mirror of
https://github.com/PaddlePaddle/FastDeploy.git
synced 2025-10-05 16:48:03 +08:00
[Doc]Add English version of documents in examples/ (#1042)
* 第一次提交 * 补充一处漏翻译 * deleted: docs/en/quantize.md * Update one translation * Update en version * Update one translation in code * Standardize one writing * Standardize one writing * Update some en version * Fix a grammer problem * Update en version for api/vision result * Merge branch 'develop' of https://github.com/charl-u/FastDeploy into develop * Checkout the link in README in vision_results/ to the en documents * Modify a title * Add link to serving/docs/ * Finish translation of demo.md * Update english version of serving/docs/ * Update title of readme * Update some links * Modify a title * Update some links * Update en version of java android README * Modify some titles * Modify some titles * Modify some titles * modify article to document * update some english version of documents in examples * Add english version of documents in examples/visions * Sync to current branch * Add english version of documents in examples
This commit is contained in:
@@ -1,3 +1,4 @@
|
||||
English | [简体中文](README_CN.md)
|
||||
# PaddleJsConverter
|
||||
|
||||
## Installation
|
||||
@@ -26,4 +27,4 @@ pip3 install paddlejsconverter
|
||||
```shell
|
||||
paddlejsconverter --modelPath=user_model_path --paramPath=user_model_params_path --outputDir=model_saved_path --useGPUOpt=True
|
||||
```
|
||||
注意:useGPUOpt 选项默认不开启,如果模型用在 gpu backend(webgl/webgpu),则开启 useGPUOpt,如果模型运行在(wasm/plain js)则不要开启。
|
||||
Note: The option useGPUOpt is not turned on by default. Turn on useGPUOpt if the model is used on gpu backend (webgl/webgpu), don't turn on if is running on (wasm/plain js).
|
||||
|
||||
30
examples/application/js/converter/README_CN.md
Normal file
30
examples/application/js/converter/README_CN.md
Normal file
@@ -0,0 +1,30 @@
|
||||
简体中文 | [English](README.md)
|
||||
# PaddleJsConverter
|
||||
|
||||
## Installation
|
||||
|
||||
System Requirements:
|
||||
|
||||
* paddlepaddle >= 2.0.0
|
||||
* paddlejslite >= 0.0.2
|
||||
* Python3: 3.5.1+ / 3.6 / 3.7
|
||||
* Python2: 2.7.15+
|
||||
|
||||
#### Install PaddleJsConverter
|
||||
|
||||
<img src="https://img.shields.io/pypi/v/paddlejsconverter" alt="version">
|
||||
|
||||
```shell
|
||||
pip install paddlejsconverter
|
||||
|
||||
# or
|
||||
pip3 install paddlejsconverter
|
||||
```
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
```shell
|
||||
paddlejsconverter --modelPath=user_model_path --paramPath=user_model_params_path --outputDir=model_saved_path --useGPUOpt=True
|
||||
```
|
||||
注意:useGPUOpt 选项默认不开启,如果模型用在 gpu backend(webgl/webgpu),则开启 useGPUOpt,如果模型运行在(wasm/plain js)则不要开启。
|
||||
@@ -1,3 +1,4 @@
|
||||
简体中文 | [English](RNN_EN.md)
|
||||
# RNN算子计算过程
|
||||
|
||||
## 一、RNN理解
|
||||
@@ -73,7 +74,7 @@ paddle源码实现:https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/
|
||||
|
||||
计算方式:将rnn_matmul op输出结果分割成4份,每份执行不同激活函数计算,最后输出lstm_x_y.tmp_c[1, 1, 48]。x∈[0, 3],y∈[0, 24]。
|
||||
详见算子实现:[rnn_cell](../paddlejs-backend-webgl/src/ops/shader/rnn/rnn_cell.ts)
|
||||
)
|
||||
|
||||
|
||||
4)rnn_hidden
|
||||
计算方式:将rnn_matmul op输出结果分割成4份,每份执行不同激活函数计算,最后输出lstm_x_y.tmp_h[1, 1, 48]。x∈[0, 3],y∈[0, 24]。
|
||||
|
||||
80
examples/application/js/converter/RNN_EN.md
Normal file
80
examples/application/js/converter/RNN_EN.md
Normal file
@@ -0,0 +1,80 @@
|
||||
English | [简体中文](RNN.md)
|
||||
# The computation process of RNN operator
|
||||
|
||||
## 1. Understanding of RNN
|
||||
|
||||
**RNN** is a recurrent neural network, including an input layer, a hidden layer and an output layer, which is specialized in processing sequential data.
|
||||
|
||||
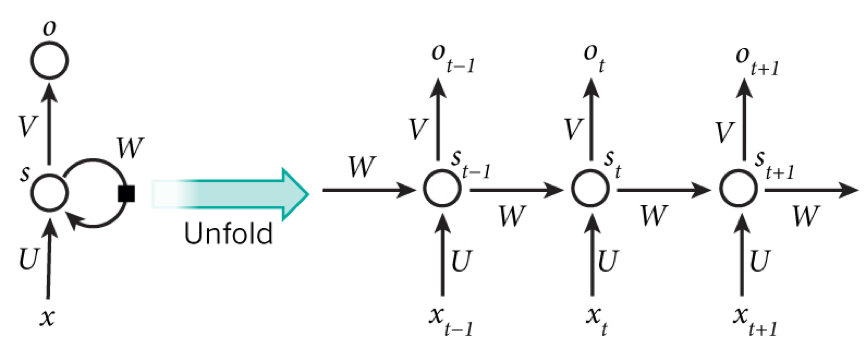
|
||||
paddle official document: https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/RNN_cn.html#rnn
|
||||
|
||||
paddle source code implementation: https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/operators/rnn_op.h#L812
|
||||
|
||||
## 2. How to compute RNN
|
||||
|
||||
At moment t, the input layer is , hidden layer is , output layer is . As the picture above, isn't just decided by ,it is also related to . The formula is as follows.:
|
||||
|
||||
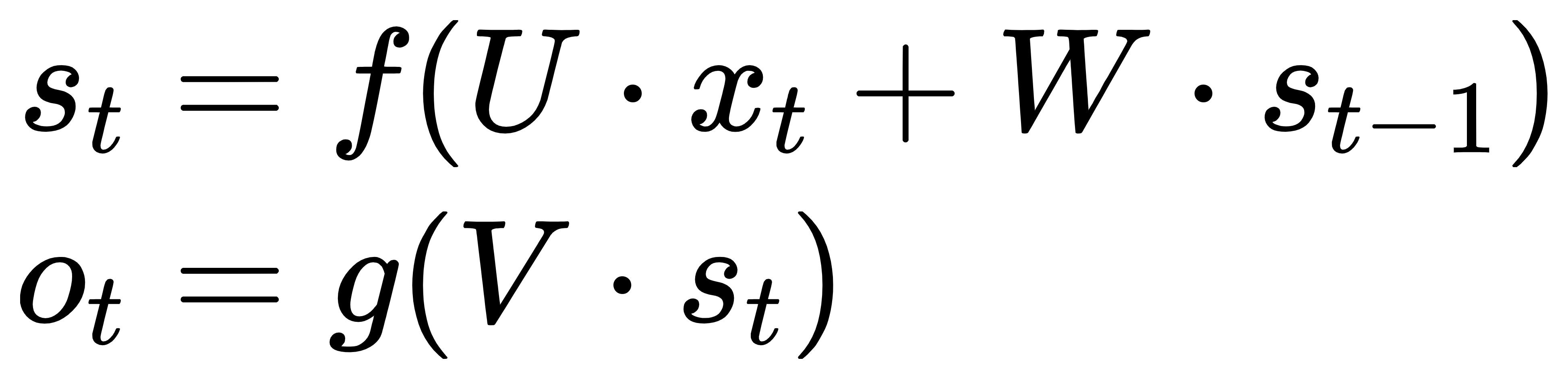
|
||||
|
||||
## 3. RNN operator implementation in pdjs
|
||||
|
||||
Because the gradient disappearance problem exists in RNN, and more contextual information cannot be obtained, **LSTM (Long Short Term Memory)** is used in CRNN, which is a special kind of RNN that can preserve long-term dependencies.
|
||||
|
||||
Based on the image sequence, the two directions of context are mutually useful and complementary. Since the LSTM is unidirectional, two LSTMs, one forward and one backward, are combined into a **bidirectional LSTM**. In addition, multiple layers of bidirectional LSTMs can be stacked. ch_PP-OCRv2_rec_infer recognition model is using a two-layer bidirectional LSTM structure. The calculation process is shown as follows.
|
||||
|
||||
#### Take ch_ppocr_mobile_v2.0_rec_infer model, rnn operator as an example
|
||||
```javascript
|
||||
{
|
||||
Attr: {
|
||||
mode: 'LSTM'
|
||||
// Whether bidirectional, if true, it is necessary to traverse both forward and reverse.
|
||||
is_bidirec: true
|
||||
// Number of hidden layers, representing the number of loops.
|
||||
num_layers: 2
|
||||
}
|
||||
|
||||
Input: [
|
||||
transpose_1.tmp_0[25, 1, 288]
|
||||
]
|
||||
|
||||
PreState: [
|
||||
fill_constant_batch_size_like_0.tmp_0[4, 1, 48],
|
||||
fill_constant_batch_size_like_1.tmp_0[4, 1, 48]
|
||||
]
|
||||
|
||||
WeightList: [
|
||||
lstm_cell_0.w_0[192, 288], lstm_cell_0.w_1[192, 48],
|
||||
lstm_cell_1.w_0[192, 288], lstm_cell_1.w_1[192, 48],
|
||||
lstm_cell_2.w_0[192, 96], lstm_cell_2.w_1[192, 48],
|
||||
lstm_cell_3.w_0[192, 96], lstm_cell_3.w_1[192, 48],
|
||||
lstm_cell_0.b_0[192], lstm_cell_0.b_1[192],
|
||||
lstm_cell_1.b_0[192], lstm_cell_1.b_1[192],
|
||||
lstm_cell_2.b_0[192], lstm_cell_2.b_1[192],
|
||||
lstm_cell_3.b_0[192], lstm_cell_3.b_1[192]
|
||||
]
|
||||
|
||||
Output: [
|
||||
lstm_0.tmp_0[25, 1, 96]
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
#### Overall computation process
|
||||
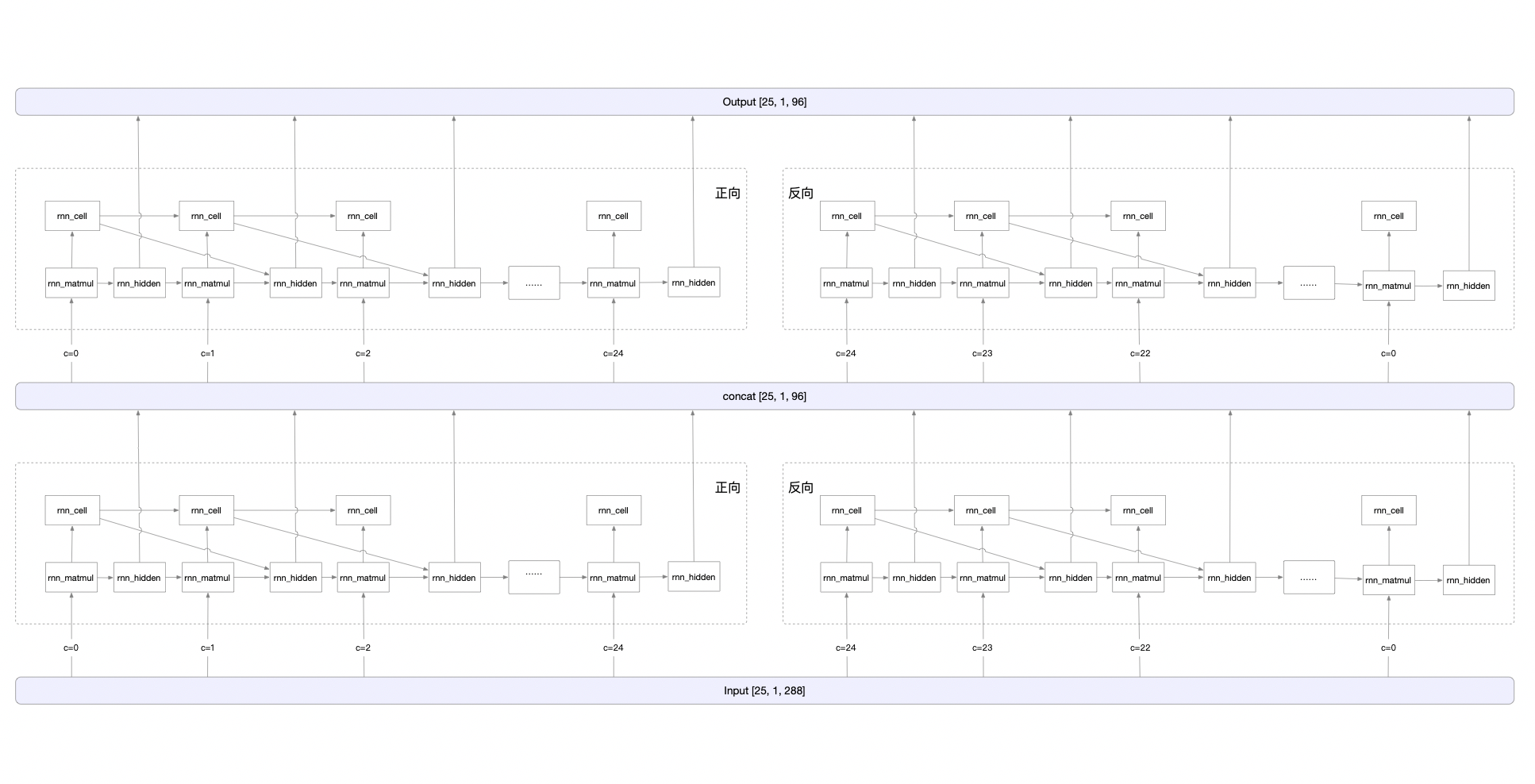
|
||||
#### Add op in rnn calculation
|
||||
1) rnn_origin
|
||||
Formula: blas.MatMul(Input, WeightList_ih, blas_ih) + blas.MatMul(PreState, WeightList_hh, blas_hh)
|
||||
|
||||
2) rnn_matmul
|
||||
Formula: rnn_matmul = rnn_origin + Matmul( $ S_{t-1} $, WeightList_hh)
|
||||
|
||||
3) rnn_cell
|
||||
Method: Split the rnn_matmul op output into 4 copies, each copy performs a different activation function calculation, and finally outputs lstm_x_y.tmp_c[1, 1, 48]. x∈[0, 3], y∈[0, 24].
|
||||
For details, please refer to [rnn_cell](../paddlejs-backend-webgl/src/ops/shader/rnn/rnn_cell.ts).
|
||||
|
||||
|
||||
4) rnn_hidden
|
||||
Split the rnn_matmul op output into 4 copies, each copy performs a different activation function calculation, and finally outputs lstm_x_y.tmp_h[1, 1, 48]. x∈[0, 3], y∈[0, 24].
|
||||
For details, please refer to [rnn_hidden](../paddlejs-backend-webgl/src/ops/shader/rnn/rnn_hidden.ts).
|
||||
|
||||
|
||||
@@ -47,7 +47,7 @@ humanseg.drawMask(data, canvas3, back_canvas);
|
||||
|
||||
```js
|
||||
|
||||
// 引入 humanseg sdk
|
||||
// import humanseg sdk
|
||||
import * as humanseg from '@paddle-js-models/humanseg/lib/index_gpu';
|
||||
|
||||
// load humanseg model, use 398x224 shape model, and preheat
|
||||
|
||||
Reference in New Issue
Block a user