* add ocr serving example * 1 1 * Add files via upload * Update README.md * Delete ocr_pipeline.png * Add files via upload * Delete ocr_pipeline.png * Add files via upload * 1 1 * 1 1 * Update README.md * 1 1 * fix codestyle * fix codestyle * Update README_CN.md * Update README_EN.md * Update demo.md * Update demo.md * Add files via upload * Update demo.md * Add files via upload * Delete dynamic_batching.png * Delete instance_group.png * Delete simple_ensemble.png * Add files via upload * Update demo.md * Update demo.md * Update demo.md * Update demo.md * Delete dynamic_batching.png * Delete instance_group.png * Delete simple_ensemble.png * Update demo.md Co-authored-by: Jason <jiangjiajun@baidu.com> Co-authored-by: heliqi <1101791222@qq.com>
8.3 KiB
服务化部署示例
我们以最简单的yolov5模型为例,讲述如何进行服务化部署,详细的代码和操作步骤见yolov5服务化部署,阅读本文之前建议您先阅读以下文档:
基本原理介绍
像常见的深度学习模型一样,yolov5完整的运行过程包含前处理+模型预测+后处理三个阶段。
在Triton中,将前处理、模型预测、后处理均视为1个Triton-Model,每个Triton-Model的config.pbtxt配置文件中均描述了其输入数据格式、输出数据格式、Triton-Model的类型(即config.pbtxt中的backend或platform字段)、以及其他的一些配置选项。
前处理和后处理一般是运行一段Python代码,为了方便后续描述,我们称之为Python-Triton-Model,其config.pbtxt配置文件中的backend: "python"。
模型预测阶段是深度学习模型预测引擎(如ONNXRuntime、Paddle、TRT、FastDeploy)加载用户提供的深度学习模型文件来运行模型预测,我们称之为Runtime-Triton-Model,其config.pbtxt配置文件中的backend: "fastdeploy"。
根据用户提供的模型类型的不同,可以在optimization字段中设置使用CPU、GPU、TRT、ONNX等配置,配置方法参考服务化部署配置说明。
除此之外,还需要一个Ensemble-Triton-Model来将前处理、模型预测、后处理3个Triton-Model组合为1个整体,并描述3个Triton-Model之间的关联关系。例如,前处理的输出与模型预测的输入之间的对应关系,多个Triton-Model的调用顺序、串并联关系等,Ensemble-Triton-Model的config.pbtxt配置文件中的platform: "ensemble"。
在本文的yolov5服务化示例中,Ensemble-Triton-Model将前处理、模型预测、后处理3个Triton-Model串联组合为1个整体,整体的结构如下图所示。

对于像OCR这样多个深度学习模型的组合模型,或者流式输入输出的深度学习模型,其Ensemble-Triton-Model会更加复杂。
Python-Triton-Model简介
我们以yolov5前处理为例,简单介绍一下编写Python-Triton-Model中的注意事项。
Python-Triton-Model代码model.py的整体结构框架如下所示。Python代码的核心是1个class TritonPythonModel类,类中包含3个成员函数initialize、execute、finalize,类名、成员函数名、函数输入变量都不允许更改。在此基础上,用户可以自行编写代码。
import json
import numpy as np
import time
import fastdeploy as fd
# triton_python_backend_utils is available in every Triton Python model. You
# need to use this module to create inference requests and responses. It also
# contains some utility functions for extracting information from model_config
# and converting Triton input/output types to numpy types.
import triton_python_backend_utils as pb_utils
class TritonPythonModel:
"""Your Python model must use the same class name. Every Python model
that is created must have "TritonPythonModel" as the class name.
"""
def initialize(self, args):
"""`initialize` is called only once when the model is being loaded.
Implementing `initialize` function is optional. This function allows
the model to intialize any state associated with this model.
Parameters
----------
args : dict
Both keys and values are strings. The dictionary keys and values are:
* model_config: A JSON string containing the model configuration
* model_instance_kind: A string containing model instance kind
* model_instance_device_id: A string containing model instance device ID
* model_repository: Model repository path
* model_version: Model version
* model_name: Model name
"""
#你的初始化操作代码,initialize函数只在模型加载的时候调用1次
def execute(self, requests):
"""`execute` must be implemented in every Python model. `execute`
function receives a list of pb_utils.InferenceRequest as the only
argument. This function is called when an inference is requested
for this model. Depending on the batching configuration (e.g. Dynamic
Batching) used, `requests` may contain multiple requests. Every
Python model, must create one pb_utils.InferenceResponse for every
pb_utils.InferenceRequest in `requests`. If there is an error, you can
set the error argument when creating a pb_utils.InferenceResponse.
Parameters
----------
requests : list
A list of pb_utils.InferenceRequest
Returns
-------
list
A list of pb_utils.InferenceResponse. The length of this list must
be the same as `requests`
"""
#你的前处理代码,每次预测调用均会调用execute函数
#FastDeploy提供了部分模型的python前后处理函数,无须用户编写
#调用方式为fd.vision.detection.YOLOv5.preprocess(data)
#用户也可以自行编写需要的处理逻辑
def finalize(self):
"""`finalize` is called only once when the model is being unloaded.
Implementing `finalize` function is optional. This function allows
the model to perform any necessary clean ups before exit.
"""
#你的析构代码,finalize只在模型卸载的时候被调用1次
initialize中一般放置初始化的一些操作,该函数只在Python-Triton-Model被加载的时候执行1次。
finalize中一般放置一些析构释放的操作,该函数只在Python-Triton-Model被卸载的时候执行1次。
execute中放置用户需要的前后处理的逻辑,该函数在每次服务端收到客户端请求的时候被执行1次。
execute函数的输入参数requests为InferenceRequest的集合,在没有开启动态合并Batch功能时候,requests的长度是1,即只有1个InferenceRequest。
execute函数的返回参数responses必须是InferenceResponse的集合,通常情况下长度与requests的长度一致,即有N个InferenceRequest就必须返回N个InferenceResponse。
用户可以在execute函数中自行编写Python代码进行数据前处理或后处理,为了方便用户,FastDeploy提供了部分模型的python前后处理函数,使用方式如下:
import fastdeploy as fd
fd.vision.detection.YOLOv5.preprocess(data)
动态合并Batch功能
动态合并Batch的原理如下图所示。当用户请求request并发量较大,但GPU利用率较小时,可以通过将不同用户的request组合为1个大的Batch进行模型预测,从而提高服务的吞吐性能。
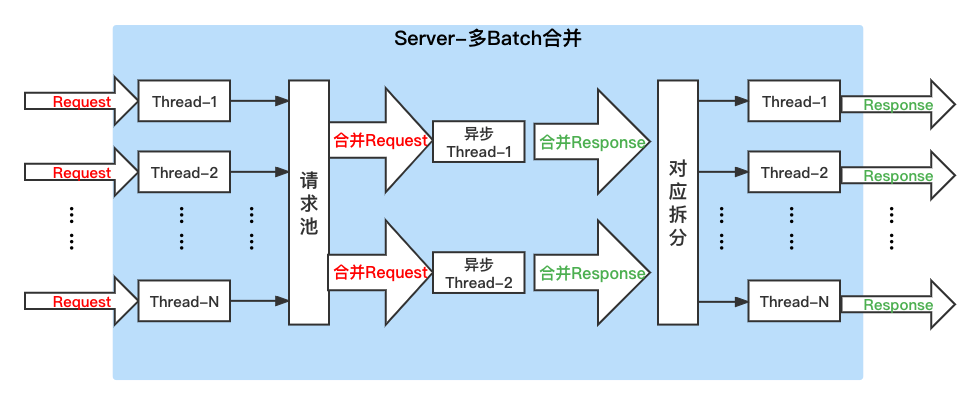
开启动态合并Batch功能非常简单,仅需在config.pbtxt结尾处,增加dynamic_batching{}字段即可。
注意:ensemble_scheduling字段与dynamic_batching字段不可共存,即对于Ensemble-Triton-Model不存在动态合并Batch功能,这也可以理解,因为Ensemble-Triton-Model本身仅仅是多个Triton-Model的组合。
多模型实例
多模型实例的原理如下图所示。当前后处理(通常不支持Batch)成为整个服务的性能瓶颈时,能通过增加多个前后处理的Python-Triton-Model实例,来提高整个服务的时延性能。
当然也可以开启多个Runtime-Triton-Model模型实例,来提升GPU利用率。

设置多模式实例的方法很简单,如下所示。
instance_group [
{
count: 3
kind: KIND_CPU
}
]