1126、荣品RV1109,其它平台用户可自行尝试;
- Khadas VIM3:由于 VIM3 出厂自带 Android 系统,请先刷成 Ubuntu 系统,在此提供刷机教程:VIM3/3L Linux 文档,其中有详细描述刷机方法。以及系统镜像:VIM3 Linux:VIM3_Ubuntu-gnome-focal_Linux-4.9_arm64_EMMC_V1.0.7-210625:官方链接;百度云备用链接
- 荣品 RV1126、1109:由于出场自带 buildroot 系统,如果使用 GUI 界面的 demo,请先刷成 Ubuntu 系统,在此提供刷机教程:RV1126/1109 教程,刷机工具,以及镜像:1126镜像,1109镜像。完整的文档和各种镜像请参考百度网盘链接,密码:2345。
- 准备 usb camera,注意使用 openCV capture 图像时,请注意 usb camera 的 video序列号作为入参。
- 请注意,瑞芯微芯片不带有 HDMI 接口,图像显示是依赖 MIPI DSI,所以请准备好 MIPI 显示屏(我们提供的镜像是 720*1280 分辨率,网盘中有更多分辨率选择,注意:请选择 camera-gc2093x2 的镜像)。
- 配置开发板的网络。如果是办公网络红区,可以将开发板和PC用以太网链接,然后PC共享网络给开发板。
- gcc g++ opencv cmake 的安装(以下所有命令均在设备上操作)
$ sudo apt-get update
$ sudo apt-get install gcc g++ make wget unzip libopencv-dev pkg-config
$ wget https://www.cmake.org/files/v3.10/cmake-3.10.3.tar.gz
$ tar -zxvf cmake-3.10.3.tar.gz
$ cd cmake-3.10.3
$ ./configure
$ make
$ sudo make install
部署步骤
- 将本 repo 上传至 VIM3 开发板,或者直接开发板上下载或者 git clone 本 repo
- 目标检测 Demo 位于
Paddle-Lite-Demo/object_detection/linux/picodet_detection目录 - 进入
Paddle-Lite-Demo/object_detection/linux目录, 终端中执行download_models_and_libs.sh脚本自动下载模型和 Paddle Lite 预测库
cd Paddle-Lite-Demo/object_detection/linux # 1. 终端中进入 Paddle-Lite-Demo/object_detection/linux
sh download_models_and_libs.sh # 2. 执行脚本下载依赖项 (需要联网)
下载完成后会出现提示: Download successful!
4. 执行用例(保证 ARMLinux 环境准备完成)
cd picodet_detection # 1. 终端中进入
sh build.sh armv8 # 2. 编译 Demo 可执行程序,默认编译 armv8,如果是 32bit 环境,则改成 sh build.sh armv7hf。
sh run.sh armv8 # 3. 执行物体检测(picodet 模型) demo,会直接开启摄像头,启动图形界面并呈现检测结果。如果是 32bit 环境,则改成 sh run.sh armv7hf
Demo 结果如下:(注意,示例的 picodet 仅使用 coco 数据集,在实际场景中效果一般,请使用实际业务场景重新训练)
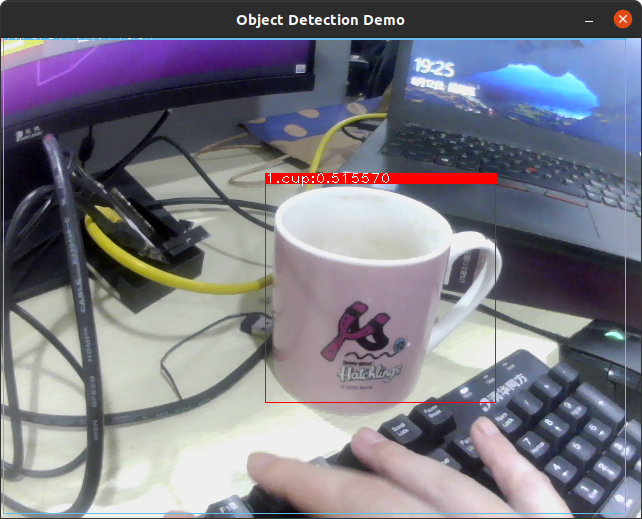
更新预测库
- Paddle Lite 项目:https://github.com/PaddlePaddle/Paddle-Lite
- 参考 芯原 TIM-VX 部署示例,编译预测库
- 编译最终产物位于
build.lite.xxx.xxx.xxx下的inference_lite_lib.xxx.xxx- 替换 c++ 库
- 头文件
将生成的
build.lite.linux.armv8.gcc/inference_lite_lib.armlinux.armv8.nnadapter/cxx/include文件夹替换 Demo 中的Paddle-Lite-Demo/object_detection/linux/Paddle-Lite/include - armv8
将生成的
build.lite.linux.armv8.gcc/inference_lite_lib.armlinux.armv8.nnadapter/cxx/libs/libpaddle_full_api_shared.so、libnnadapter.so、libtim-vx.so、libverisilicon_timvx.so库替换 Demo 中的Paddle-Lite-Demo/object_detection/linux/Paddle-Lite/libs/armv8/目录下同名 so - armv7hf
将生成的
build.lite.linux.armv7hf.gcc/inference_lite_lib.armlinux.armv7hf.nnadapter/cxx/libs/libpaddle_full_api_shared.so、libnnadapter.so、libtim-vx.so、libverisilicon_timvx.so库替换 Demo 中的Paddle-Lite-Demo/object_detection/linux/Paddle-Lite/libs/armv7hf/目录下同名 so
- 头文件
将生成的
- 替换 c++ 库
Demo 内容介绍
先整体介绍下目标检测 Demo 的代码结构,然后再简要地介绍 Demo 每部分功能.
object_detection_demo.cc: C++ 预测代码
# 位置:
Paddle-Lite-Demo/object_detection/linux/picodet_detection/object_detection_demo.cc
models: 模型文件夹 (执行 download_models_and_libs.sh 后会下载 picodet Paddle 模型), label 使用 Paddle-Lite-Demo/object_detection/assets/labels 目录下 coco_label_list.txt
# 位置:
Paddle-Lite-Demo/object_detection/linux/picodet_detection/models/picodetv2_relu6_coco_no_fuse
Paddle-Lite-Demo/object_detection/assets/labels/coco_label_list.txt
Paddle-Lite:内含 Paddle-Lite 头文件和 动态库,默认带有 timvx 加速库,以及第三方库 yaml-cpp 用于解析 yml 配置文件(执行 download_models_and_libs.sh 后会下载)
# 位置
# 如果要替换动态库 so,则将新的动态库 so 更新到此目录下
Paddle-Lite-Demo/object_detection/linux/Paddle-Lite/libs/armv8
Paddle-Lite-Demo/object_detection/linux/Paddle-Lite/include
CMakeLists.txt: C++ 预测代码的编译脚本,用于生成可执行文件
# 位置
Paddle-Lite-Demo/object_detection/linux/picodet_detection/CMakeLists.txt
# 如果有cmake 编译选项更新,可以在 CMakeLists.txt 进行修改即可,默认编译 armv8 可执行文件;
build.sh: 编译脚本
# 位置
Paddle-Lite-Demo/object_detection/linux/picodet_detection/build.sh
run.sh: 运行脚本,请注意设置 arm-aarch,armv8 或者 armv7hf。默认为armv8
# 位置
Paddle-Lite-Demo/object_detection/linux/picodet_detection/run.sh
- 请注意,运行需要5个元素:测试程序、模型、label 文件、异构配置、yaml 文件。
代码讲解 (使用 Paddle Lite C++ API 执行预测)
ARMLinux 示例基于 C++ API 开发,调用 Paddle Lite C++s API 包括以下五步。更详细的 API 描述参考:Paddle Lite C++ API 。
#include <iostream>
// 引入 C++ API
#include "include/paddle_api.h"
#include "include/paddle_use_ops.h"
#include "include/paddle_use_kernels.h"
// 使用在线编译模型的方式(等价于使用 opt 工具)
// 1. 设置 CxxConfig
paddle::lite_api::CxxConfig cxx_config;
std::vector<paddle::lite_api::Place> valid_places;
valid_places.push_back(
paddle::lite_api::Place{TARGET(kARM), PRECISION(kInt8)});
valid_places.push_back(
paddle::lite_api::Place{TARGET(kARM), PRECISION(kFloat)});
// 如果只需要 cpu 计算,那到此结束即可,下面是设置 NPU 的代码段
valid_places.push_back(
paddle::lite_api::Place{TARGET(kNNAdapter), PRECISION(kInt8)});
cxx_config.set_valid_places(valid_places);
std::string device = "verisilicon_timvx";
cxx_config.set_nnadapter_device_names({device});
// 设置定制化的异构策略 (如需要)
cxx_config.set_nnadapter_subgraph_partition_config_buffer(
nnadapter_subgraph_partition_config_string);
// 2. 生成 nb 模型 (等价于 opt 工具的产出)
std::shared_ptr<paddle::lite_api::PaddlePredictor> predictor = nullptr;
predictor = paddle::lite_api::CreatePaddlePredictor(cxx_config);
predictor->SaveOptimizedModel(
model_path, paddle::lite_api::LiteModelType::kNaiveBuffer);
// 3. 设置 MobileConfig
MobileConfig config;
config.set_model_from_file(modelPath); // 设置 NaiveBuffer 格式模型路径
config.set_power_mode(LITE_POWER_NO_BIND); // 设置 CPU 运行模式
config.set_threads(4); // 设置工作线程数
// 4. 创建 PaddlePredictor
predictor = CreatePaddlePredictor<MobileConfig>(config);
// 5. 设置输入数据,注意,如果是带后处理的 picodet ,则是有两个输入
std::unique_ptr<Tensor> input_tensor(std::move(predictor->GetInput(0)));
input_tensor->Resize({1, 3, 416, 416});
auto* data = input_tensor->mutable_data<float>();
// scale_factor tensor
auto scale_factor_tensor = predictor->GetInput(1);
scale_factor_tensor->Resize({1, 2});
auto scale_factor_data = scale_factor_tensor->mutable_data<float>();
scale_factor_data[0] = 1.0f;
scale_factor_data[1] = 1.0f;
// 6. 执行预测
predictor->run();
// 7. 获取输出数据
std::unique_ptr<const Tensor> output_tensor(std::move(predictor->GetOutput(0)));
如何更新模型和输入/输出预处理
更新模型
- 请参考 PaddleDetection 中 picodet 重训和全量化文档,基于用户自己数据集重训并且重新全量化
- 将模型存放到目录
object_detection_demo/models/下; - 模型名字跟工程中模型名字一模一样,即均是使用
model、params;
# shell 脚本 `object_detection_demo/run.sh`
TARGET_ABI=armv8 # for 64bit, such as Amlogic A311D
#TARGET_ABI=armv7hf # for 32bit, such as Rockchip 1109/1126
if [ -n "$1" ]; then
TARGET_ABI=$1
fi
export LD_LIBRARY_PATH=../Paddle-Lite/libs/$TARGET_ABI/
export GLOG_v=0 # Paddle-Lite 日志等级
export VSI_NN_LOG_LEVEL=0 # TIM-VX 日志等级
export VIV_VX_ENABLE_GRAPH_TRANSFORM=-pcq:1 # NPU 开启 perchannel 量化模型
export VIV_VX_SET_PER_CHANNEL_ENTROPY=100 # 同上
build/object_detection_demo models/picodetv2_relu6_coco_no_fuse ../../assets/labels/coco_label_list.txt models/picodetv2_relu6_coco_no_fuse/subgraph.txt models/picodetv2_relu6_coco_no_fuse/picodet.yml # 执行 Demo 程序,4个 arg 分别为:模型、 label 文件、 自定义异构配置、 yaml
- 如果需要更新
label_list或者yaml文件,则修改object_detection_demo/run.sh中执行命令的第二个和第四个 arg 指定为新的 label 文件和 yaml 配置文件;
# 代码文件 `object_detection_demo/rush.sh`
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${PADDLE_LITE_DIR}/libs/${TARGET_ARCH_ABI}
build/object_detection_demo {模型} {label} {自定义异构配置文件} {yaml}
更新输入/输出预处理
-
更新输入预处理 预处理完全根据 yaml 文件来,如果完全按照 PaddleDetection 中 picodet 重训,只需要替换 yaml 文件即可
-
更新输出预处理 此处需要更新
object_detection_demo/object_detection_demo.cc中的postprocess方法
std::vector<RESULT> postprocess(const float *output_data, int64_t output_size,
const std::vector<std::string> &word_labels,
const float score_threshold,
cv::Mat &output_image, double time) {
std::vector<RESULT> results;
std::vector<cv::Scalar> colors = {
cv::Scalar(237, 189, 101), cv::Scalar(0, 0, 255),
cv::Scalar(102, 153, 153), cv::Scalar(255, 0, 0),
cv::Scalar(9, 255, 0), cv::Scalar(0, 0, 0),
cv::Scalar(51, 153, 51)};
for (int64_t i = 0; i < output_size; i += 6) {
if (output_data[i + 1] < score_threshold) {
continue;
}
int class_id = static_cast<int>(output_data[i]);
float score = output_data[i + 1];
RESULT result;
std::string class_name = "Unknown";
if (word_labels.size() > 0 && class_id >= 0 &&
class_id < word_labels.size()) {
class_name = word_labels[class_id];
}
result.class_name = class_name;
result.score = score;
result.left = output_data[i + 2] / 416; // 此处416根据输入的 HW 得来
result.top = output_data[i + 3] / 416;
result.right = output_data[i + 4] / 416;
result.bottom = output_data[i + 5] / 416;
int lx = static_cast<int>(result.left * output_image.cols);
int ly = static_cast<int>(result.top * output_image.rows);
int w = static_cast<int>(result.right * output_image.cols) - lx;
int h = static_cast<int>(result.bottom * output_image.rows) - ly;
cv::Rect bounding_box =
cv::Rect(lx, ly, w, h) &
cv::Rect(0, 0, output_image.cols, output_image.rows);
if (w > 0 && h > 0 && score <= 1) {
cv::Scalar color = colors[results.size() % colors.size()];
cv::rectangle(output_image, bounding_box, color);
cv::rectangle(output_image, cv::Point2d(lx, ly),
cv::Point2d(lx + w, ly - 10), color, -1);
cv::putText(output_image, std::to_string(results.size()) + "." +
class_name + ":" + std::to_string(score),
cv::Point2d(lx, ly), cv::FONT_HERSHEY_PLAIN, 1,
cv::Scalar(255, 255, 255));
results.push_back(result);
}
}
return results;
}
更新模型后,自定义 NPU-CPU 异构配置(如需使用 NPU 加速)
由于使用芯原 NPU 在 8bit 量化的情况下有最优的性能,因此部署时,我们往往会考虑量化
- 由于量化可能会引入一定程度的精度问题,所以我们可以通过自定义的异构定制,来将部分有精度问题的 layer 异构至cpu,从而达到最优的精度
第一步,确定模型量化后在 arm cpu 上的精度
如果在 arm cpu 上,精度都无法满足,那量化本身就是失败的,此时可以考虑修改训练集或者预处理。
- 修改 Demo 程序,仅用 arm cpu 计算
paddle::lite_api::CxxConfig cxx_config;
std::vector<paddle::lite_api::Place> valid_places;
valid_places.push_back(
paddle::lite_api::Place{TARGET(kARM), PRECISION(kInt8)});
valid_places.push_back(
paddle::lite_api::Place{TARGET(kARM), PRECISION(kFloat)});
// 仅用 arm cpu 计算, 注释如下代码即可
/*
valid_places.push_back(
paddle::lite_api::Place{TARGET(kNNAdapter), PRECISION(kInt8)});
valid_places.push_back(
paddle::lite_api::Place{TARGET(kNNAdapter), PRECISION(kFloat)});
*/
如果 arm cpu 计算结果精度达标,则继续
第二步,获取整网拓扑信息
- 回退第一步的修改,不再注释,使用 NPU 加速
- 运行 Demo,如果此时精度良好,则无需参考后面步骤,模型部署和替换非常顺利,enjoy it。
- 如果精度不行,请参考后续步骤。
第三步,获取整网拓扑信息
- 回退第一步的修改,使用
- 修改 run.sh ,将其中 export GLOG_v=0 改为 export GLOG_v=5
- 运行 Demo,等摄像头启动,即可 ctrl+c 关闭 Demo
- 收集日志,搜索关键字 "subgraph operators" 随后那一段,便是整个模型的拓扑信息,其格式如下:
- 每行记录由『算子类型:输入张量名列表:输出张量名列表』组成(即以分号分隔算子类型、输入和输出张量名列表),以逗号分隔输入、输出张量名列表中的每个张量名;
- 示例说明:
op_type0:var_name0,var_name1:var_name2 表示将算子类型为 op_type0、输入张量为var_name0 和 var_name1、输出张量为 var_name2 的节点强制运行在 ARM CPU 上
第四步,修改异构配置文件
- 首先看到示例 Demo 中 Paddle-Lite-Demo/object_detection/linux/picodet_detection/models/picodetv2_relu6_coco_no_fuse 目录下的 subgraph.txt 文件。(feed 和 fetch 分别代表整个模型的输入和输入)
feed:feed:scale_factor
feed:feed:image
sqrt:tmp_3:sqrt_0.tmp_0
reshape2:sqrt_0.tmp_0:reshape2_0.tmp_0,reshape2_0.tmp_1
matmul_v2:softmax_0.tmp_0,auto_113_:linear_0.tmp_0
reshape2:linear_0.tmp_0:reshape2_2.tmp_0,reshape2_2.tmp_1
sqrt:tmp_6:sqrt_1.tmp_0
reshape2:sqrt_1.tmp_0:reshape2_3.tmp_0,reshape2_3.tmp_1
matmul_v2:softmax_1.tmp_0,auto_113_:linear_1.tmp_0
reshape2:linear_1.tmp_0:reshape2_5.tmp_0,reshape2_5.tmp_1
sqrt:tmp_9:sqrt_2.tmp_0
reshape2:sqrt_2.tmp_0:reshape2_6.tmp_0,reshape2_6.tmp_1
matmul_v2:softmax_2.tmp_0,auto_113_:linear_2.tmp_0
...
- 在 txt 中的都是需要异构至 cpu 计算的 layer,在示例 Demo 中,我们把 picodet 后处理的部分异构至 arm cpu 做计算,不必担心,Paddle-Lite 的 arm kernel 性能也是非常卓越。
- 如果新训练的模型没有额外修改 layer,则直接复制使用示例 Demo 中的 subgraph.txt 即可
- 此时 ./run.sh 看看精度是否符合预期,如果精度符合预期,恭喜,可以跳过本章节,enjoy it。
- 如果精度不符合预期,则将上文『第二步,获取整网拓扑信息』中获取的拓扑信息,从 "feed" 之后第一行,直到 "sqrt" 之前,都复制进 sugraph.txt。这一步代表了将大量的 backbone 部分算子放到 arm cpu 计算。
- 此时 ./run.sh 看看精度是否符合预期,如果精度达标,那说明在 backbone 中确实存在引入 NPU 精度异常的层(再次重申,在 subgraph.txt 的代表强制在 arm cpu 计算)。
- 逐行删除、成片删除、二分法,发挥开发人员的耐心,找到引入 NPU 精度异常的 layer,将其留在 subgraph.txt 中,按照经验,如果有 NPU 精度问题,可能会有 1~5 层conv layer 需要异构。
- 剩余没有精度问题的 layer 在 subgraph.txt 中删除即可